一、Redis的诞生
在2008年意大利的antirez开发了一个LLOOGG.com这个网站
最多可以查看一万条用户的浏览记录,他需要为每个网站创建一个list,如果网站的浏览记录超过了List的指定长度,他就需要把最先存进去的数据删除,到后面list的长度大了之后,每次添加新的纪录都需要删除旧的数据,当网站的并发量,访问量上升之后,最终限制网站的性能瓶颈是磁盘的问题,所以antirez就想着放弃磁盘存储,将其放到内存中的列表中去。这样去提高列表的push跟pop的效率。所以
antirez就重写了内存数据库,并且实现持久化的机制--Redis。也就是Redis开始只支持列表数据类型,现在已经支持多种数据类型了。
Redis全称是Remote Dictionary Server 远程字典服务。
二、关系型数据库(SQL)跟非关系型数据库(NoSQL)
(1)关系型数据库特点:
1)存储在table中,以行为单位,二维。
2)结构化的(有固定的模式(schema))
3)表与表之间存在关联
4)使用sql查询
5)支持事务(ACID 酸)
(2)关系型数据库限制:
1)只能向上扩展, 分库分表
2)表一旦创建很难修改,表结构不宜修改
3)基于磁盘的读写压力大
(3)非关系型数据库(Not Onle SQL/non-relational)
1)存储的非结构化的数据
2)表与表之间是没有关联的,扩展性强
3)没有事务的特性,遵循base的理论(碱)
4)没有将数据放在磁盘上,支持海量数据存储,大量数据并发
5)支持分布式(实现水平的扩容,分片的存储更加简单)
(4)非关系型数据库分类
1)KV
2)文档存储
3)列存储
4)图存储(Graph)
(5)NEWSQL(TiDB)
结合了关系型数据库跟非关系型数据库的特性
(6)Redis的特性
1)Redis通过将数据放到内存,提供了非常高的吞吐量和很快的读写的速度,支持每秒钟十万次读写操作。
2)更加丰富的数据类型
3)分布式的内存数据库,可以被多个应用共享使用
4)提供丰富的特性,功能。(持久化机制,过期机制(淘汰机制))
5)客户端:支持多种语言。
6)高可用,扩容。
三、Redis安装注意事项
(1)修改配置文件
默认的配置文件是/usr/local/redis-5.0.5/redis.conf
后台启动
daemonize no
改成
daemonize yes
下面一行必须改成 bind 0.0.0.0 或注释,否则只能在本机访问
bind 127.0.0.1
如果需要密码访问,取消requirepass的注释
requirepass yourpassword
(2)使用指定配置文件启动Redis(这个命令建议配置alias)
/usr/local/soft/redis-5.0.5/src/redis-server /usr/local/soft/redis-5.0.5/redis.conf
启动参数修改
1)修改测试文件
2)修改启动参数
3)通过config set命令(3)进入客户端(这个命令建议配置alias)
/usr/local/soft/redis-5.0.5/src/redis-cli
(4)停止redis(在客户端中)
redis> shutdown
或
ps -aux | grep redis
kill -9 xxxx
四、可视化工具

链接:https://pan.baidu.com/s/1HGJJevWvQZeALFgqXQFnRA
提取码:bhr9
五、简介
1,Redis是远程的。有客户端,服务端两部分,他们之间通过redis自定义的协议通信。
2,Redis是基于内存的,他所有的数据,结构存储在内存中,redis所有的操作都很高速,比较吃内存。
3,Redis是非关系型数据库,用于存储数据,
关系型数据库在使用之前必须定义好数据字典,后续的数据按照数据字典进行存储,redis不需要定义数据字典
4,Redis中默认有16个数据库(在redis.conf文件中定义)
![]()
这里的数据库跟关系型数据库中的数据库是两个不同的含义。
5,几个常用的命令
1)启动服务端
在redis/src目录下:./redis-server
在redis/src目录下:./redis-cli
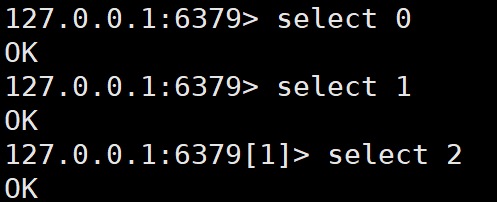
2)切换数据库select 0/1/2/。。。
3)清除数据
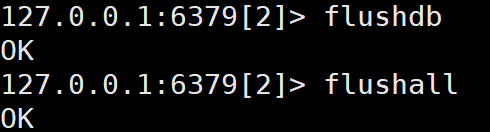
4)Redis的KV的最大容量都是512M。
5)存值,set num1 1234
6)取值,get num1
7)查看所有的键,keys *
8)查看数据库的容量,dbsize
9)查看某个键是否存在,exists num1(存在返回1, 不存在返回0)
10)删除键,del num1(删除成功返回1,删除失败返回0)
11)返回值所存储值的数据类型,type num
12)批量设置值,mset num1 222 num2 333 num3 333(重复的话覆盖原来的值)
13)只有key不存在的时候才能复制成功,setnx num 111【可以用于实现资源的竞争,可以用于分布式锁,通过del key释放锁】
14)设置过期时间,expire key 10【这里过期时间的单位是秒】
15)设置锁的值同hi设置过期时间并且要求key不存在时才能设置成功,set key 11 ex 10 nx
16)递增,incr num1
17)递减,decr num
18)加浮点数,incrbyfloat num 2.2
19)批量获取值,mget num1 num2 num3
20)字符串追加,append num1 hahah
六、Redis存储值的数据类型(非数据结构)
(1)Redis有八种数据类型。(下面是官网给出的八种数据类型)

