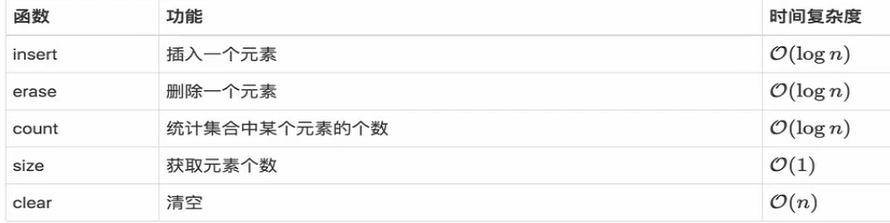
一、动态数组 vector
动态数组, 写作 vector 就是不定长数组,数组的长度可以根据我们的需要动态改变
引用库
c++ 中 vector 的实现在一个 <vector> 头文件中,且要使用std 命名空间,加一句 usiing namespace std;
#include<vector> using namespace std; ......
使用
vector<T> name; T 是类型名,可以是 int float double 或者自定义的数据类型 vector<int> a; 定义了一个 存储整数的动态数组a //初始时,a是空的
基本操作
#include<stdio.h> #include<vector> using namespace std; int main(){ vector<int> a; a.push_back(1); //往最后插入一个元素 a.push_back(2); a.push_back(3); a.push_back(4); for(int i = 0; i < a.size();i++){ //获取大小 printf("%d ",a[i]); //访问动态数组中的元素 } return 0; }
修改:
a[1] = 3; //直接赋值即可
尾部删除:
a.pop_back();
清空: //只会清空vector,并不会清空开辟的内存
a.clear();
清空开辟的内存:
vector<int>().swap(a); //申请一个空的vector, 与 a 交换,即可清空 a 开辟的内存
练习:利用vector存储结构体,并自定义排序
#include<vector> #include<iostream> #include<algorithm> #include<string> using namespace std; struct Stu{ string name; int age; Stu(string na,int ag):name(na),age(ag){ } }; vector<Stu> S; bool cmp(Stu a,Stu b){ return a.age > b.age; } int main(){ int n; scanf("%d",&n); int a; string na; for(int i = 0; i < n;i++){ cin >> na >> a; Stu s(na,a); S.push_back(s); } sort(S.begin(),S.end(),cmp); for(int i = 0;i < S.size();i++) cout << S[i].name << " ";return 0; }
动态数组的初始化:
int n = 10; vector<int> a(n,1);
第一个参数表示出事的动态数组的长度,第二个参数表示初始的数组里面每个元素的值。如果不传入第二个参数,初始值都是0
二维动态数组
vectot<vector<int> >a
注意, <int> >中间有一个空格。这个空格必须加上,否则一些老版本的编译器将不能通过编译
练习:
#include<stdio.h> #include<vector> using namespace std; vector<vector<int> >a; const int n = 5; int main(){ for(int i = 0; i < n;i++){ vector<int> b (i+1,1); a.push_back(b); } for(int i = 0;i < n;i++){ for(int j = 0; j< a[i].size();j++){ printf("%d ",a[i][j]); } printf(" "); } return 0; }

注意:访问 vector 必须时刻注意范围,可以提前开辟好 vector<vector<int> >a(n,vector<int>(m,0)); 如果没有初始化或者 push_back() ,要慎重访问


