复制可以让其他服务器拥有一个不断地更新得数据副本,从而使得拥有数据副本得服务器可以用于处理客户端发送得读请求。关系数据库通常会使用一个主服务器(master)向多个从服务器(slave)发送更新,并使用从服务器来处理所有读请求。Resis也采用了同样的方式来实现自己的复制特性,并将其作用扩展性能的一种手段。 尽管Redis的性能非常优秀,但是也会遇上没有办法快速地处理请求的情况,特别是在对集合和有序集合进行操作的时候,涉及的元素可能会有上万个甚至上百万个,在这种情况下,执行操作所花费的时间可能需要以秒进行计算,而不是毫秒或者微妙。但即使一个命令只需要花费10毫秒就能完成,单个Redis实例1秒也只能处理100个命令。
###1.主从复制

主从复制的作用:
- 数据副本
- 扩展读性能
主从复制简单总结:
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流向是单向的,master到slave
####1.1两种实现方式
- slaveof命令
 在从服务器上执行 slaveof master_ip master_port 命令,完成同步。
在从服务器上执行 slaveof master_ip master_port 命令,完成同步。
 在从服务器上执行 slaveof no one 取消复制。
在从服务器上执行 slaveof no one 取消复制。
- 基于配置
 修改从服务器配置:
slaveof master_ip master_port :同步主服务器地址和端口。
slave-read-only yes :从服务器设置为只读。
修改从服务器配置:
slaveof master_ip master_port :同步主服务器地址和端口。
slave-read-only yes :从服务器设置为只读。
- 两种方式比较

####1.2从服务器连接主服务器时的步骤
全量同步:
 完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
增量同步: Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从同步策略: 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
注意:如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增宕机。
####1.3主从复制的一些特点
- 采用异步复制。
- 一个主redis可以含有多个从redis。
- 每个从redis可以接收来自其他从redis服务器的连接。
- 主从复制对于主redis服务器来说是非阻塞的,这意味着当从服务器在进行主从复制同步过程中,主redis仍然可以处理外界的访问请求。
- 主从复制对于从redis服务器来说也是非阻塞的,这意味着,即使从redis在进行主从复制过程中也可以接受外界的查询请求,只不过这时候从redis返回的是以前老的数据,如果你不想这样,那么在启动redis时,可以在配置文件中进行设置,那么从redis在复制同步过程中来自外界的查询请求都会返回错误给客户端;(虽然说主从复制过程中对于从redis是非阻塞的,但是当从redis从主redis同步过来最新的数据后还需要将新数据加载到内存中,在加载到内存的过程中是阻塞的,在这段时间内的请求将会被阻,但是即使对于大数据集,加载到内存的时间也是比较多的)。
- 主从复制提高了redis服务的扩展性,避免单个redis服务器的读写访问压力过大的问题,同时也可以给为数据备份及冗余提供一种解决方案。
- 为了编码主redis服务器写磁盘压力带来的开销,可以配置让主redis不在将数据持久化到磁盘,而是通过连接让一个配置的从redis服务器及时的将相关数据持久化到磁盘,不过这样会存在一个问题,就是主redis服务器一旦重启,因为主redis服务器数据为空,这时候通过主从同步可能导致从redis服务器上的数据也被清空。
####1.4Redis大概主从同步是怎么实现的?
全量同步:

 master服务器会开启一个后台进程用于将redis中的数据生成一个rdb文件,与此同时,服务器会缓存所有接收到的来自客户端的写命令(包含增、删、改),当后台保存进程处理完毕后,会将该rdb文件传递给slave服务器,而slave服务器会将rdb文件保存在磁盘并通过读取该文件将数据加载到内存,在此之后master服务器会将在此期间缓存的命令通过redis传输协议发送给slave服务器,然后slave服务器将这些命令依次作用于自己本地的数据集上最终达到数据的一致性。
master服务器会开启一个后台进程用于将redis中的数据生成一个rdb文件,与此同时,服务器会缓存所有接收到的来自客户端的写命令(包含增、删、改),当后台保存进程处理完毕后,会将该rdb文件传递给slave服务器,而slave服务器会将rdb文件保存在磁盘并通过读取该文件将数据加载到内存,在此之后master服务器会将在此期间缓存的命令通过redis传输协议发送给slave服务器,然后slave服务器将这些命令依次作用于自己本地的数据集上最终达到数据的一致性。
部分同步:
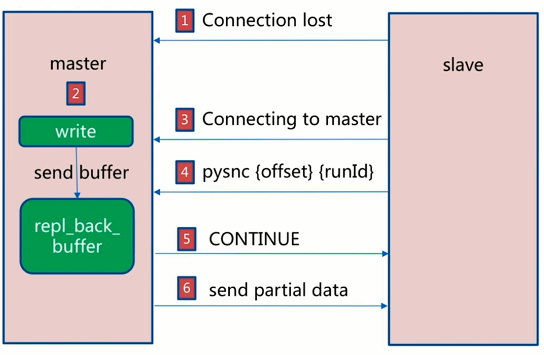 从redis 2.8版本以前,并不支持部分同步,当主从服务器之间的连接断掉之后,master服务器和slave服务器之间都是进行全量数据同步,但是从redis 2.8开始,即使主从连接中途断掉,也不需要进行全量同步,因为从这个版本开始融入了部分同步的概念。部分同步的实现依赖于在master服务器内存中给每个slave服务器维护了一份同步日志和同步标识,每个slave服务器在跟master服务器进行同步时都会携带自己的同步标识和上次同步的最后位置。当主从连接断掉之后,slave服务器隔断时间(默认1s)主动尝试和master服务器进行连接,如果从服务器携带的偏移量标识还在master服务器上的同步备份日志中,那么就从slave发送的偏移量开始继续上次的同步操作,如果slave发送的偏移量已经不再master的同步备份日志中(可能由于主从之间断掉的时间比较长或者在断掉的短暂时间内master服务器接收到大量的写操作),则必须进行一次全量更新。在部分同步过程中,master会将本地记录的同步备份日志中记录的指令依次发送给slave服务器从而达到数据一致。
从redis 2.8版本以前,并不支持部分同步,当主从服务器之间的连接断掉之后,master服务器和slave服务器之间都是进行全量数据同步,但是从redis 2.8开始,即使主从连接中途断掉,也不需要进行全量同步,因为从这个版本开始融入了部分同步的概念。部分同步的实现依赖于在master服务器内存中给每个slave服务器维护了一份同步日志和同步标识,每个slave服务器在跟master服务器进行同步时都会携带自己的同步标识和上次同步的最后位置。当主从连接断掉之后,slave服务器隔断时间(默认1s)主动尝试和master服务器进行连接,如果从服务器携带的偏移量标识还在master服务器上的同步备份日志中,那么就从slave发送的偏移量开始继续上次的同步操作,如果slave发送的偏移量已经不再master的同步备份日志中(可能由于主从之间断掉的时间比较长或者在断掉的短暂时间内master服务器接收到大量的写操作),则必须进行一次全量更新。在部分同步过程中,master会将本地记录的同步备份日志中记录的指令依次发送给slave服务器从而达到数据一致。
####1.4runid和复制偏移量 redis每次启动的时候都会有一个随机的ID,作为一个标识,这个ID就是runid,当然重启之后值就改变了。
runid 查看runid:redis-cli -p 6379 info | grep run 假如端口为6380的redis去复制6379,知道runid后,在6380上做一个标识,如果runid改变了,说明主可能重启了或者发生了其它变化,这时候就可以做一个全量复制把数据同步过来。或者第一次启动时根本不知道6379的runid,也会进行全量复制
**偏移量:**数据写入量的字节 比如主执行set hello world,就会有一个偏移量,然后从同步数据,也会记录一个偏移量当两个偏移量达到一致时候,实际上数据就是完全同步的状态。
参考:https://www.cnblogs.com/daofaziran/p/10978628.html