

对图像可以使用均值滤波器进行降噪。
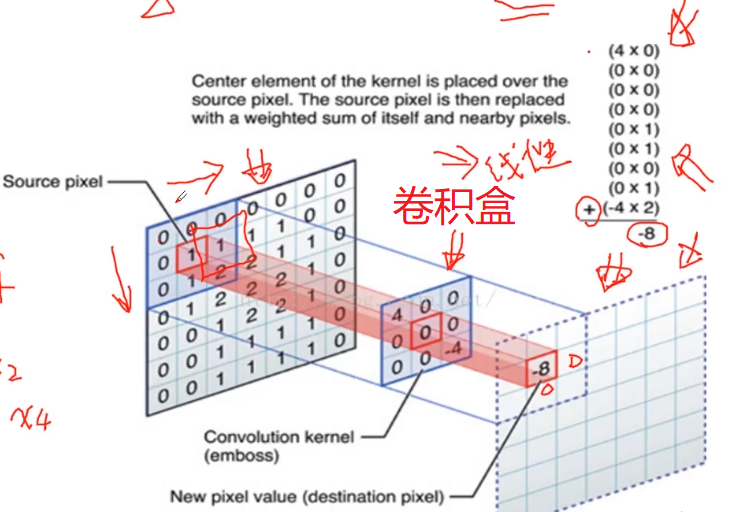


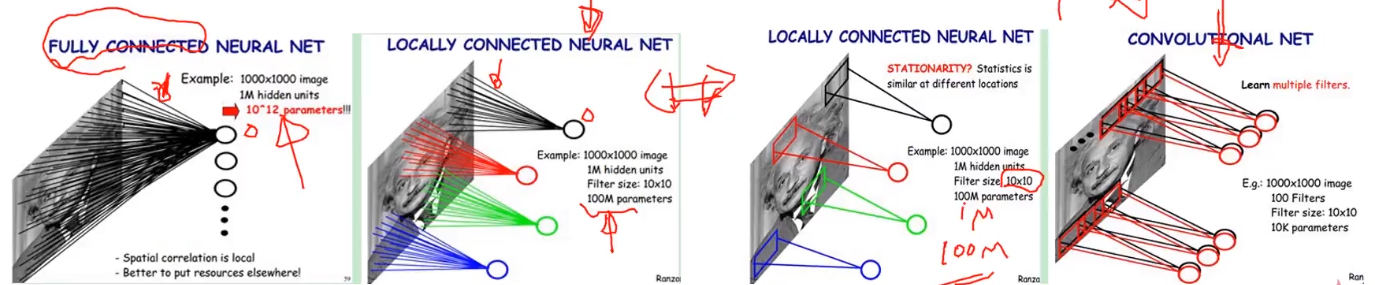
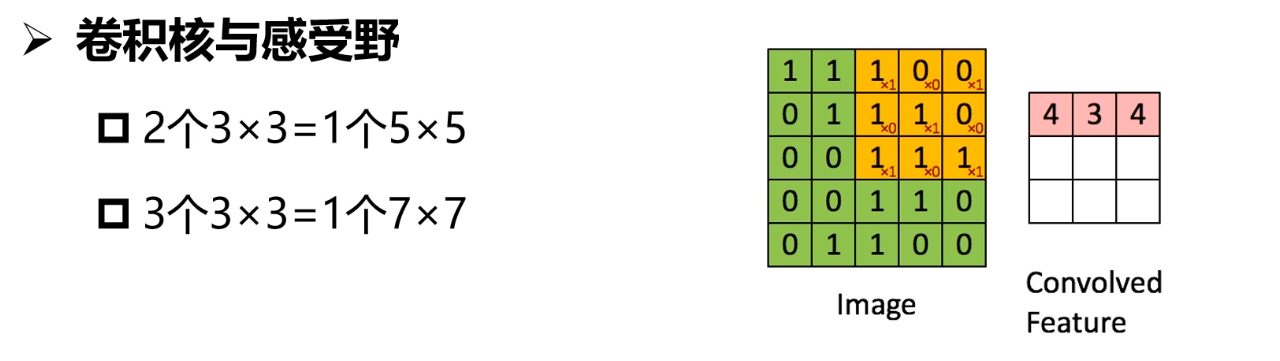
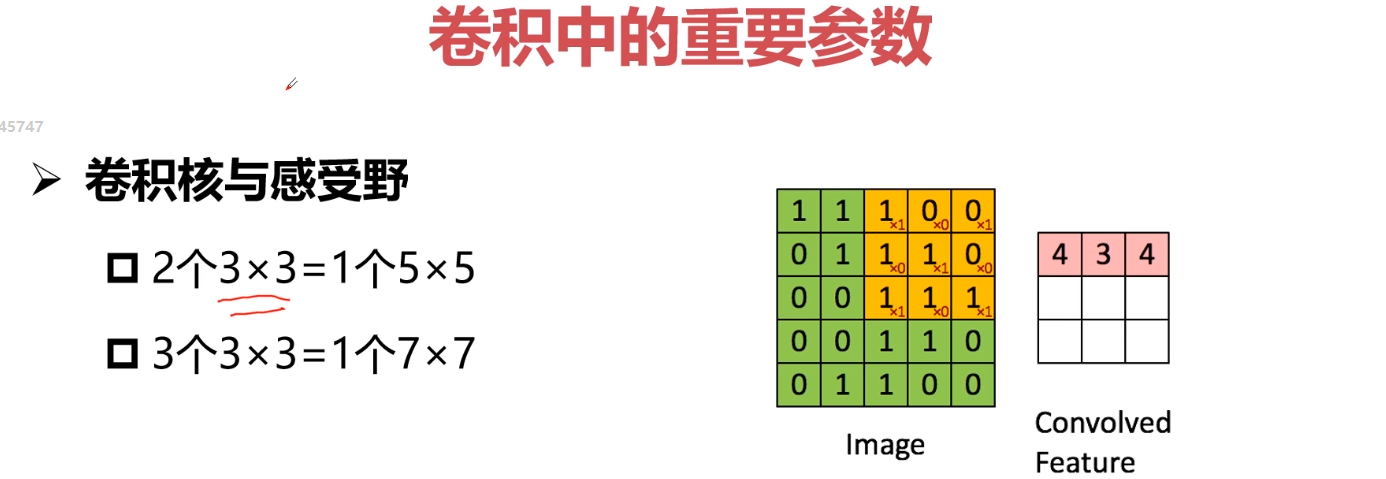
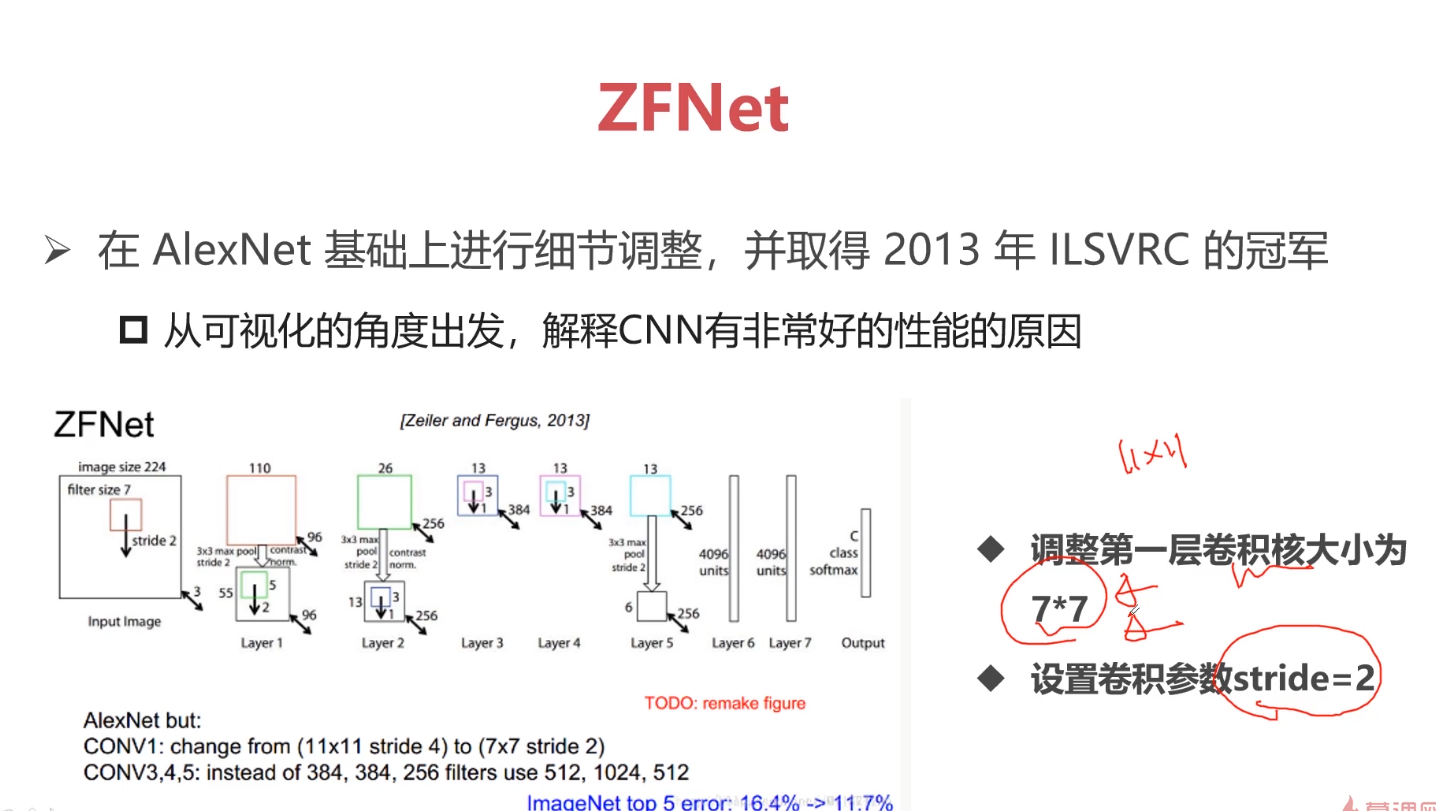
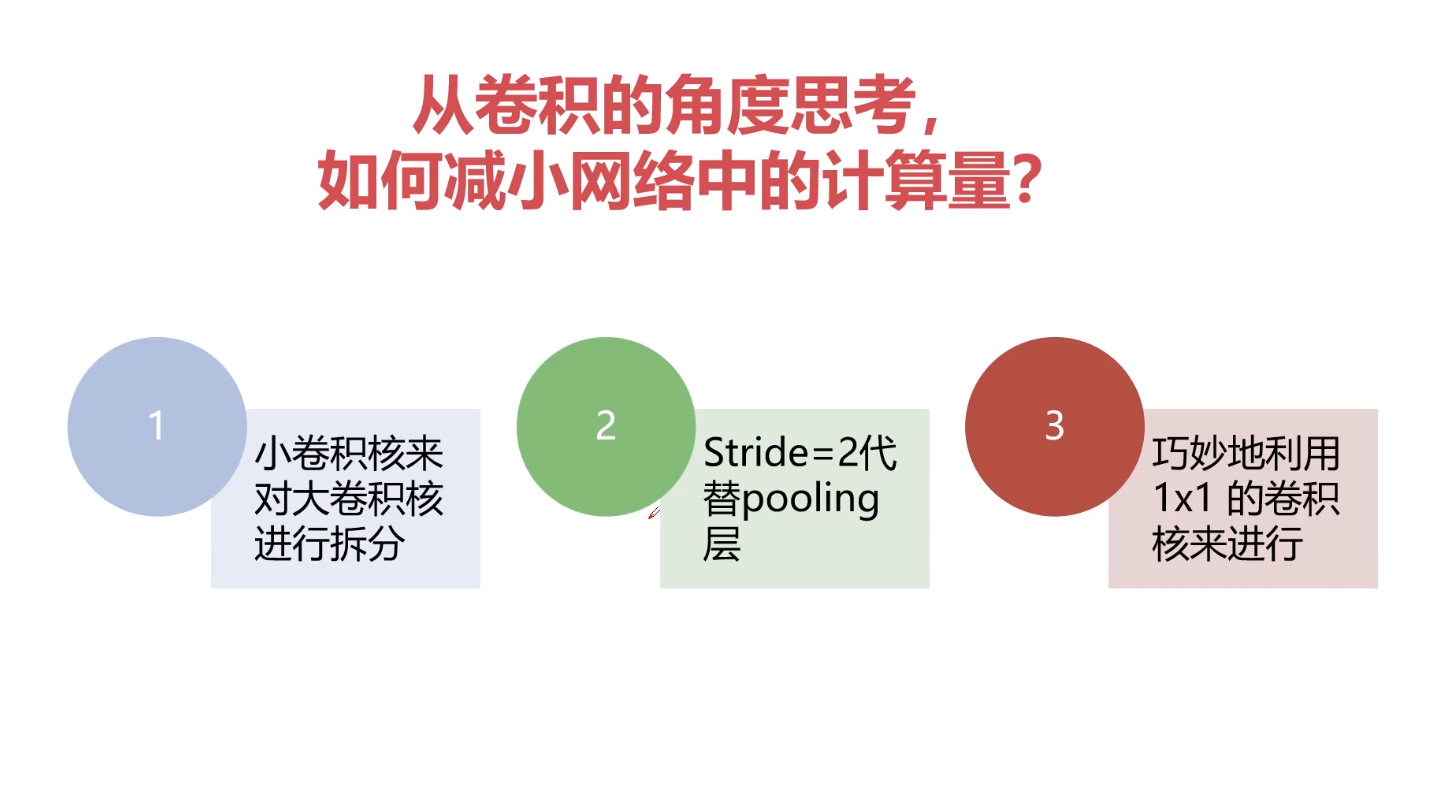
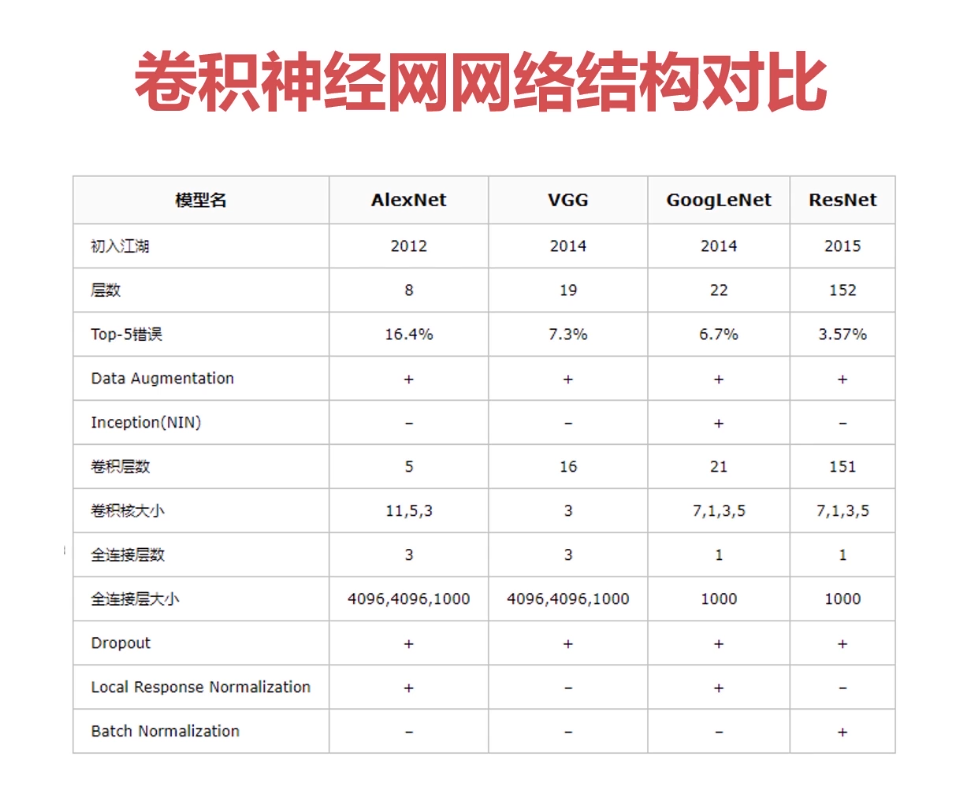
卷积核越大意味着感受野越大,也就是会感受到更多的信息、学习导更多的信息,但是不见得最终学习到的就最好,因为卷积核越大意味着参数两越大。而且计算量会很大。为了能够在小的感受野同样学习得好,采用小卷积核堆加完成大的感受野得操作。一般采用小卷积核代替大卷积核得方式。

