什么是链表
和数组一样,链表也是一种线性表。
从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构。
链表中的每一个内存块被称为节点Node。节点除了存储数据外,还需记录链上下一个节点的地址,即后继指针next。
链表的特点
插入、删除数据效率高,时间复杂度为O(1),只需更改指针指向即可。
随机访问效率低,时间复杂度为O(n),需要从链头至链尾进行遍历。
和数组相比,链表的内存空间消耗更大,因为每个存储数据的节点都需要额外的空间存储后继指针。
常见的链表结构
单链表
每个节点只包含一个指针,即后继指针。
单链表有两个特殊的节点,即首节点和尾节点。
用首节点地址表示整条链表,尾节点的后继指针指向空地址null。
性能特点,插入和删除节点的时间复杂度为O(1),查找的时间复杂度为O(n)。

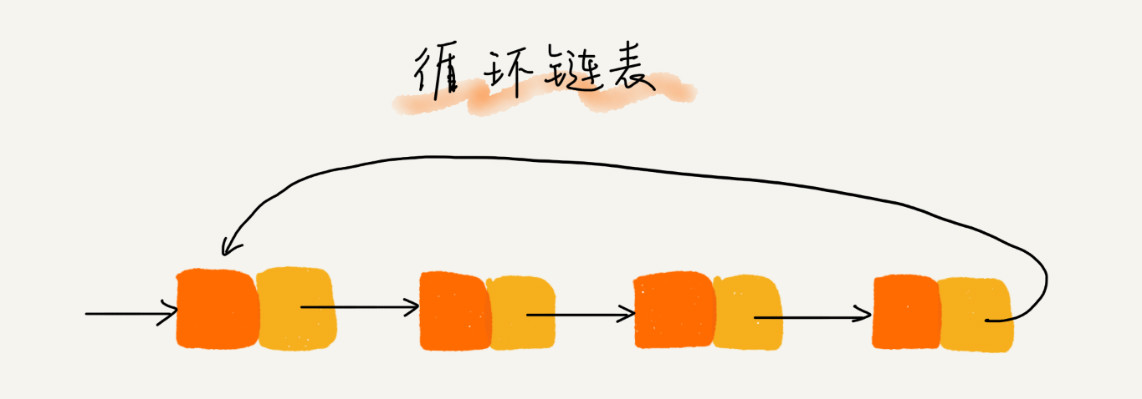
循环链表
除了尾节点的后继指针指向首节点的地址外均与单链表一致。
适用于存储有循环特点的数据,比如约瑟夫问题。
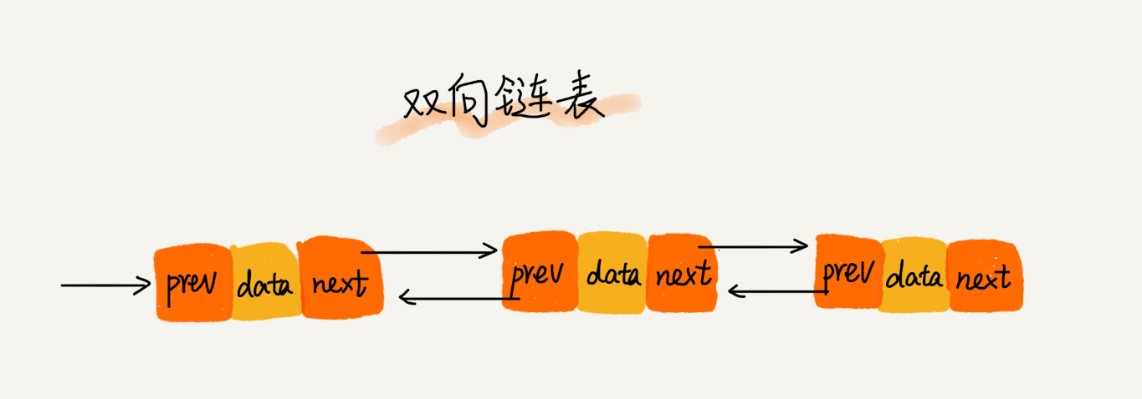
双向链表
节点除了存储数据外,还有两个指针分别指向前一个节点地址(前驱指针prev)和下一个节点地址(后继指针next)。
首节点的前驱指针prev和尾节点的后继指针next均指向空地址。
性能特点,和单链表相比,存储相同的数据,需要消耗更多的存储空间。
插入、删除操作比单链表效率更高,时间复杂度为O(1)。以删除操作为例,删除操作分为两种情况
给定数据值删除对应节点
单链表和双向链表都需要从头到尾进行遍历从而找到对应节点进行删除,时间复杂度为O(n)。
给定节点地址删除节点。
要进行删除操作必须找到前驱节点,单链表需要从头到尾进行遍历直到p->next = q,
时间复杂度为O(n),而双向链表可以直接找到前驱节点,时间复杂度为O(1)。
和单链表相比的优势
对于一个有序链表,双向链表的按值查询效率要比单链表高一些。
因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
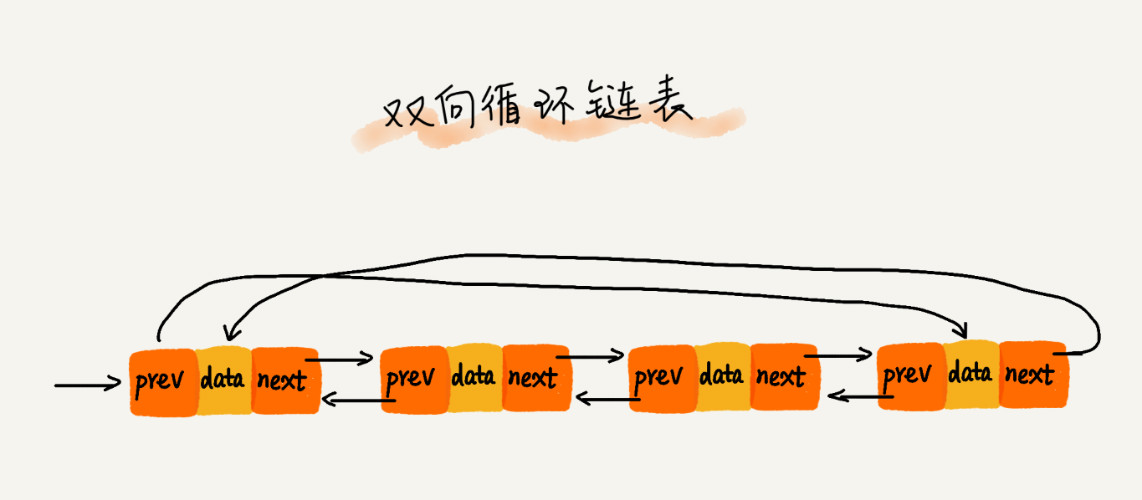
双向循环链表
首节点的前驱指针指向尾节点,尾节点的后继指针指向首节点。
选择数组还是链表
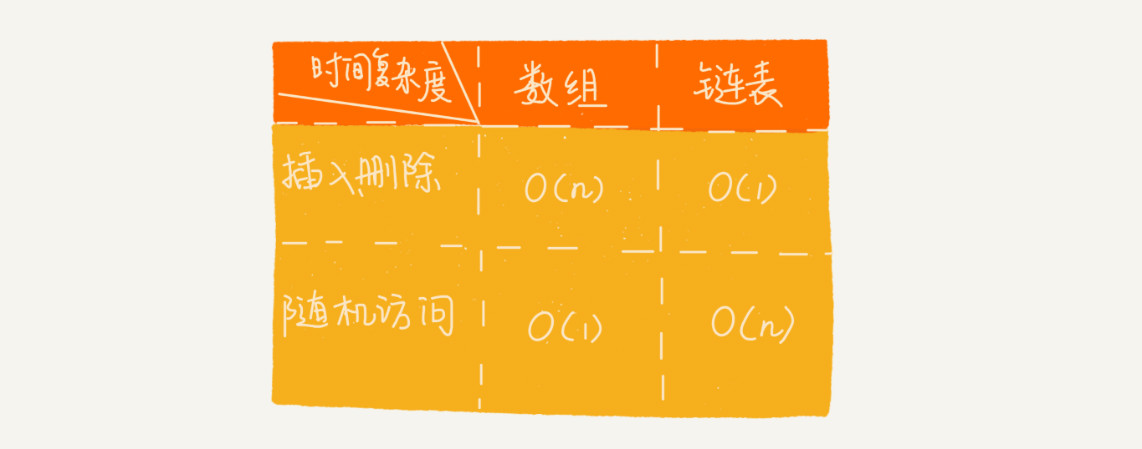
插入、删除和随机访问的时间复杂度
数组:插入、删除的时间复杂度是O(n),随机访问的时间复杂度是O(1)。
链表:插入、删除的时间复杂度是O(1),随机访问的时间复杂端是O(n)。
数组的缺点
1)若申请内存空间很大,比如100M,但若内存空间没有100M的连续空间时,则会申请失败,尽管内存可用空间超过100M。
2)大小固定,若存储空间不足,需进行扩容,一旦扩容就要进行数据复制,而这时非常费时的。
链表的缺点
1)内存空间消耗更大,因为需要额外的空间存储指针信息。
2)对链表进行频繁的插入和删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,如果是Java语言,还可能会造成频繁的GC(自动垃圾回收器)操作。