练习:利用 vector 打印乘法表
#include<stdio.h> #include<vector> using namespace std; vector<vector<int> >a; const int n = 9; int main(){ for(int i = 0; i < n;i++){ a.push_back(vector<int>()); } for(int i = 0; i < a.size();i++){ for(int j = 0; j <= i;j++){ a[i].push_back((i+1) * (j+1)); } } for(int i = 0 ; i < a.size();i++){ for(int j = 0; j < a[i].size();j++){ printf("%d * %d = %d ",j+1,i+1,a[i][j]); } printf(" "); } return 0; }
二、集合set
不重复数据组成
引用库
#include<set> using namespace std;
构造
set<T> s; T 为数据类型, s 为名字 初始的时候,s 是空集合 例如: set<int> a; set<string> b;
插入、删除、判断是否存在
#include<iostream> #include<string> #include<set> using namespace std; set<string> country; int main(){ country.insert("China"); //插入 country.insert("German"); country.insert("Russia"); country.insert("China"); //如果集合中已经存在了某个元素,插入时不会产生任何效果 country.erase("German"); //删除操作————如果集合中不存在要删除的元素,不进行任何操作 if(country.count("China")){ //查找操作————如果集合中存在要查找的元素,返回1,否则返回0 cout << "China..." << endl; } return 0; }
遍历元素
c++ 通过迭代器可以访问集合中的每个元素
通过 * (解引用运算符,不是乘号)可以获取迭代器指向的元素
通过 ++ 操作,让迭代器指向下一个元素, -- 操作让迭代器指向上一个元素
set<T>::iterator it 定义了一个指向 set<T>集合的迭代器 it T是任意的数据类型 ::iterator 是固定的写法
begin 函数返回容器中起始元素的迭代器。end 函数返回容器的尾后迭代器
其中,end 函数的那一位其实是集合最后位的下一位,实际是空的
如果要取最后一位元素的话,记得 end--
#include<iostream> #include<string> #include<set> using namespace std; set<string> country; int main(){ country.insert("China"); country.insert("German"); country.insert("Russia"); country.insert("America"); for(set<string>::iterator it = country.begin(); it != country.end();it++){ cout << *it<<endl; } return 0; }
c++ 中遍历 set 是从小到大遍历的。也就是set 会自动帮我们排序 —————— 如果set中放置的是自定义的结构体的话,还需要重载 ’ < ‘ 运算符
【set 是红黑树的结构】
清空
a.clear() //清空set,同时会清空内存
set和结构体
set内部是从小到大排序的,对于自定义的结构体,需要运算符重载,重新定义小于符号
struct Node{ int x,y; bool operator < (const Node &rhs) const{ if(x == rhs.x){ return y < rhs.y; }else{ return x < rhs.x; } } };

练习:
#include<stdio.h> #include<set> using namespace std; struct Point{ int x,y; bool operator < (const Point &a) const{ if(x == a.x){ return y < a.y; }else{ return x < a.x; } } }; int main(){ int n; scanf("%d",&n); Point p; set<Point> v; for(int i = 0; i< n;i++){ int x,y; scanf("%d %d",&x,&y); p.x = x; p.y = y; v.insert(p); } for(set<Point>::iterator it = v.begin(); it != v.end();it++){ printf("%d %d ",it -> x,it -> y); } return 0; }
三、映射map
引用库
#include<map> using namespace std;
构造一个映射
map<T1,T2> m; 定义了一个名为m 的从T1 类型到 T2类型的映射。初始的时候,m是空映射 例如: map<string,int> m;
插入一个新的映射

映射访问

映射是否存在
某个关键字是否被映射过,你可以直接用 count() 函数。如果关键字存在,返回1,否则会返回0。
遍历映射
C++通过迭代器可以访问集合中的每个元素。这里迭代器指向的元素是一个pair,有first和second两个成员变量,分别代
表一个映射的key和value。
我们用 -> 运算符来获取值,it->first 和 (*it). first 的效果是一样的,就是获取迭代器it指向的pair里first成员的值。
遍历map是按照关键字从小到大遍历的
清空
clear() 函数,可以清空map及其占用的内存