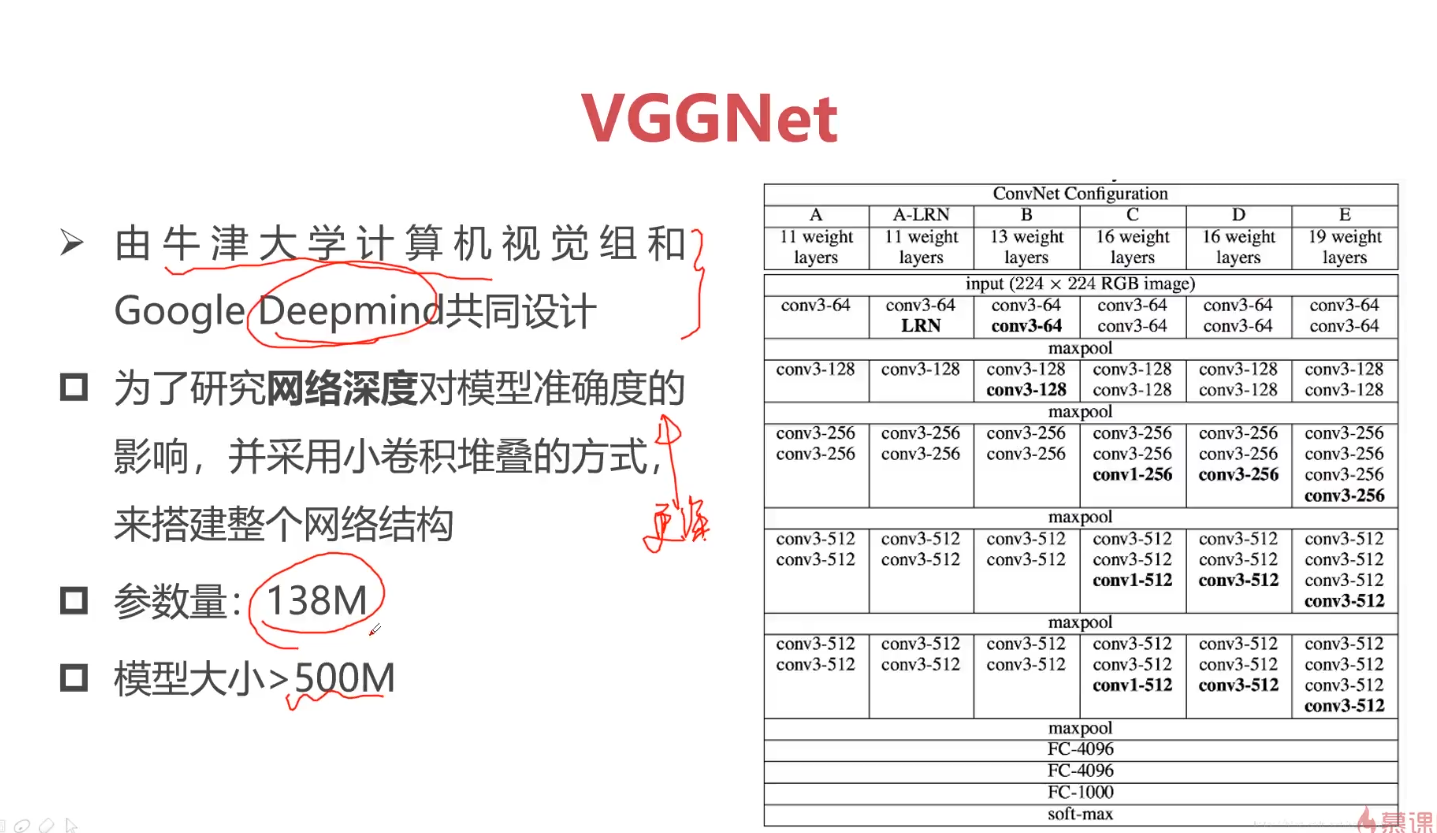
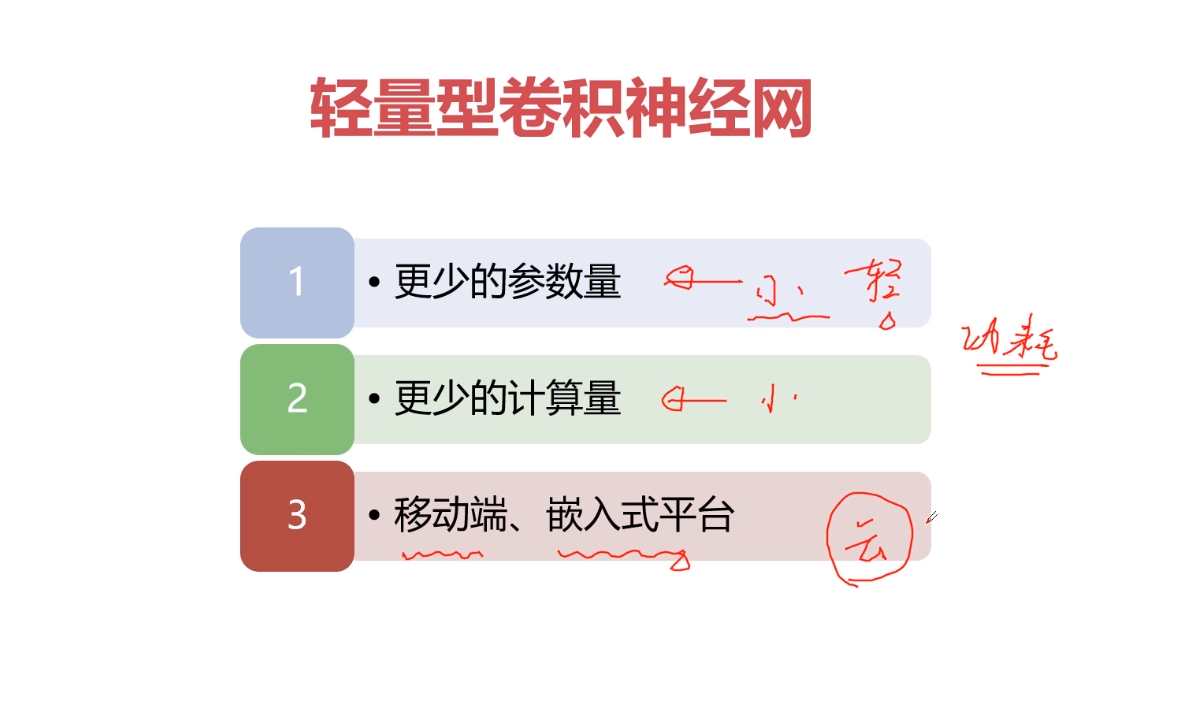
训练出来得模型通常包括两部分内容:网络结构 & 参数; 参数量大的话模型会非常大,参数两越大,意味着对平台要求越大,因为我们的模型一般运行在内存中或者缓存中,模型越大,存储空间越大。参数越多意味着模型越复杂。
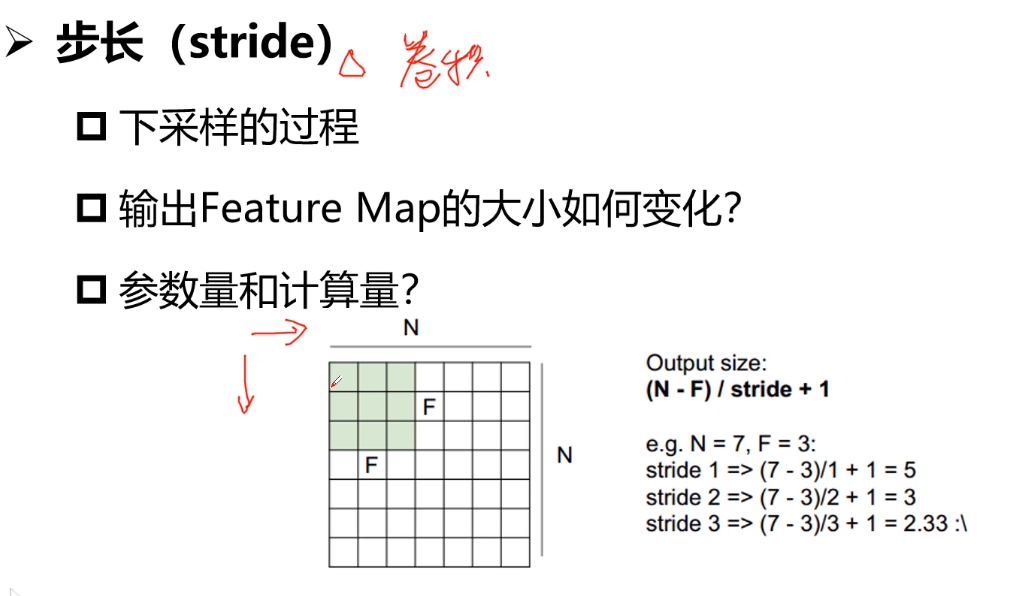

