一、HDFS
1. HDFS的读流程
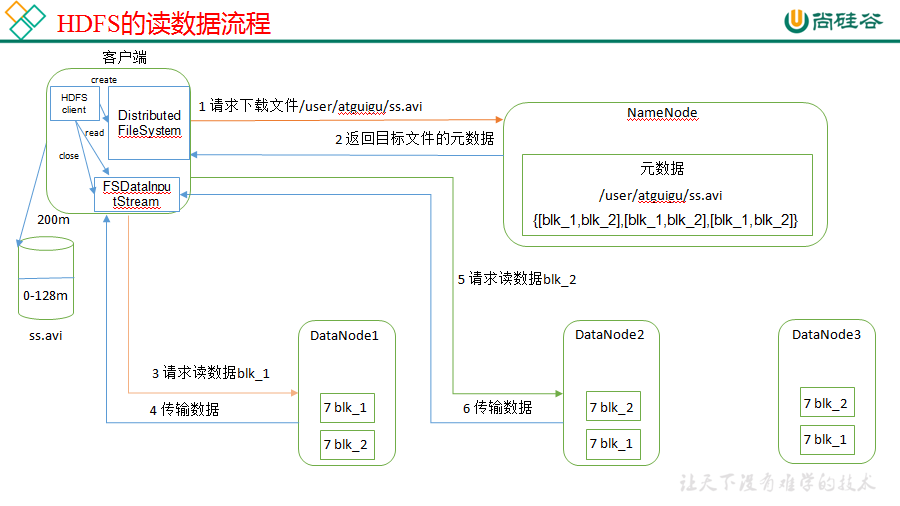
- 客户端向NameNode发起读数据请求;
- NameNode响应请求并告诉客户端要读的文件的数据块位置(存在哪个DataNode上);
- 客户端到对应DataNode读取数据,当数据读取到达末端,关闭与这个DataNode的连接,并查找下一个数据块,直到文件数据全部读完;
- 最后关闭输出流。
2. HDFS的写流程
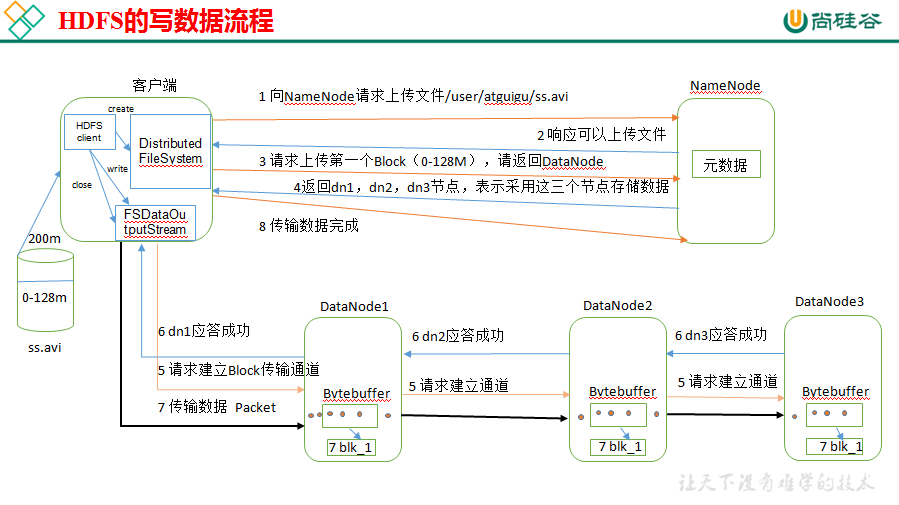
- 客户端向NameNode发起写数据请求;
- NameNode相应请求(NameNode会检查要创建的文件是否已经存在,创建者是否有权限,成功会创建一个记录,失败会报异常);
- 客户端将文件进行切片(分成数据块),然后上传数据块,按照一个一个的形式进行发送,每个数据块都要写到三个DataNode上;
- 成功后DataNode会返回一个确认队列给客户端,客户端进行效验,然后客户端上传下一个数据块到DataNode,直到所有数据块写入完成;
- 当所有数据块全部写入成功后,客户端会向NameNode发送一个反馈并关闭数据流。
3. Hadoop有哪些配置文件?
core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves container-executor.cfg(会默认禁止root等用户提交任务)
4. 小文件过多会造成什么影响?