如何选择链表和数组
数组简单易用,在实现上使用连续的内存空间,可以借助CPU的缓冲机制预读数组中的数据,所以访问效率更高。
而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法预读。
如果代码对内存的使用非常苛刻,那数组就更适合。
课后思考
如何判断一个字符串是否是回文字符串的问题
思考:将字符串按单个字符存入双向链表,双向链表从首尾同时开始遍历,比较首尾字符是否相等。
写链表代码的几个技巧
理解指针或引用的含义
含义
将某个变量(对象)赋值给指针(引用),实际上就是就是将这个变量(对象)的地址赋值给指针(引用)。
示例
p—>next = q;
表示p节点的后继指针存储了q节点的内存地址。
p—>next = p—>next—>next;
表示p节点的后继指针存储了p节点的下下个节点的内存地址。
警惕指针丢失和内存泄漏(单链表)
插入节点
在节点a和节点b之间插入节点x,b是a的下一节点,p指针指向节点a,则造成指针丢失和内存泄漏的代码
p—>next = x;
x—>next = p—>next;
显然这会导致x节点的后继指针指向自身。
正确的写法是两句代码交换顺序,即
x—>next = p—>next;
p—>next = x;
删除节点
在节点a和节点b之间删除节点b,b是a的下一节点,p指针指向节点a
p—>next = p—>next—>next;
利用“哨兵”简化实现难度
什么是哨兵
链表中的“哨兵”节点是解决边界问题的,不参与业务逻辑。
如果我们引入“哨兵”节点,则不管链表是否为空,head指针都会指向这个“哨兵”节点。
我们把这种有“哨兵”节点的链表称为带头链表,相反,没有“哨兵”节点的链表就称为不带头链表。
未引入哨兵的情况
如果在p节点后插入一个节点,只需2行代码即可搞定:
new_node—>next = p—>next;
p—>next = new_node;
但,若向空链表中插入一个节点,则代码如下:
if(head == null){ head = new_node; }
如果要删除节点p的后继节点,只需1行代码即可搞定:
p—>next = p—>next—>next;
但,若是删除链表的最有一个节点(链表中只剩下这个节点),则代码如下:
if(head—>next == null){ head = null; }
从上面的情况可以看出,针对链表的插入、删除操作,需要对插入第一个节点和删除最后一个节点的情况进行特殊处理。
这样代码就会显得很繁琐,所以引入“哨兵”节点来解决这个问题。
引入哨兵的情况
哨兵节点不存储数据,无论链表是否为空,head指针都会指向它,作为链表的头结点始终存在。
这样,插入第一个节点和插入其他节点,删除最后一个节点和删除其他节点都可以统一为相同的代码实现逻辑了。
重点留意边界条件处理
经常用来检查链表是否正确的边界4个边界条件:
1.如果链表为空时,代码是否能正常工作?
2.如果链表只包含一个节点时,代码是否能正常工作?
3.如果链表只包含两个节点时,代码是否能正常工作?