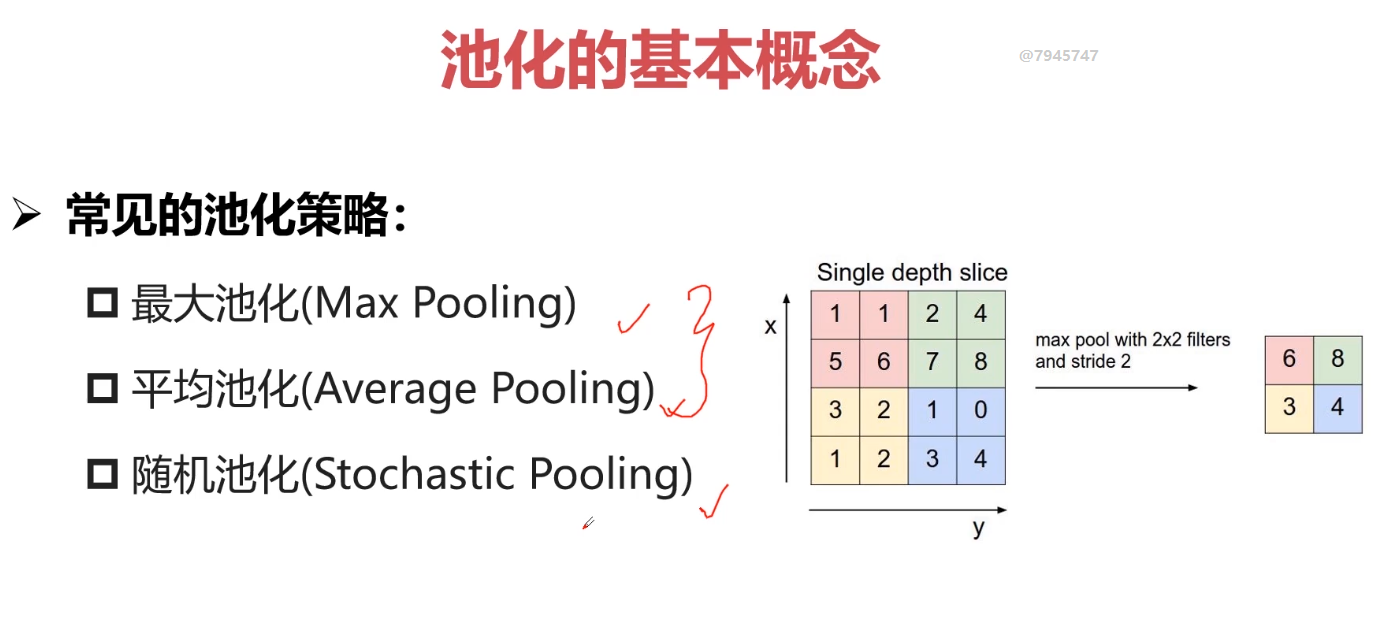




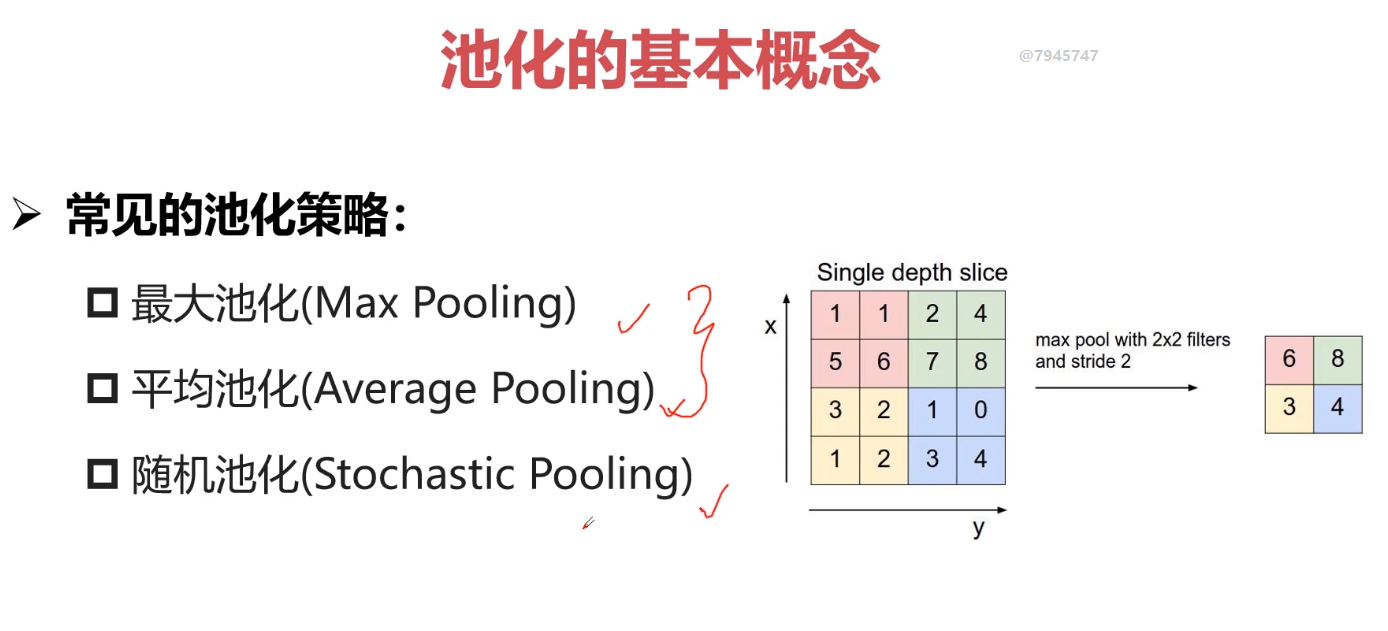


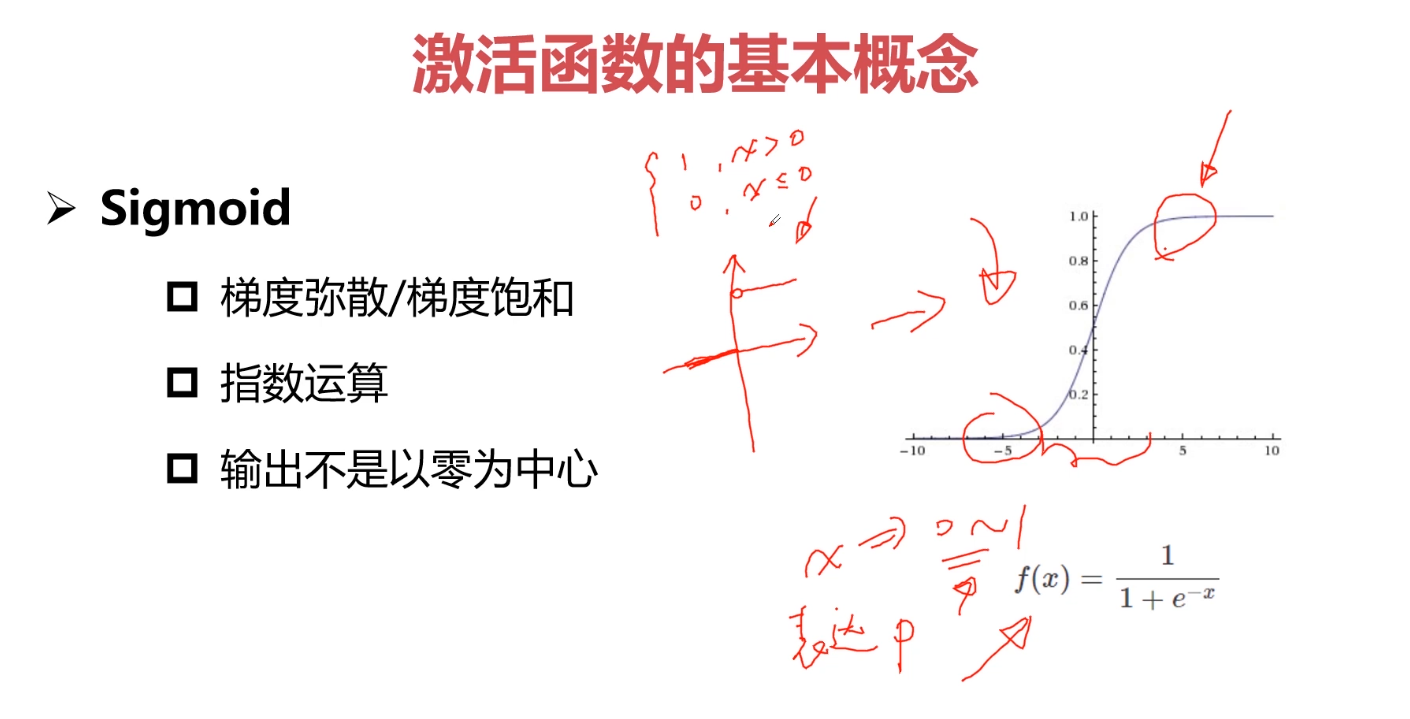
很少将Sigmoid作为网络中间层;往往作为网络输出层。
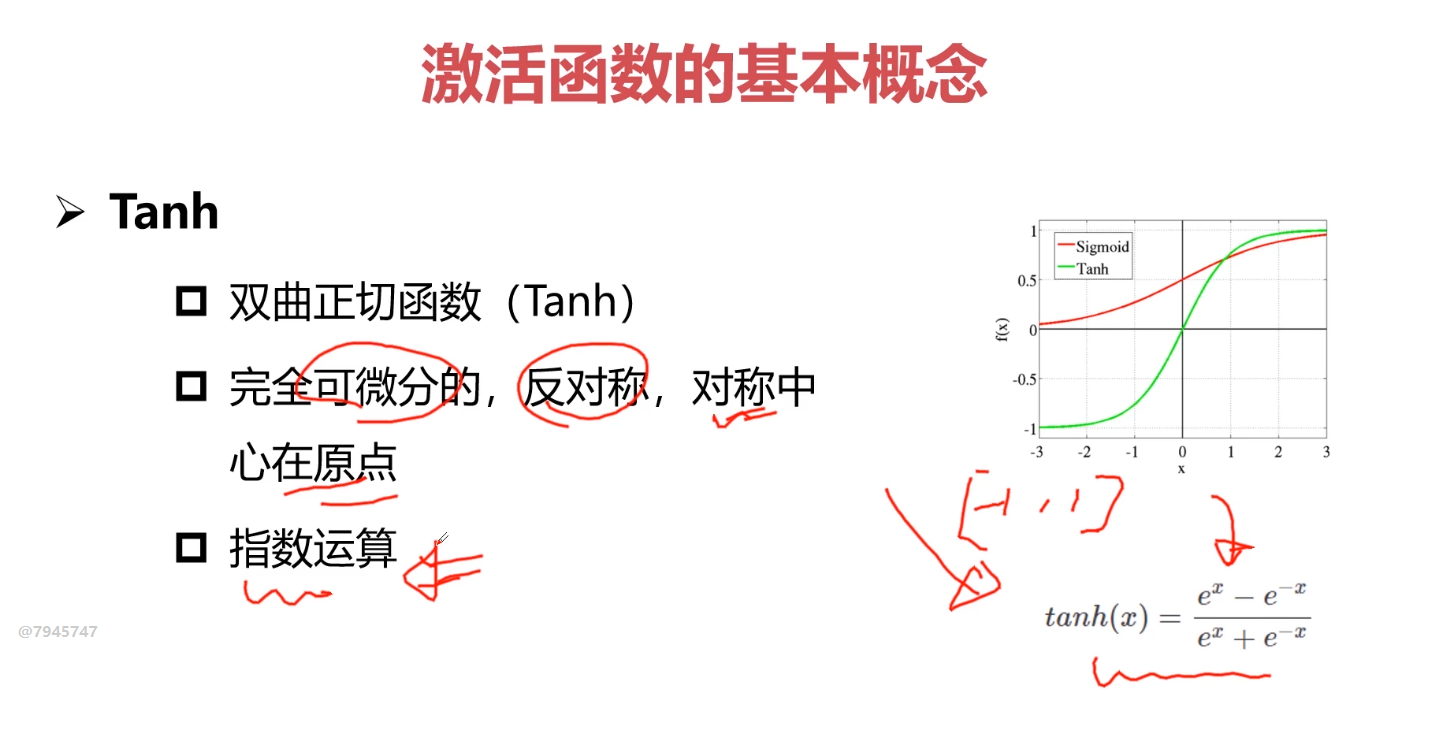
tanh也很少使用