最常用的就是Binary-safe string二进制安全的字符串(在Redis中String可以存储int,float,String三种类型的数据)
(2)常用的数据类型有五种。
七、存储原理
1,redis时KV的数据库,字典。(使用hashtable(外层hash)实现的字典的数据结构)
2,每个KV都是用一个dictEntry存储
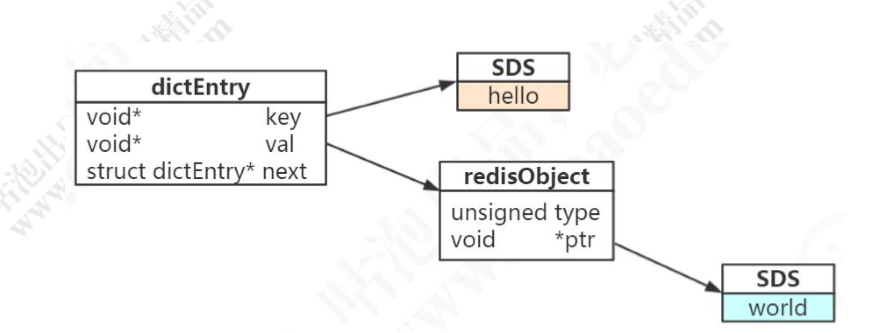
下面是源码(dict.h):
源码地址:https://github.com/antirez/redis
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry;
*key是一个指针,指向key实际的数据结构,key是通过sds存储的。
value是通过一个redisObject来存储的(常用的五大数据类型的值都是存在redisObject里面的)。
下面看一下redisObject的源码:
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; } robj;
type是一个对外的数据类型,比如下面的string
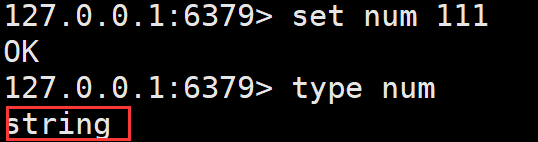
encoding是redis实际的一个结构,底层的一个编码,例如,下面:

lru:LRU_BITS:用来做内存回收的一个字段
refcount:是引用的计数(计数为0表示已经没有对象引用这个对象了,表示可以被回收了)
*ptr:指向真正的数据结构。
3,string的三种编码
(1)int,存储8个字节的长整形,并且长度小于long的长度(2的63次方-1)。
(2)embstr,小于44个字节,embstr的格式是SDS(Simple Dynamic String)。
(3)raw,SDS,存储大于44个字节的字符串。
在源码Object.c中定义了上面的这个“44”:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
这个限制是在5.0版本改成的44,在3.2版本以及之前中是39个字节
4,sds源码
/* Note: sdshdr5 is never used, we just access the flags byte directly. * However is here to document the layout of type 5 SDS strings. */ struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };
sdshdr5表示可以存储2的5次方的字符,
sdshdr8表示可以存储2的8次方的字符,
5,Redis为什么要定义一个SDS
(1)C语言中没有字符串,C语言中的字符串只能通过字符数组来实现。但是,如果使用字符数组来实现会与很多的问题
1)字符数组长度固定,在定义时确定,实际使用长度过长会内存溢出,使用长度不足会造成空间的浪费
2)获取字符数组的长度需要便利数组,时间复杂度较高(o(n))
3)长度变化需要重新分配内存
4)适应�表示字符串的结尾,存储二进制的文件时,文件中常有�就会出现问题。【二进制不安全的】
(2)使用SDS的一个好处
1)不会发生内存溢出,在长度发生改变时,会有相应的扩容
2)获取长度效率高,时间复杂度为O(1),在SDS中定义了一个属性记录引用的个数。
3)空间预分配,惰性空间释放。(减少内存分配的次数)
4)不适用�判断结束,根据数组的长度判断是否结束。
6,SDS中embstr跟raw的区别
embstr
优点:内存连续;查找更方便;只需分配一次内存;
缺点:长度改变,需要重新分配空间。
所以在redis中,embstr是只读的,在对他进行修改时,会先将其转成raw类型。
raw
缺点:内存空间不连续;需要分配两次;
7,类型转换时机(不可逆的)
(1)embstr进行修改时
(2)int类型数据更改后超过2的63次方减一的时候
(3)int类型修改成非int类型时
8,Redis为什么要用不同的编码实现相同的数据类型
节省内存
八、Redis的应用场景
(1)缓存。当我们某些系统接口的速度比较慢的时候,我们可以把某些接口的某些数据缓存起来,下次请求的时候就可以不用请求数据库里,可以直接去Redis缓存中取数据。
(2)队列。Redis中提供了List结构,这个结构提供了pop和push操作,Redis保证了pop和push是原子性的,基于这个机构还有原子性,我们就可以使用Redis做队列使用,使用push插入队列的元素,使用pop弹出队列的元素。
(3)数据存储。增删该查直接在Redis中做,不在使用MySQL,Redis可以这样做的原因是,Redis有非常完备的营办持久化的机制。他有两种持久化的机制,通过这两种机制,我们可以定期的将数据持久化到硬盘中。这样就保证了Redis数据的完整性和安全性。
(4)分布式的Session。Redis是分布式,可以在不同的应用之间共享数据。
(5)分布式锁。set NX EX 。
(6)incr做全局id。
(7)incr做计数器。原子递增。
(8)incr做限流
(9)位操作