1.Webdriver原理
webdirver是一款web自动化操作工具,为浏览器提供统一的webdriver接口,由client也就是我们的测试脚本提交请求,remote server浏览器进行响应请求,相对于原来selenium1中的selenium rc更加的简便,对浏览器的操作更加灵活。
2.定位
(1)元素的定位:
元素的定位可以通过id,name,class name,tag name,link_text,partial_link_text,css selector,xpath等
语法格式为:find_element_by_xxxx()
例如百度的搜索框
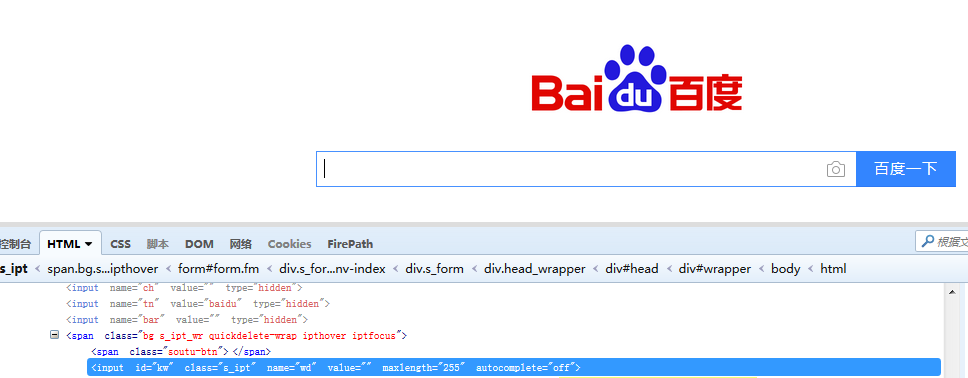
如果想要定位百度搜索框则可以
find_element_by_id("kw") or find_element_by_class_name("s_pt") or find_element_by_name("wd") or find_element_by_tag_name("input")
或者通过xpath定位:可以使用FirePath工具定位:
xpath:find_element_by_xpth(".//*[@id='kw']")
如果是一个文本链接可以通过link_name("文本")或者文本信息较长的可以通过部分文本信息来定位partial_link_text("部分文本")
以上的所有定位准确前提是必须保证定位元素括号中填写的信息的唯一性,才可以准确定位到元素上,例如定位class_name,必须确定仅有该元素应用到该calss name,否则请更换其他的定位方式。
有关元素的定位一般还是建议有id的,有name的,用这两者定位更加准确,xpath也是一个重要的定位方式。
*.xpath定位
虽然说xpath定位可以借用类似FirePath这样的工具来获取,但是我们还是必须清楚xpath定位的语法,以便后期我们在修改代码的时候能够清楚元素到底定位的是哪个。
xpath的路径表达式:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
带谓语的表达式,谓语用中括号括描述,选取所有可以用*
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
(2)定位一组对象
定位单个元素是find_element,那么定位一组对象则是find_elements
定位一组对象的情况是对需要对一组对象进行批量操作或者是需要选取多个条件一样或类似的元素,其是先选取一组对象后再根据筛选条件进行遍历过滤最终定位所需的符合条件的元素。
例如:勾选所有的checbox元素或者是对一组元素做同样的操作的时候
checbox = find_elements_by_xx() #首先定位一组元素 for i in checkbox: #遍历勾选所有checkbox i.click()
(3)层级定位
很多元素都没有规范的id或者name来定位,而且元素的class name和tag name都是一样的,且又是第几层的元素,很难定位,所以定位该元素的方法是,先定位父级元素,然后再定位子级元素
例如:菜单list中子级菜单标签的定位
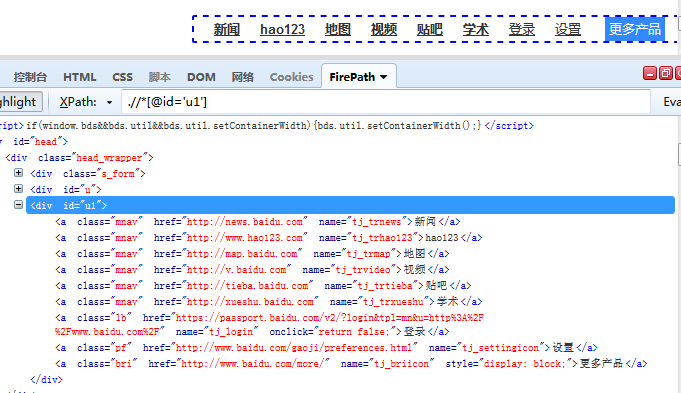
如果要定位新闻标签,我们可以通过先定位ul元素,再定位a元素,这样定位比较准确
parent = find_element_by_id("ul") children = parent.find_element_by_name("tj_tnews") chidren.click()
(4)定位Frame中的对象
有些页面的框架嵌套着另一个框架,如果需要定位被嵌套的框架里的内容则可以先定位到外部框架,再定位到被嵌套的框架,然后就可以定位里面的页面元素,其实这个思路和定位层级元素是一样的,只是这里用到定位框架的语句需要记下
switch_to_frame(id)
例如:框架A嵌套这框架B,现在需要定位框架B中的文本框
switch_to_frame(id = a) switch_to_frame(id = b) find_element_by_id("textboxid")
定位弹出的框架后操作完成需要跳出框架才可以定位原先页面上的元素。
driver.switch_to_frame("layui-layer-iframe1") #定位框架 ..... driver.switch_to_default_content() 跳出框架 driver.find_element_by_xpath("html/body")