常常使用ReL函数,但是需要注意保持激活。






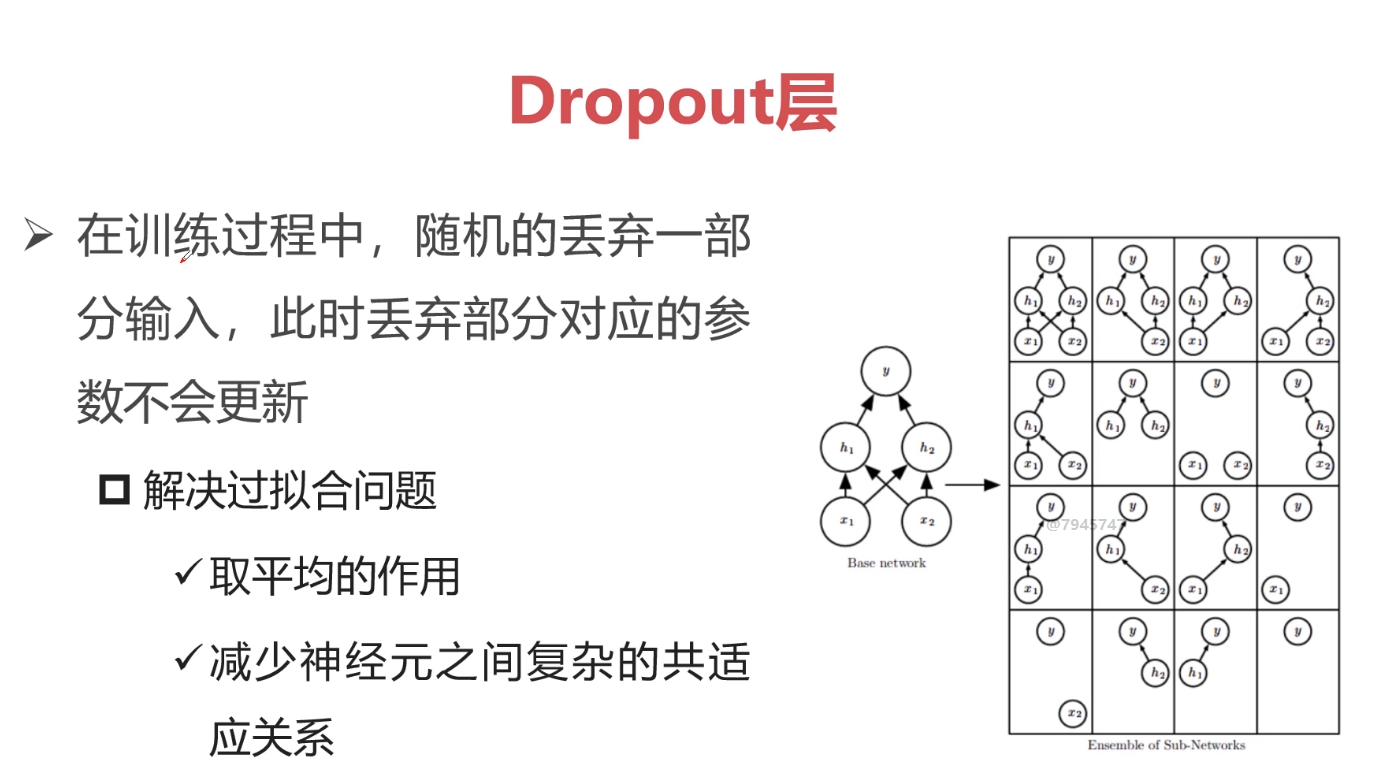



不确定性越大,熵越大。




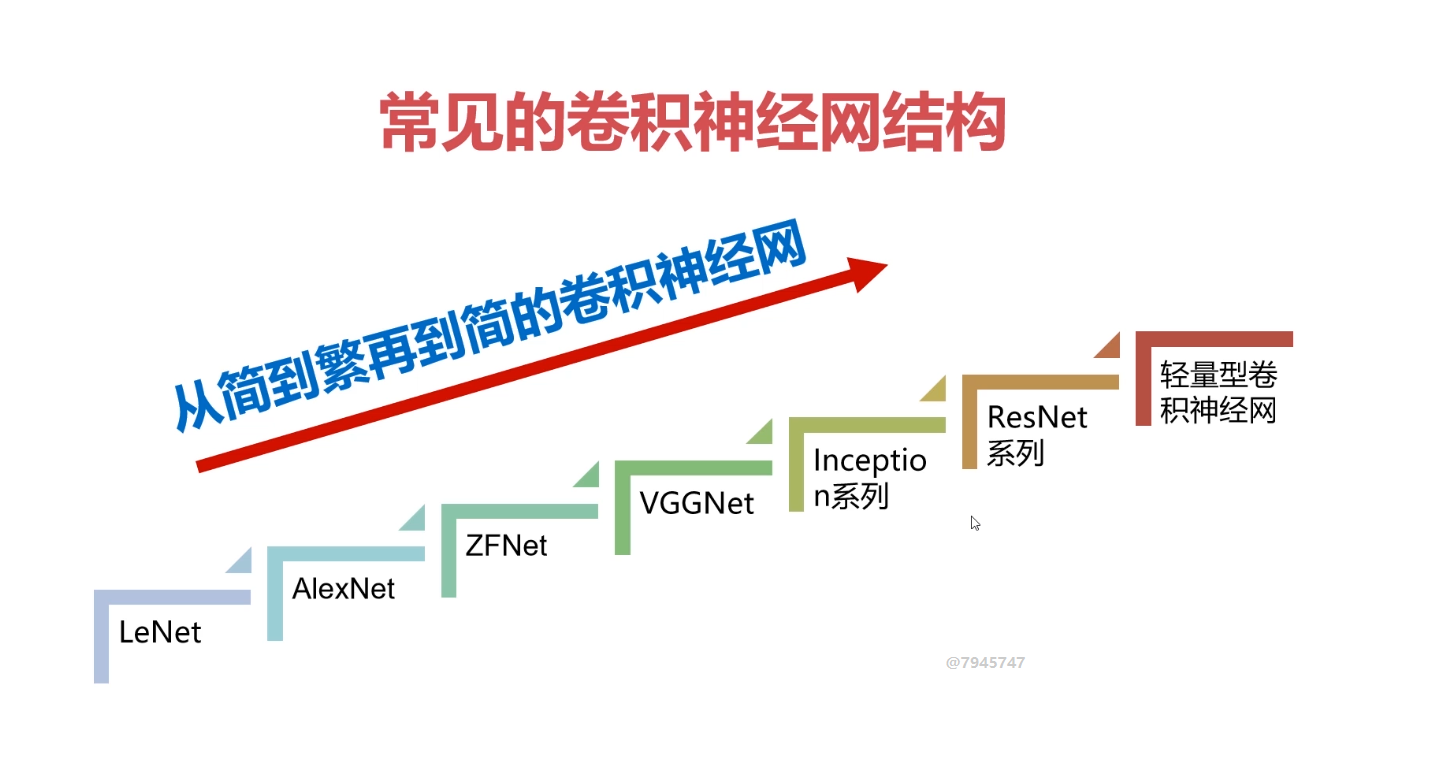









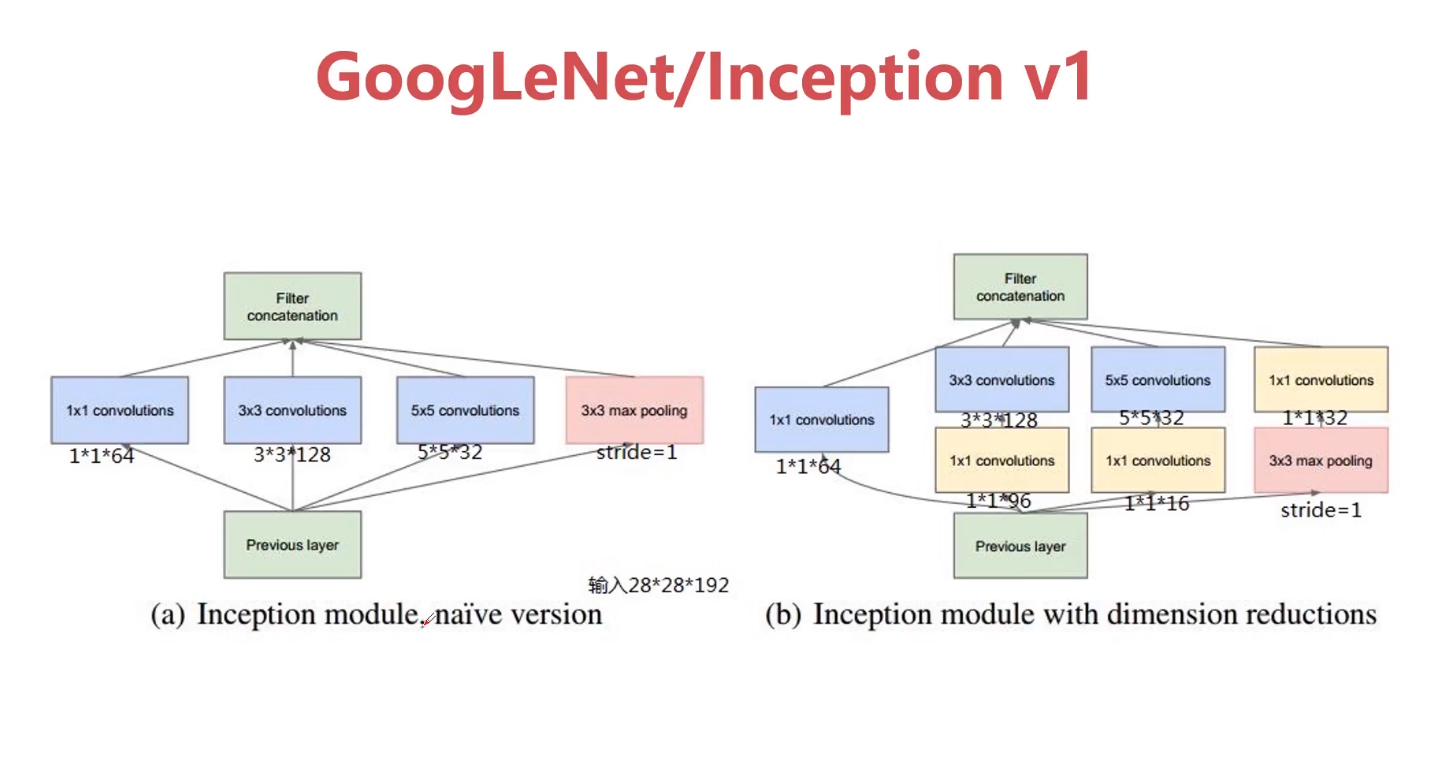

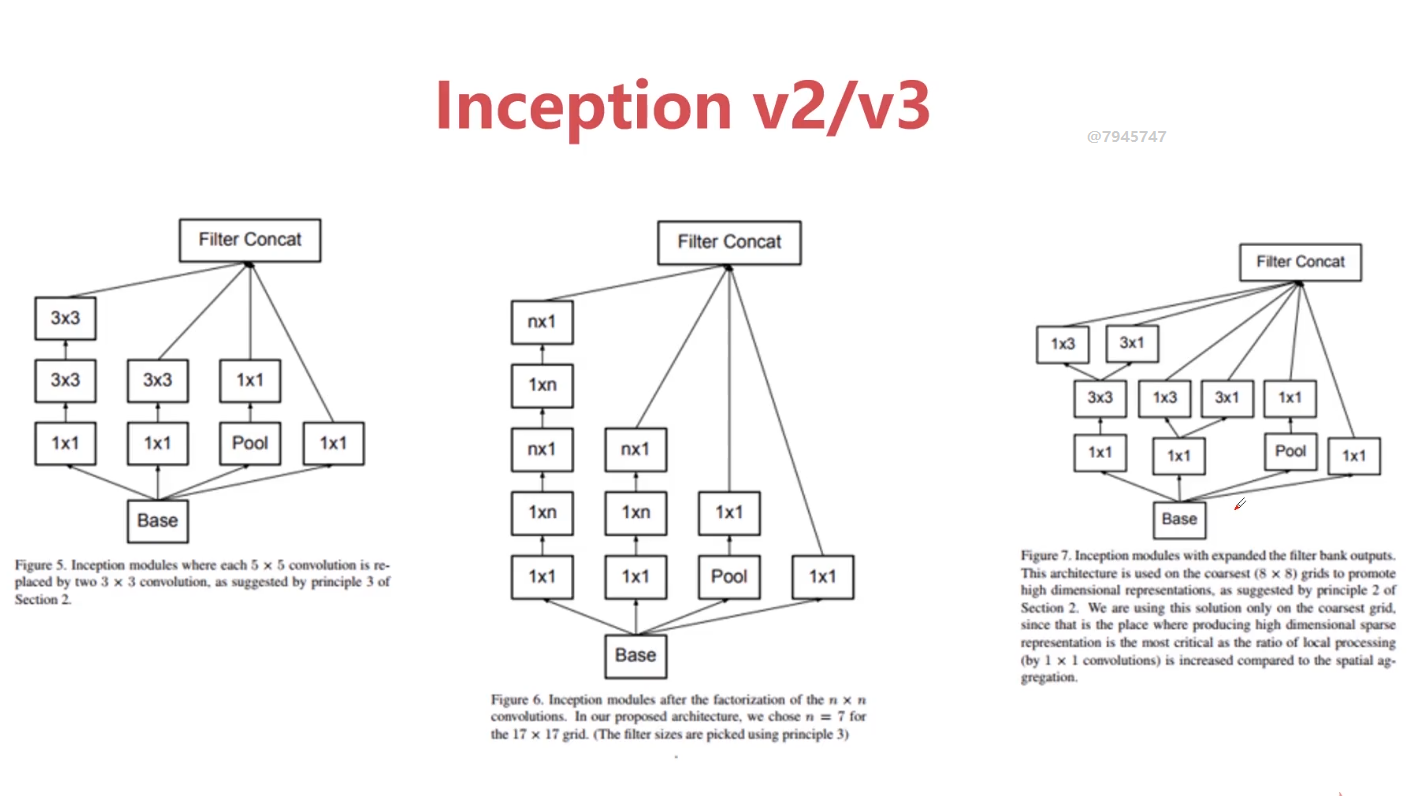
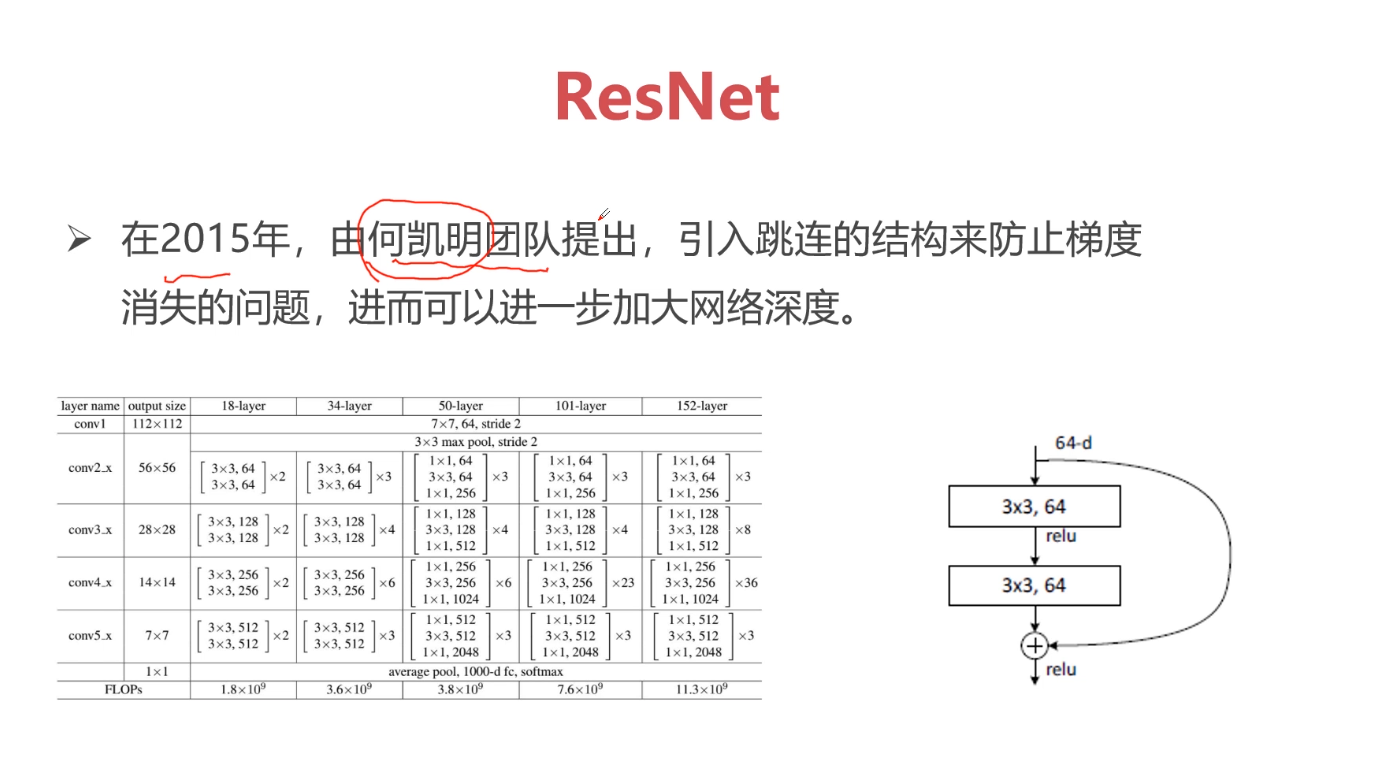
