1.重点知识回顾
为什么分库分表?
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
分库分表方式:
- 垂直分表
- 垂直分库
- 水平分库
- 水平分表
分库分表带来问题:
由于数据分散在多个数据库,服务器导致了事务一致性问题、跨节点join问题、跨节点分页、排序、函数,主键需要全局唯一,公共表。
Sharding-JDBC基础概念:
逻辑表,真实表,数据节点,绑定表,广播表,分片键,分片算法,分片策略,主键生成策略
Sharding-JDBC核心功能:
数据分片,读写分离
Sharding-JDBC执行流程:
SQL 解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并
最佳实践:
系统在设计之初就应该对业务数据的耦合松紧进行考量,从而进行垂直分库、垂直分表,使数据层架构清晰明了。若非必要,无需进行水平切分,应先从缓存技术着手降低对数据库的访问压力。如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读、写分离原则。若当前数据库压力依然大,且业务数据持续增长无法估量,最后可考虑水平分库、分表,单表拆分数据控制在1000万以内。
2.SQL支持说明
详细参考:https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/
说明:以下为官方显示内容,具体是否适用以实际测试为准 。
支持的SQL
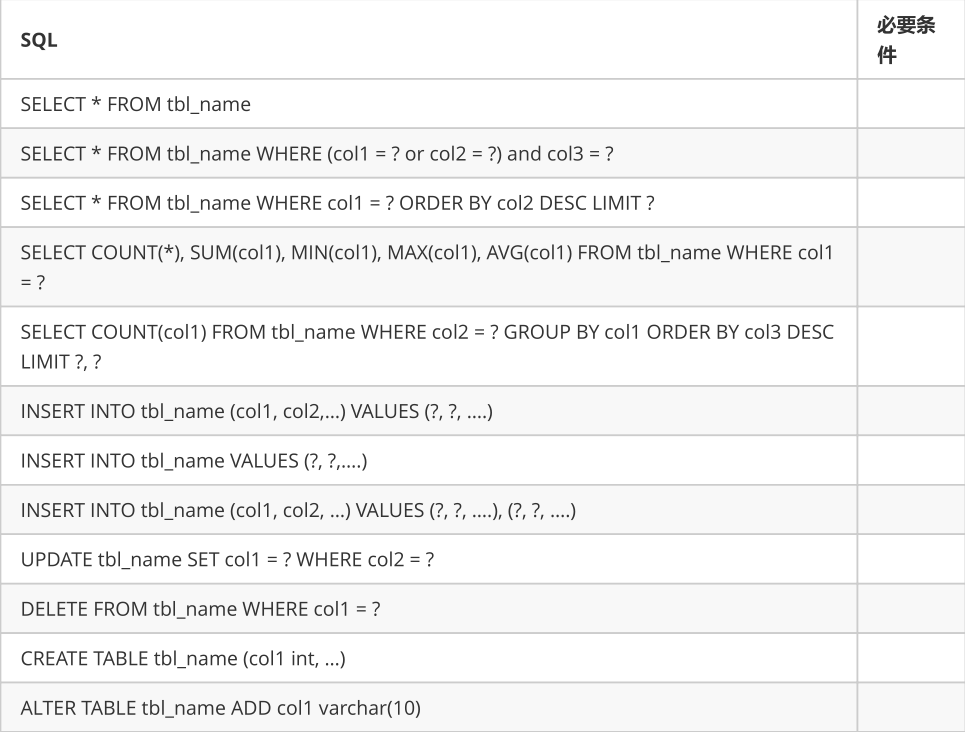
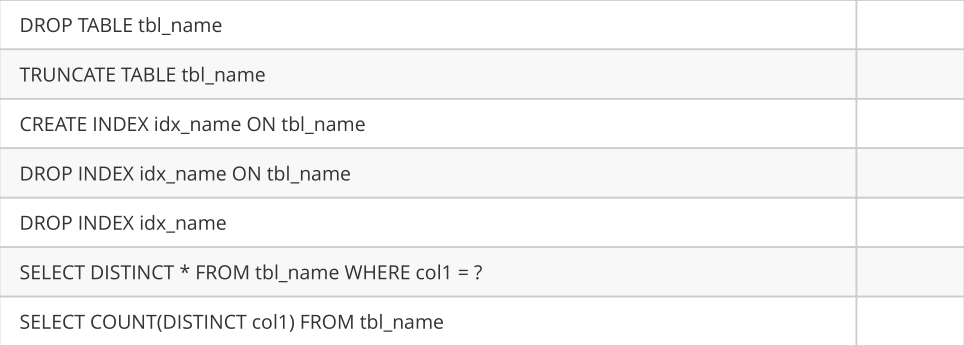
不支持的SQL

DISTINCT支持情况详细说明
支持的SQL
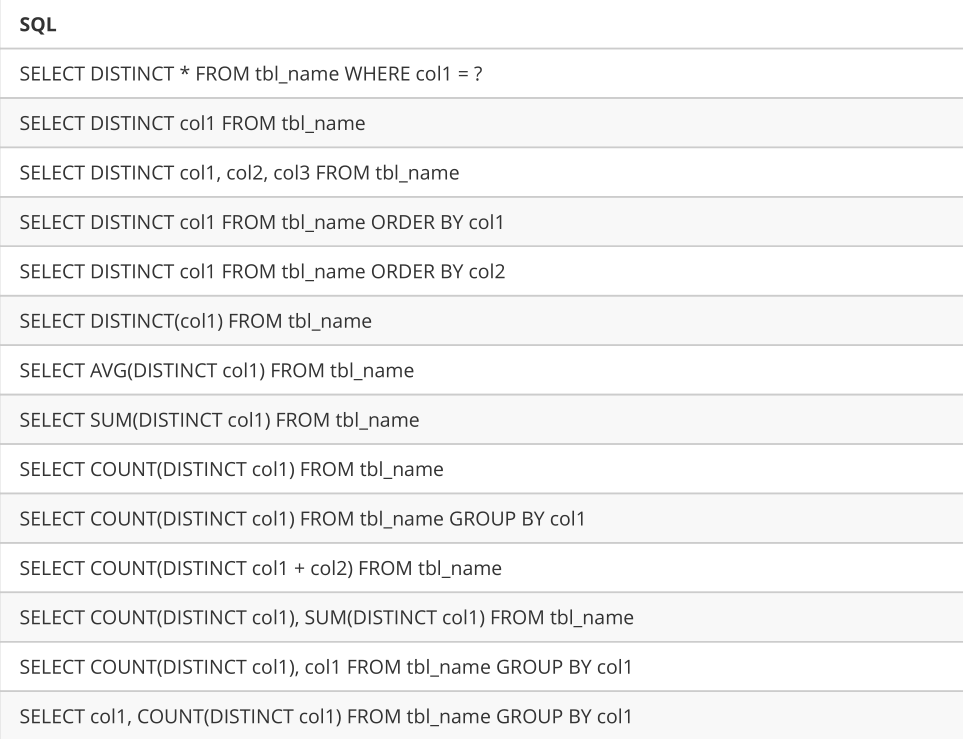
不支持的SQL