#include<iostream> #include<map> #include<string> #include<utility> using namespace std; int main(){ map<string,int> dict; //dict 是一个string 到 int 的映射,存放每个名字对应的班级号,初始为空 dict.insert(make_pair("Tom",1)); dict.insert(make_pair("Jone",2)); dict["Jike"] = 2; dict["Mary"] = 2; dict["Tom"] = 1; if(dict.count("Mary")){ //如果存在 cout << "Marry is in class" << dict["Mary"] << endl; //访问 } for(map<string,int>::iterator it = dict.begin(); it != dict.end();it++){ //迭代器 cout << it->first << "->" << it->second <<endl; //first 是关键字,second 是对应的值 } dict.clear(); //如果不继续赋值,实际上没必要清空内存 return 0; }
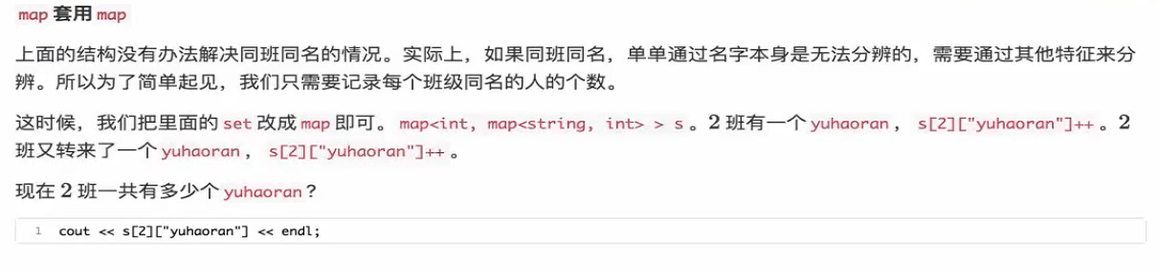
map套用set
为了帮助理解,我们举用一个生活中实际例子。全校有很多班级,每个班级每个人都会有中文名。现在我们需要用一种方式来
记录全校的同学的名字。如果直接用一个set记录,对于重名的同学,那么就没办法分辨了。
我们可以把全校的班级进行编号,对每一个班级建立一 个set,也就是每个班级都映射成一个set,这样就能分辨不同班级的
同名同学了。对于同班的同学来说,一般很少有 重名的。
map<int, set<string> > s就定义上面描述的数据结构,和二维vector-样,两个> >中间的空格不能少了。
这样我们就可以进行插入和查询了。比如:对2班的yuhaoran同学,我们s[2] . insert("yuhaoran")。然后查询yuhaoran是不是
-个2班的人,s[2]. count("yuhaoran")。然后还可以把他从2班删除,s[2] . erase("yuhaoran")。
map 套用 map 示例
遍历第二维:

#include<iostream> #include<map> #include<string> using namespace std; int main(){ map<int,map<string,int> >info; int n; cin >> n; for(int i = 0;i < n;i++){ int class_id; string name; cin >> class_id >> name; info[class_id][name]++; } for(map<int,map<string,int> > ::iterator it1 = info.begin(); it1 != info.end();it1++){ for(map<string,int>::iterator it2 = it1->second.begin();it2 != it1->second.end();it2++){ cout << "There are " << it2->second <<" people named " << it2->first <<" in class "<<it1->first <<"." << endl; } } return 0; }
map<int, set<string>l > s就定义上面描述的数据结构,和二维vector-样,两个> >中间的空格不能少了。这样我们就可以进行插入和查询了。比如对2班的yuhaoran同学,我们s[2] . insert("yuhaoran")。然后查询yuhaoran是不是-个2班的人,s[2]. count("yuhaoran")。然后还可以把他从2班删除,s[2] . erase("yuhaoran")。
例题:打印锯齿矩阵


样例输入:

#include<stdio.h>
#include<iostream>
#include<vector>
using namespace std;
vector<int> mat[10005];
int main(){
int n,m,x,y;
cin >> n >> m;
for(int i = 0; i < m;i++){
cin >> x >> y;
mat[x].push_back(y);
}
for(int i = 1; i <= n;i++){
for(int j = 0; j < mat[i].size();j++){
if(j != mat[i].size()){
cout << mat[i][j] << " ";
}else{
cout << mat[i][j];
}
}
cout << endl;
}
return 0;
}