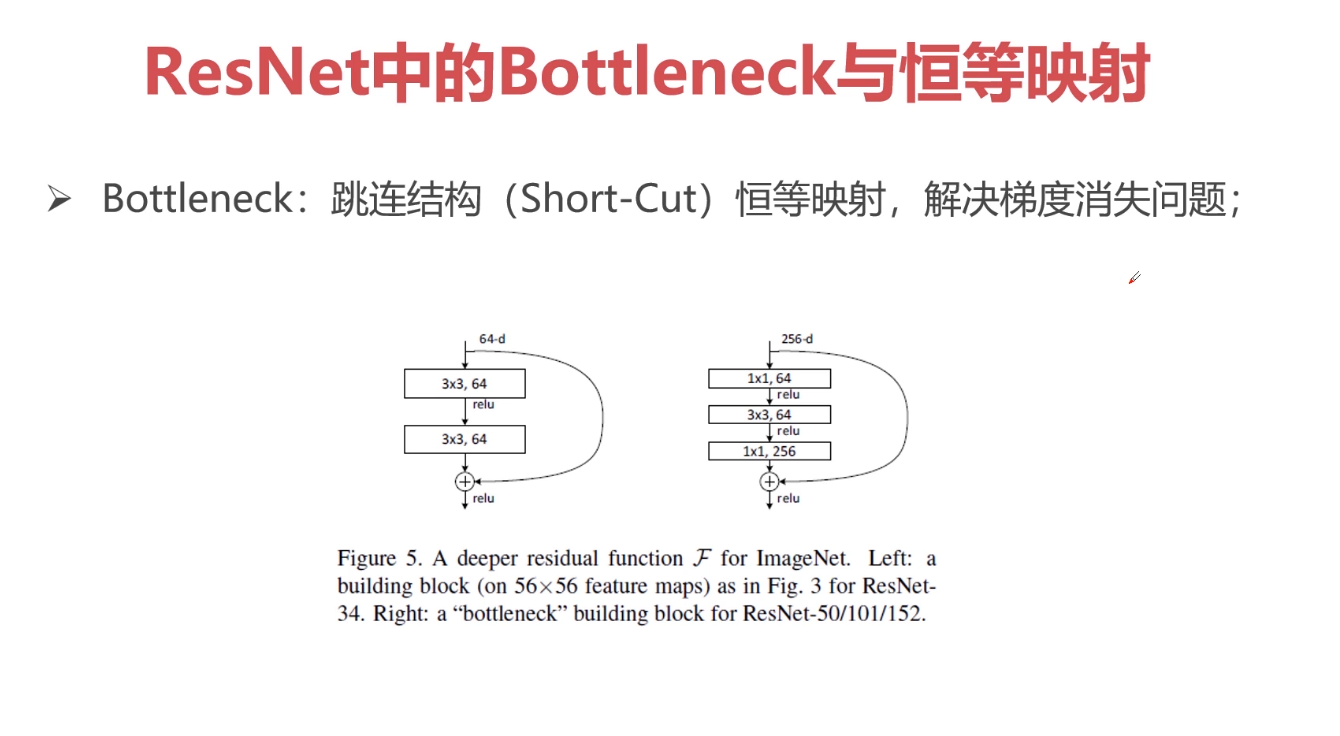
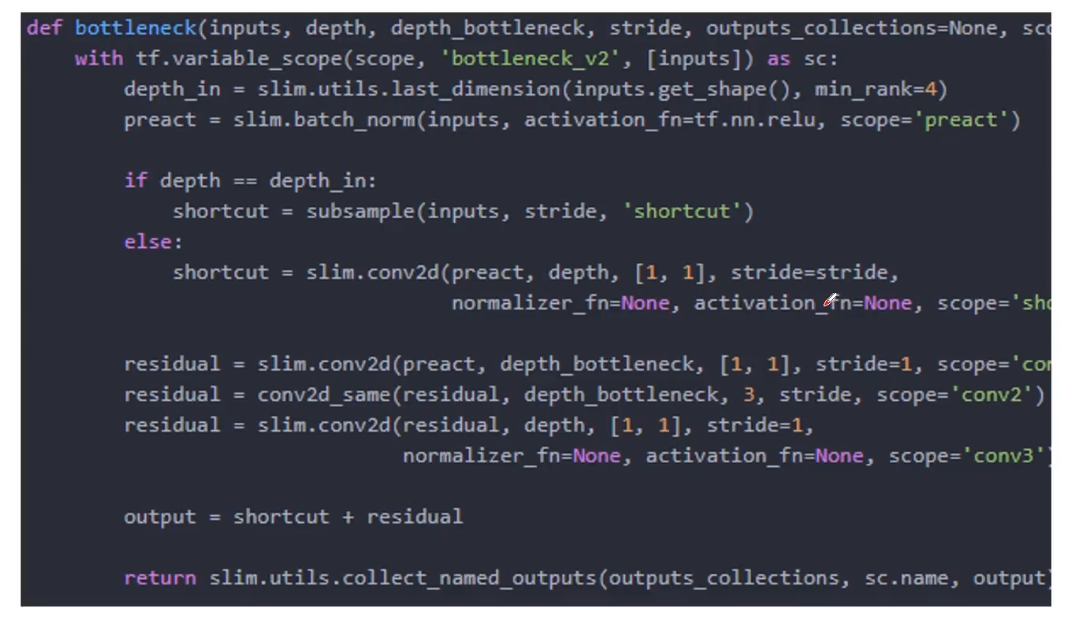
网络越深就能够学到更好的特征,但是VGG网络则相反,这是因为VGG网络伴随着网络的加深,会产生梯度消失的问题,而这恰恰是ResNet所具有的优势,ResNet不会出现梯度消失问题,它通过跳连的结构环节了梯度消失的问题。因为是跳连,所以初始的A节点的位置需要被缓存下来,如果缓存容量小,就会出现缓存容量不够的情况。