4.代码逻辑在处理头尾节点时是否能正常工作?
5个常见的链表操作
1.单链表反转
2.链表中环的检测
3.两个有序链表合并
4.删除链表倒数第n个节点
5.求链表的中间节点
单链表C#代码演示
节点类、链表类及其简单添加删除方法的实现
单链表节点类
单链表的结点有一个泛型的字段作为数据域,一个结点类的字段作为后继结点引用域。
public sealed class Node<T>{ private T data;//泛型数据data private Node<T> next;//指向下一个结点地址的引用域 //以上私有字段对应的公有属性 public T Data{ get{return data;} set{data = value;} } public Node<T> Next{ get{return next;} set{next = value;} } //有参实例构造器,参数为泛型 public Node(T data){ this.data = data; } }
单链表类
单链表类有一个结点类的头结点head指向哨兵结点的地址,有一个哨兵结点firstNode,在实例构造器里将其next引用域初始化为null。
展示代码中实现了简单的顺序添加结点的方法和删除节点的方法,前插和后插方法在这里不做展示。
public sealed class SinglyLinkedList<T>{ //头结点私有字段及公有属性 private Node<T> head; public Node<T> Head{ get { return head; } set { head = value; } } //哨兵结点私有字段及公有属性 private Node<T> firstNode; public Node<T> FirstNode{ get { return firstNode; } set { firstNode = value; } } //无参实例构造器,初始化head和firstNode public SinglyLinkedList(){ firstNode = null; head = firstNode; } //Add方法,遍历链表找到尾部插入结点 public void Add(T data){ Node<T> p = new Node<T>(data); Node<T> temp = firstNode; while (temp.Next != null) temp = temp.Next; temp.Next=p; } //Delete方法,遍历链表,找到要删除的结点及其前驱结点 //将前驱结点的next引用域设置为其next引用域 public void Delete(Node<T> p){ Node<T> p = new Node<T>(data); Node<T> temp = firstNode; while (temp.Next != null){ if (temp.Next == p){ temp.Next = p.Next; } else temp = temp.Next; } } }
5个常见的链表操作的实现
单链表反转