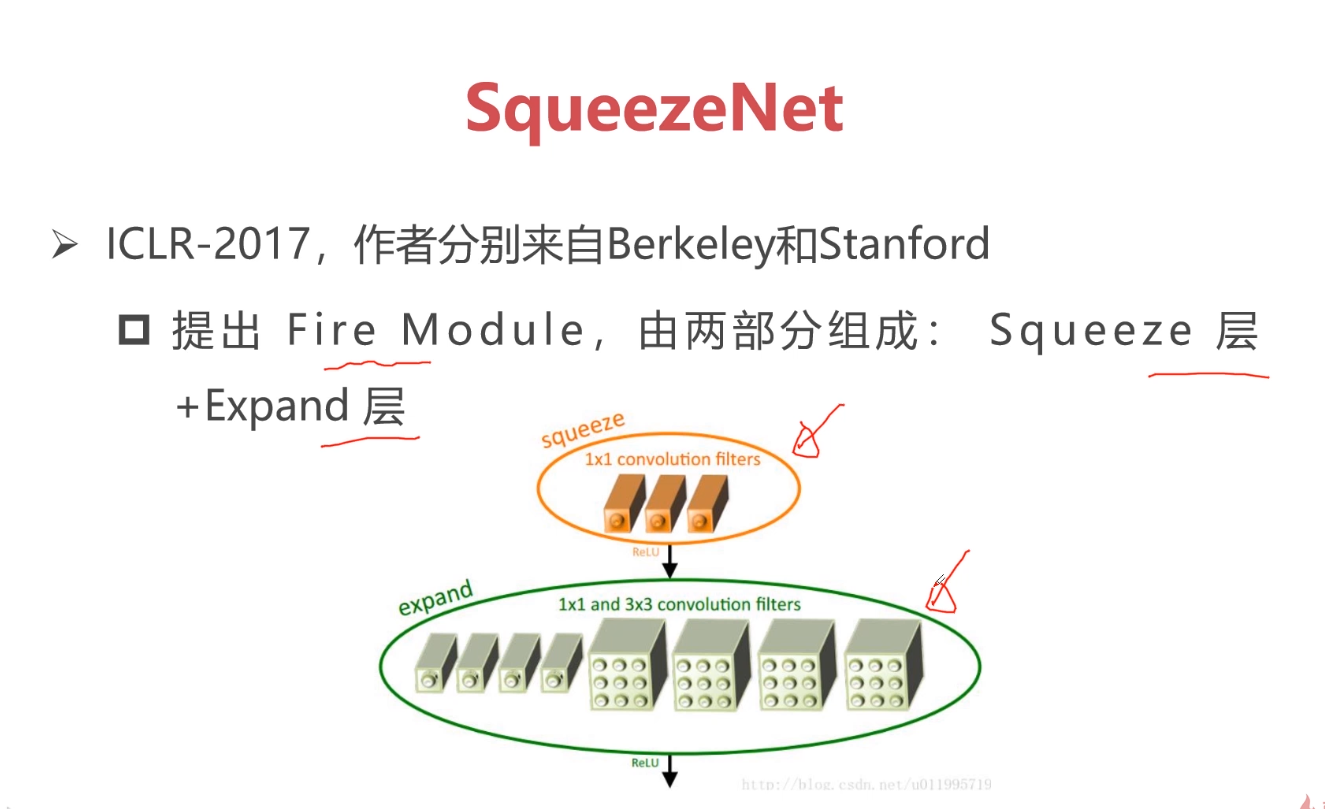



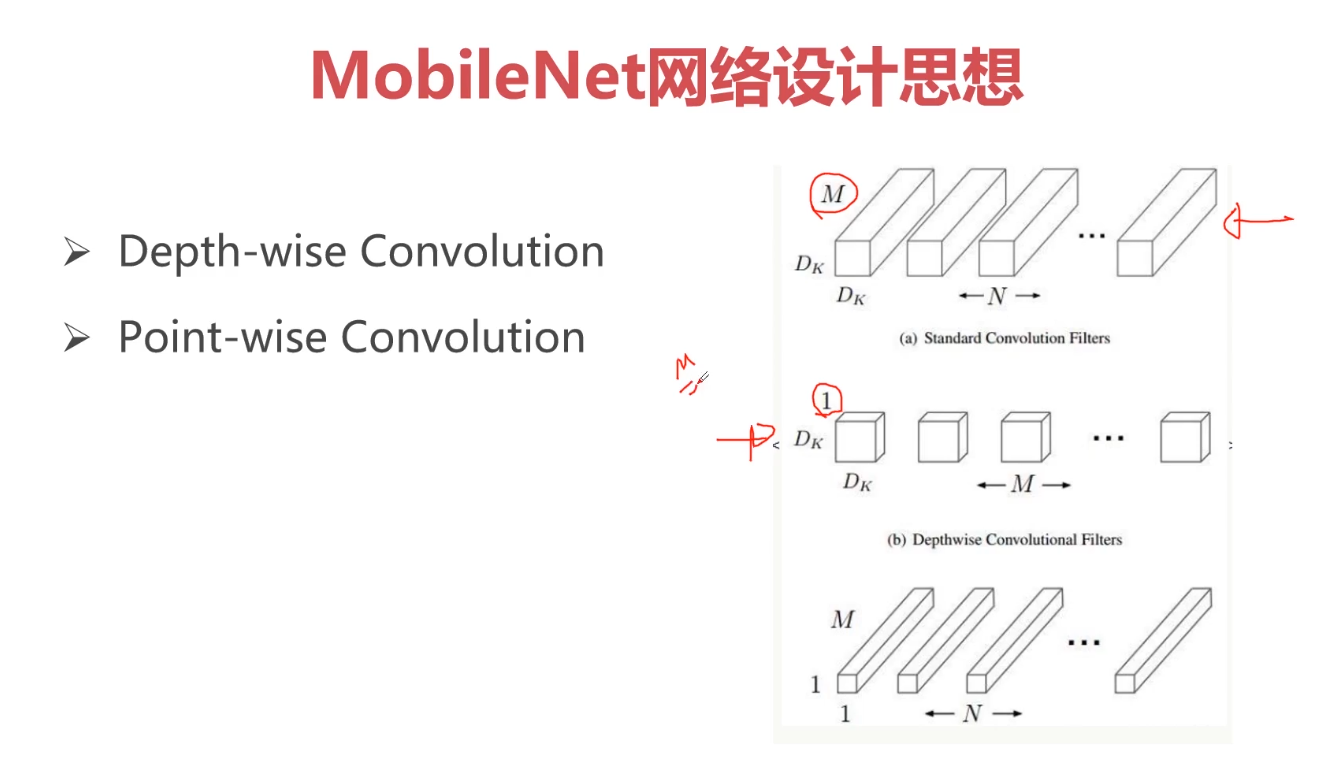

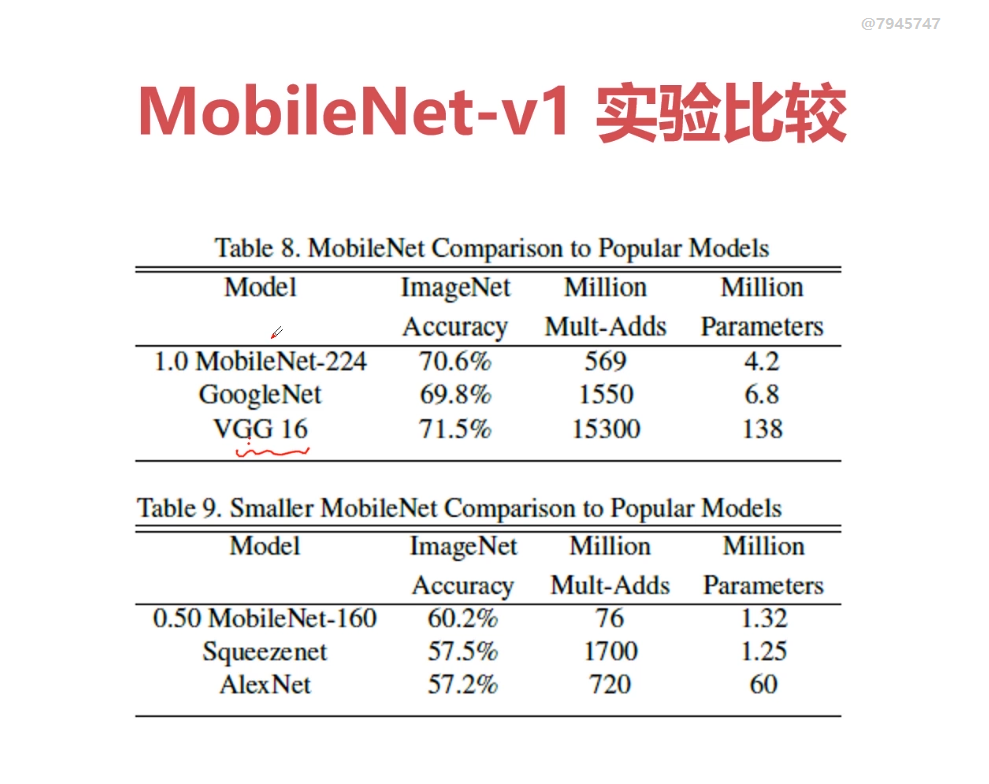
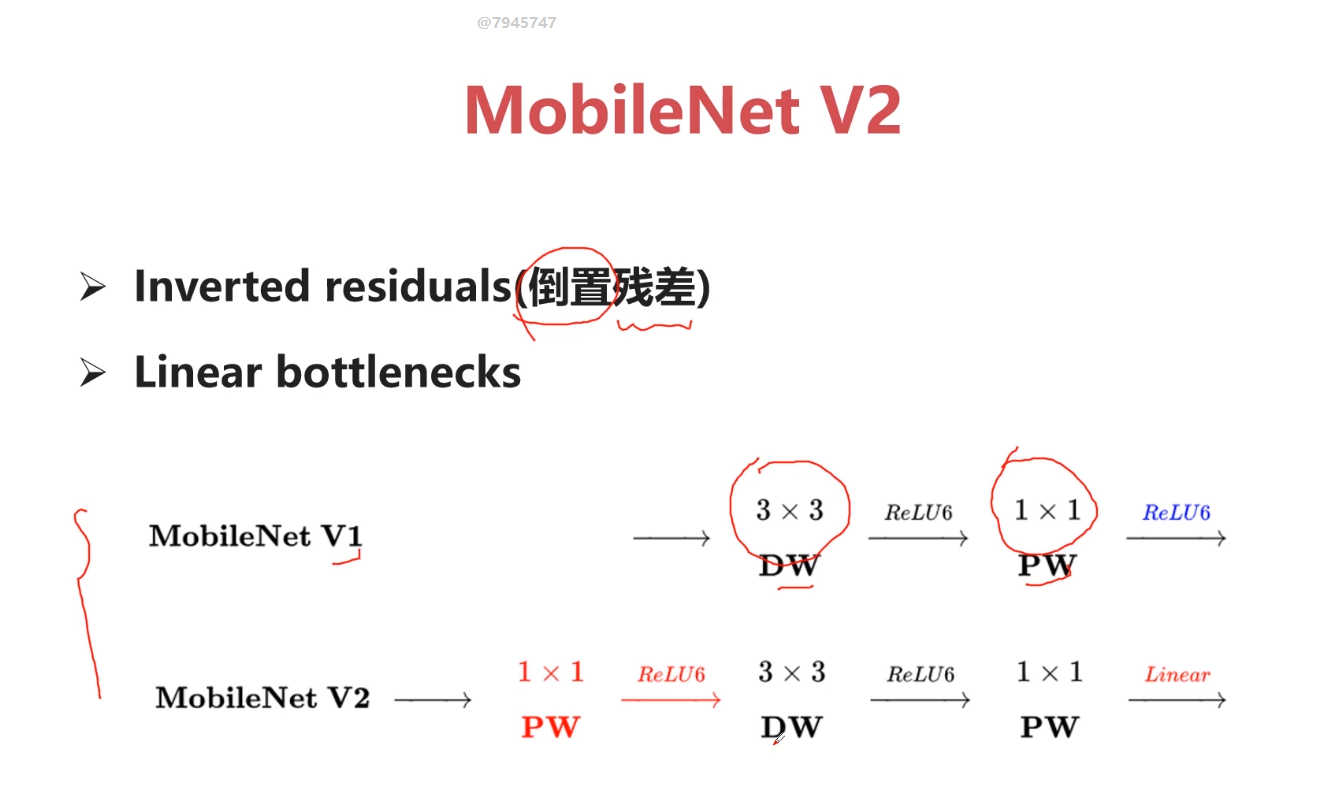











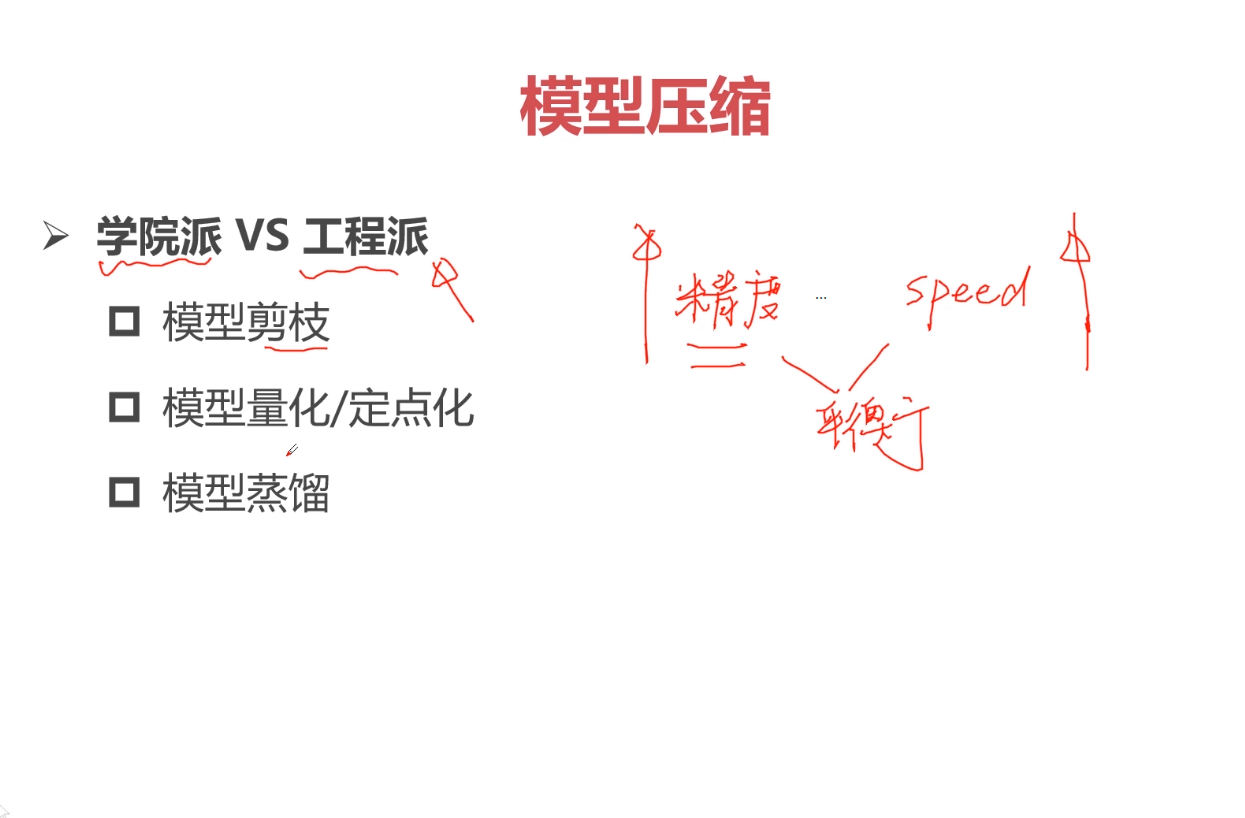



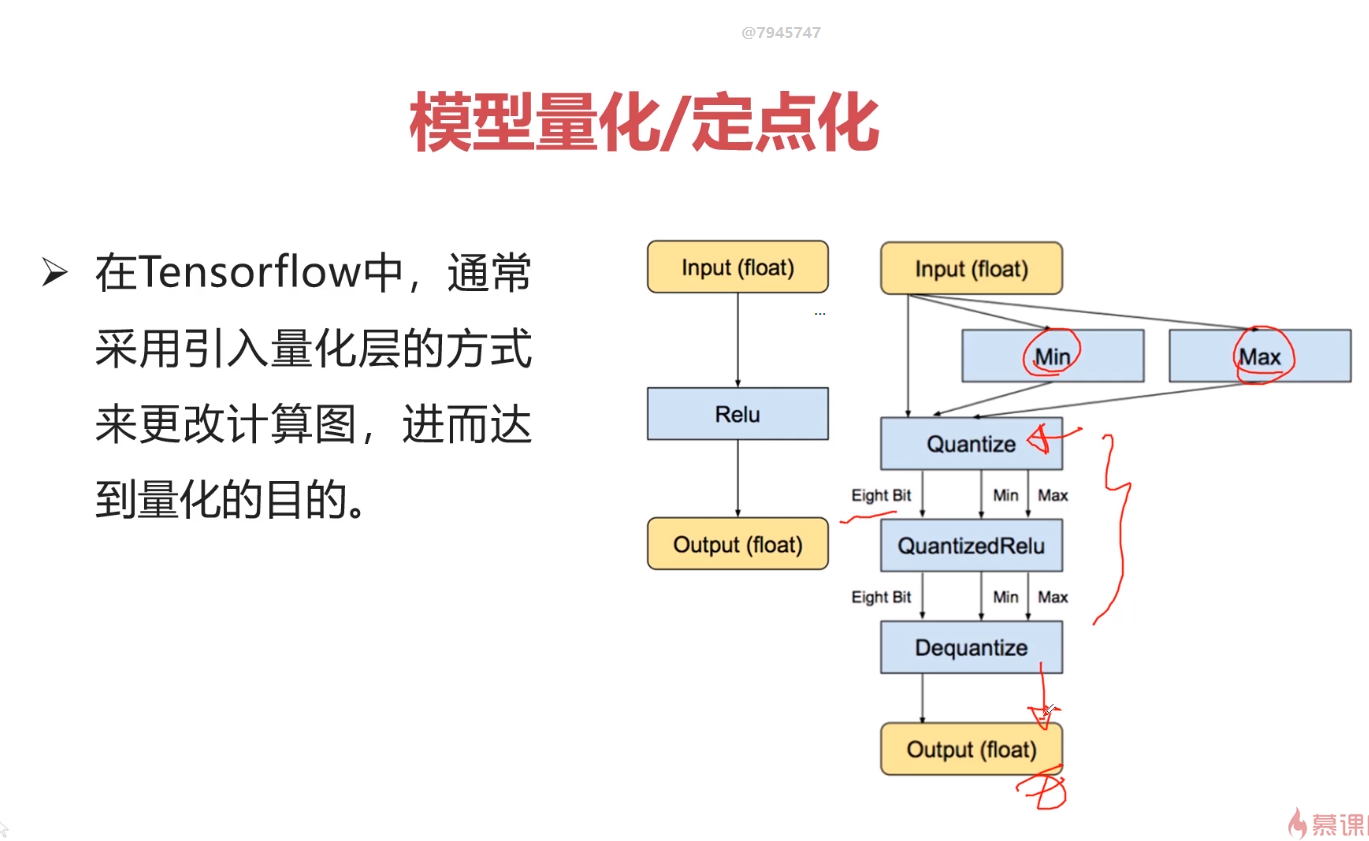
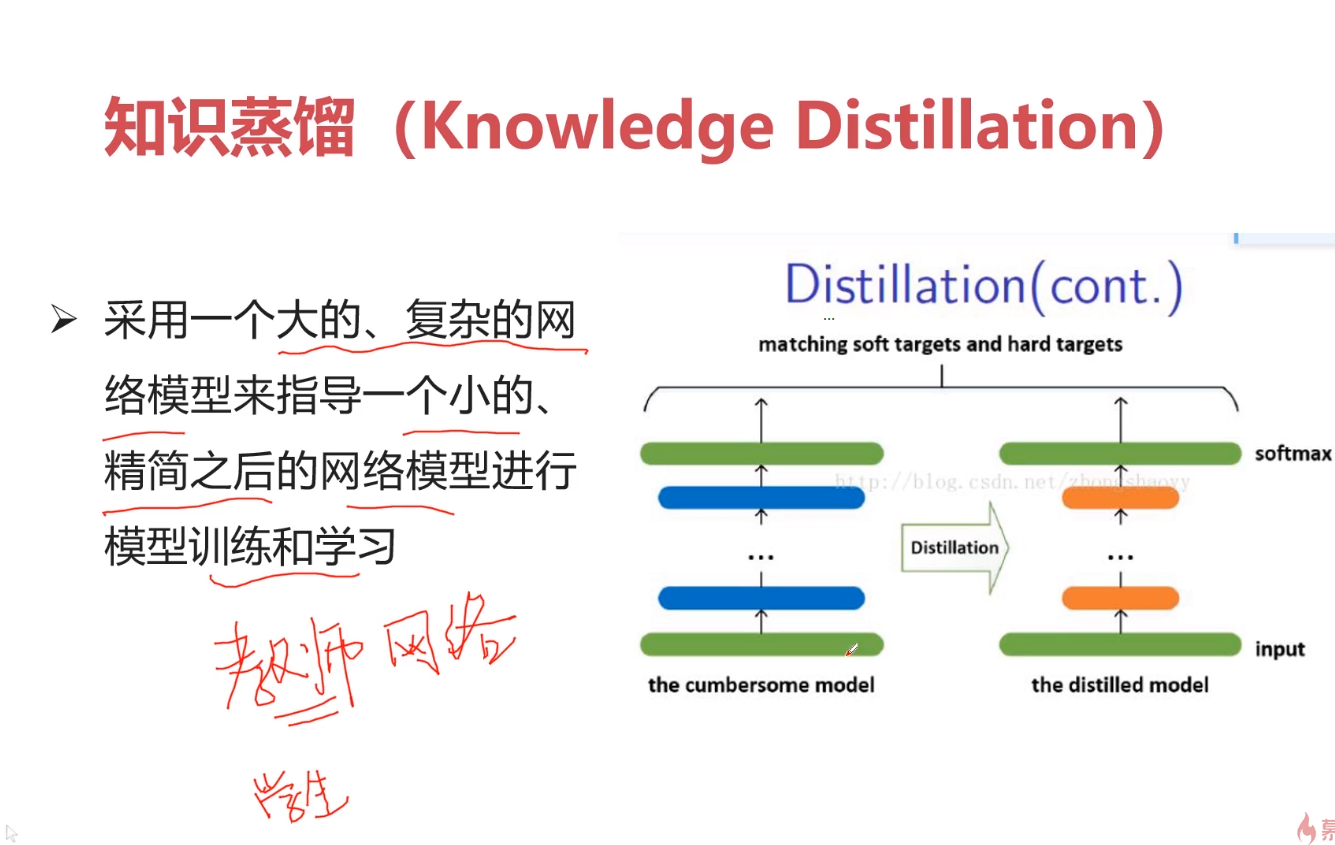
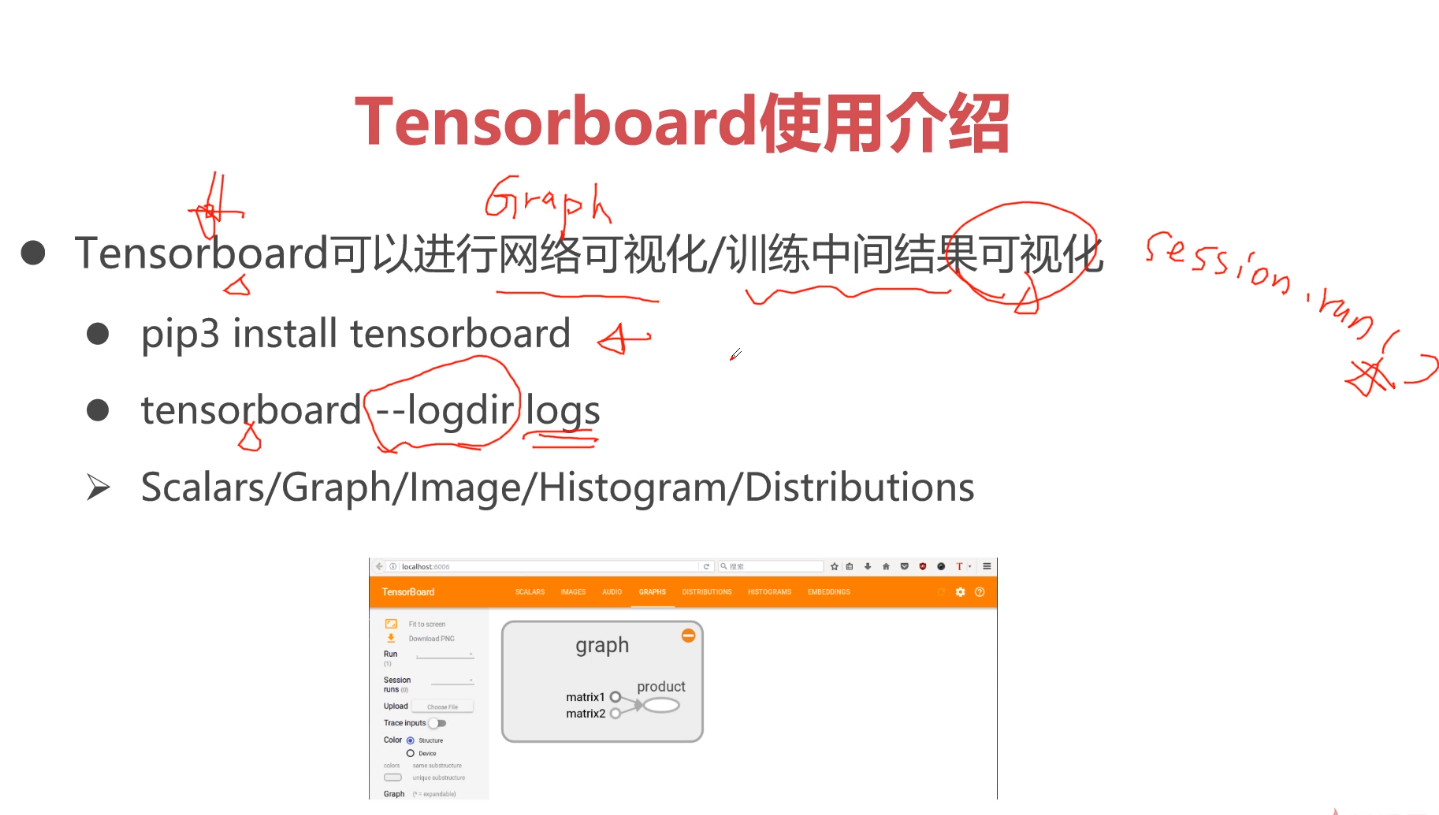
TensorFlow专讲



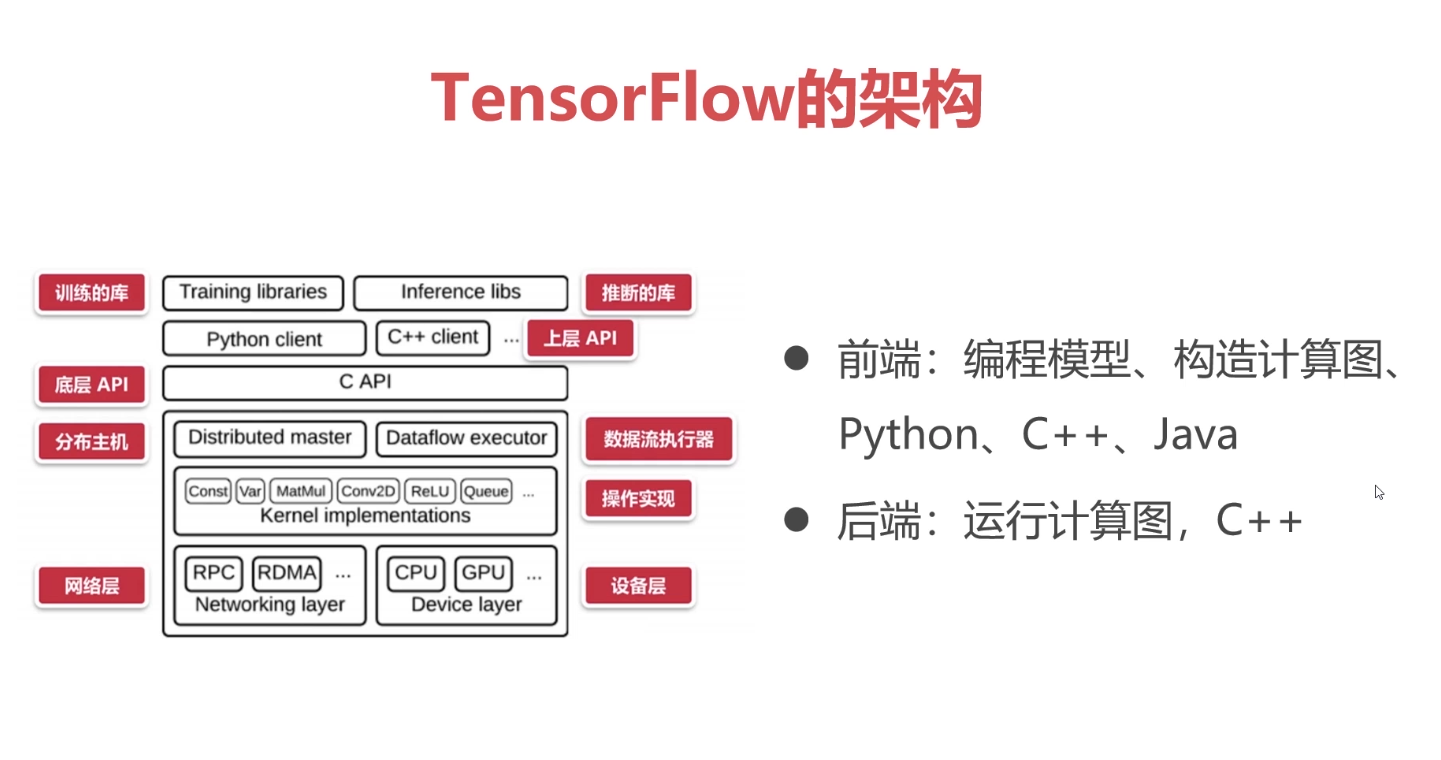







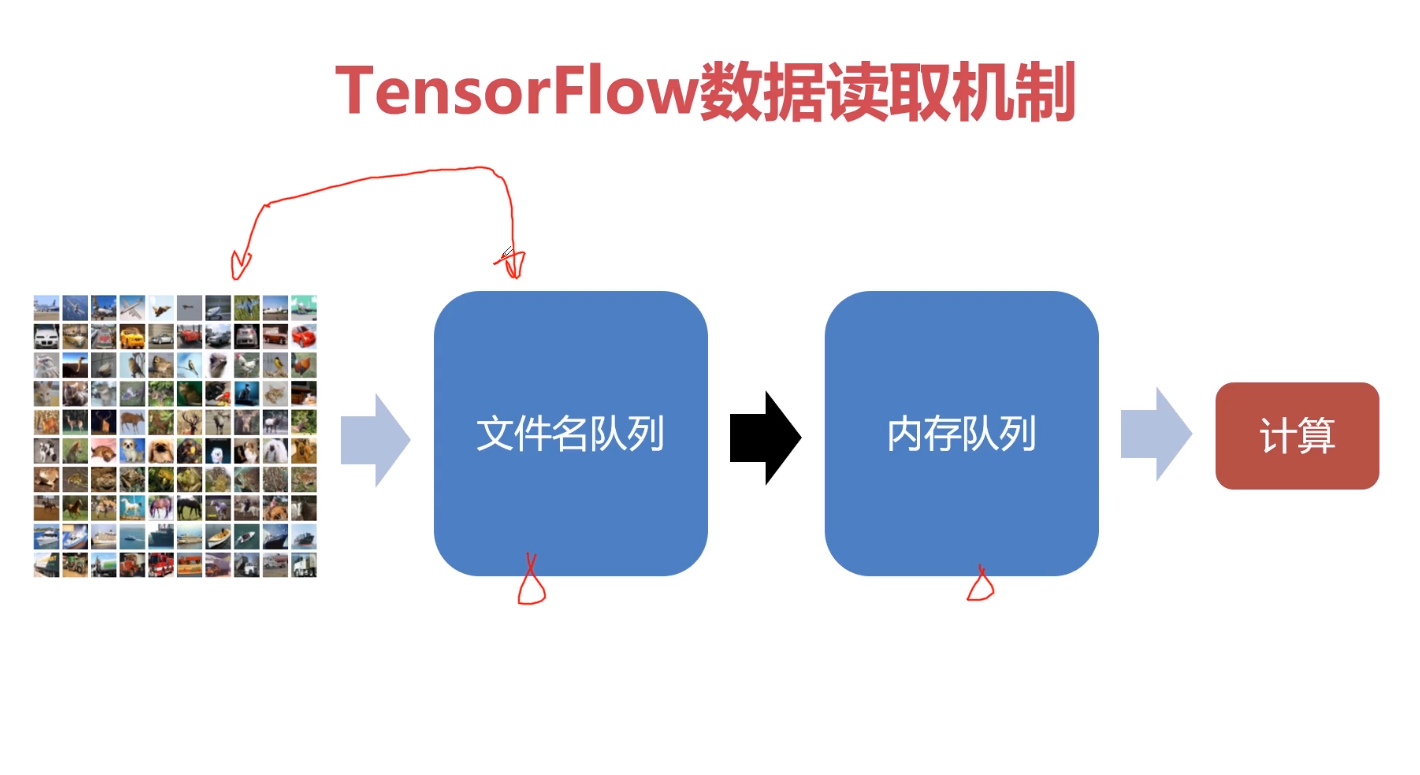
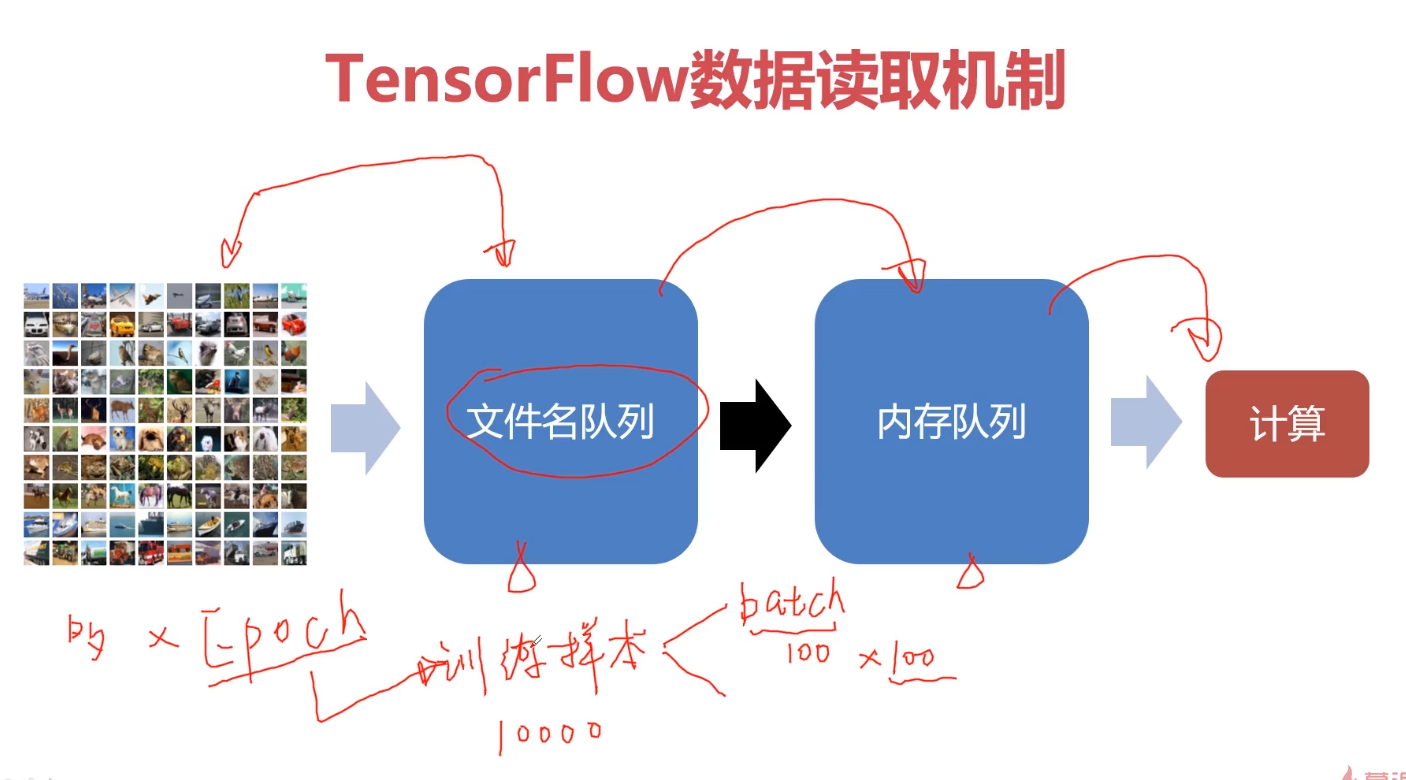

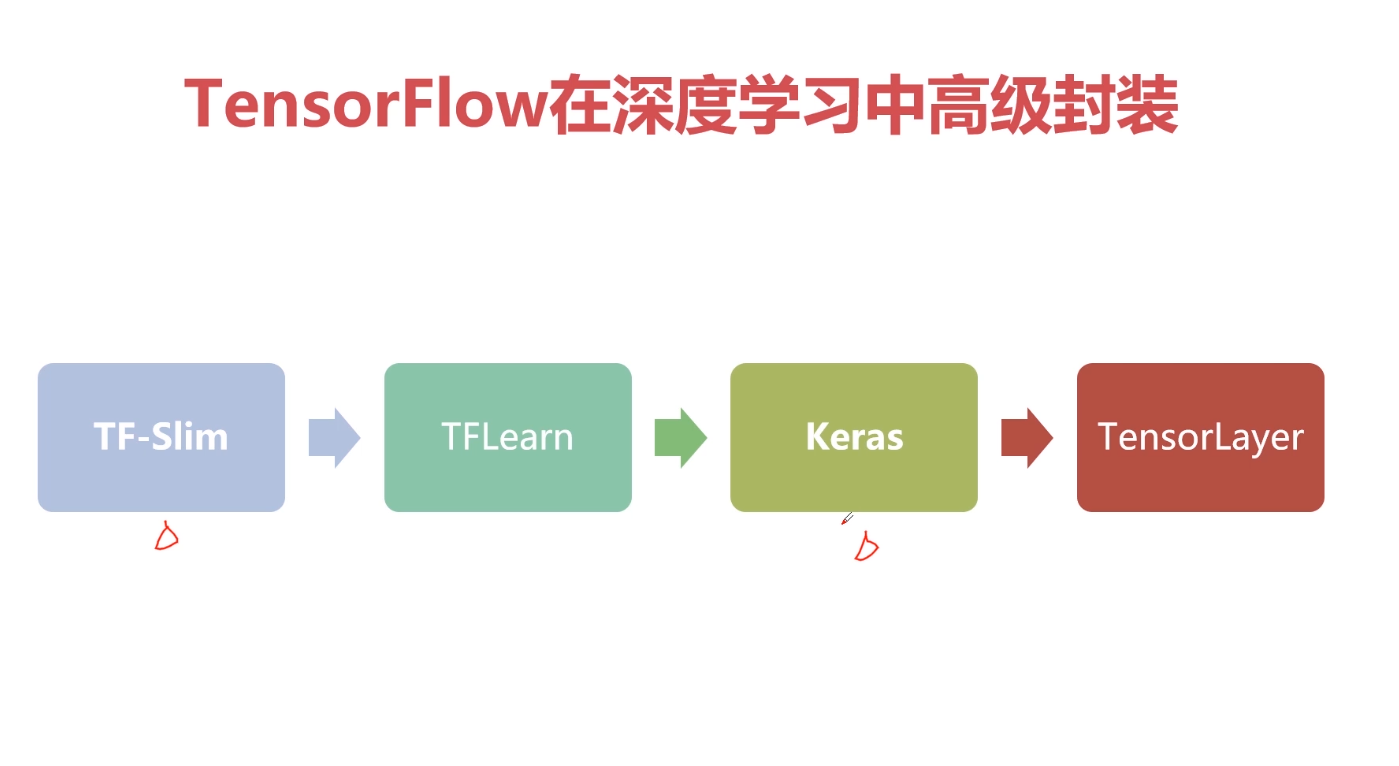




通过参数作用域。可以精简代码,是代码更具可读性。



对于BathNorm层的更新有以下两种方式:










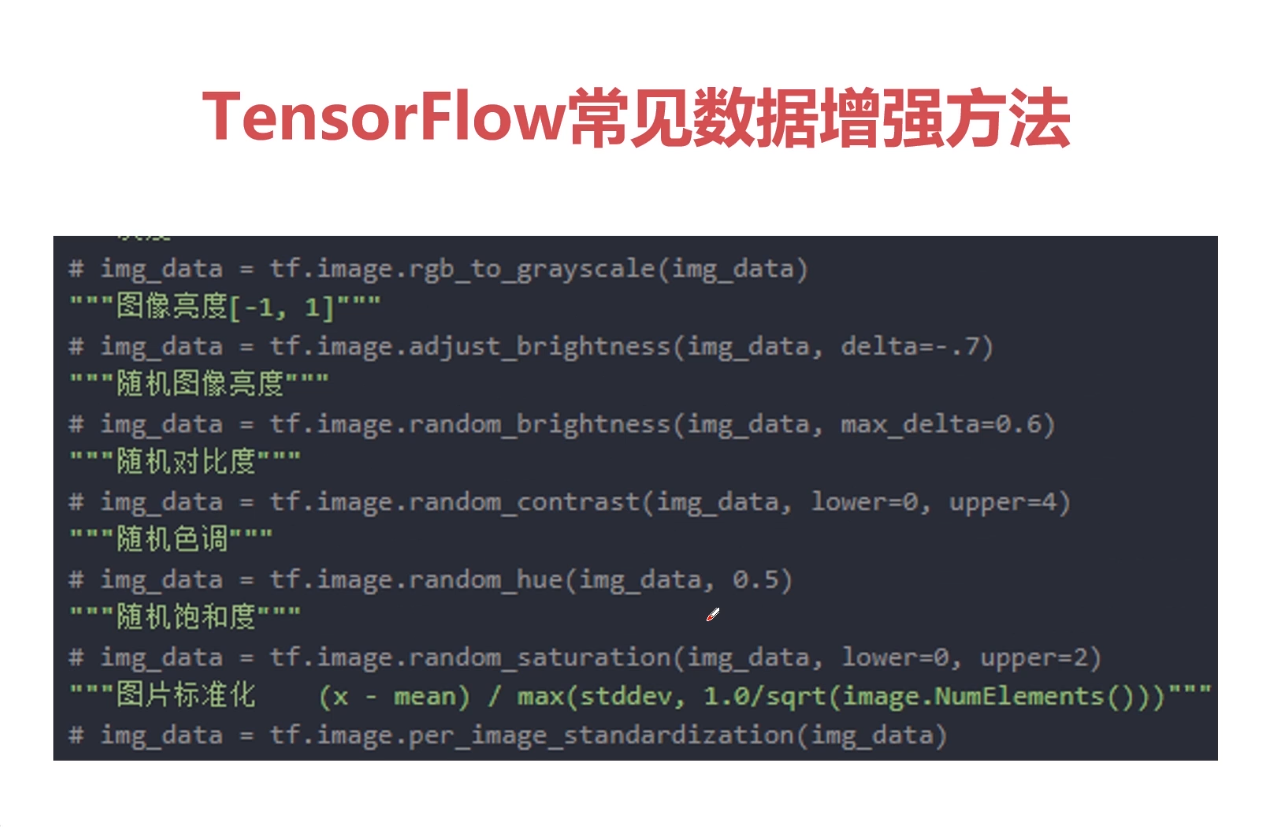








{{uploading-image-585632.png(uploading...)}}