因为文件的存放位置数据(元数据)存在于NameNode的内存,1个文件块,占用namenode内存大概150-200字节,小文件过多,对nn负荷比较大。
解决方案:
- 采用har归档方式,将小文件归档
- 采用CombineTextInputFormat
-
有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
5. block为什么设置成128M,为什么不建议设置太大,或者太小?
block大小设置原则:
1. 减少硬盘寻道时间:
2. 减少NameNode内存消耗:NameNode需要在内存FSImage文件中记录DataNode中数据块信息,若block size太小,那么需要维护的数据块信息会更多。
3. map崩溃问题:若Map任务崩溃,重新启动执行需要重新加载数据,数据块越大,数据加载时间将越长,恢复时间越长。
4. 网络传输问题: 在数据读写计算的时候,需要进行网络传输.如果block过大会导致网络传输时间增长,程序卡顿/超时/无响应.
如果块设置过大:
第一点: 从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
第二点: mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢。
第三点: 在数据读写计算的时候,需要进行网络传输.如果block过大会导致网络传输时间增长,程序卡顿/超时/无响应. 任务执行的过程中拉取其他节点的block或者失败重试的成本会过高.
第四点: namenode监管容易判断数据节点死亡.导致集群频繁产生/移除副本, 占用cpu,网络,内存资源.
如果块设置太小:
第一点: 存放大量小文件会占用NameNode中大量内存来存储元数据
第二点: 文件块过小,寻址时间增大,导致程序一直在找block的开始位置
为什么设置为128M:
时间和空间的权衡,磁盘的传输速度大概在100M,寻址时间大概在1s,而且千兆网卡传输速度在100M/s 所以大概为100M
6. namenode对元数据的管理
namenode对数据的管理采用了三种存储形式:
-
内存元数据(NameSystem)
-
磁盘元数据镜像文件(fsimage镜像)
-
数据操作日志文件(可通过日志运算出元数据)(edit日志文件)
7. checkpiont 触发条件?
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
- 两次检查点创建之间的固定时间间隔,默认3600,即1小时。
- 检查的事务数量。若检查事务数达到这个值,也触发一次
8. DFSZKFailoverController的作用?
它是一个守护进程,它负责和ZK通信,并且时刻检查NameNode的健康状况。它通过不断的ping,如果能ping通,则说明节点是健康的。然后ZKFC会和ZK保持一个持久通话,及Session对话,并且ActiveNode在ZK里面记录了一个"锁",这样就会Prevent其它节点成为ActiveNode,当会话丢失时,ZKFC会发通知给ZK,同时删掉"锁",这个时候其它NameNode会去争抢并建立新的“锁”,这个过程叫ZKFC的选举。
9. MapReduce哪里使用了combiner?
combiner的作用是在Map端把同一个key的键值对合并在一起并计算
- 数据在环形缓存区根据分区排序完成,在溢写文件之前会执行一次combiner
- 多个溢写文件在进行merge合并时,也会触发一次combiner
10. MapReduce中partition的作用?
partition的主要作用将map阶段产生的所有kv对分配给不同的reducer task处理,可以将reduce阶段的处理负载进行分摊。
HashPartitioner是mapreduce的默认partitioner。
- 当map输出的时候,写入缓存之前,会调用partition函数,计算出数据所属的分区,并且把这个元数据存储起来。
- 把属与同一分区的数据合并在一起。
11. MapReduce中map,reduce数量如何决定,怎么配置?
1. map数量
- 默认map个数
(1)如果不进行任何设置,默认的map个数是和blcok_size相关的。
default_num = total_size / block_size;
(2)用户指定mapreduce.map.tasks
exp_num = max(exp_num, default_num)
(3)获取分片大小mapreduce.min.split.size
split_max_size = max(mapreduce.min.split.size , block_size)
(4) 获取分片个数
split_num = total_size / split_max_size
(5) 获取真实的map个数
real_num = min(split_num, exp_num)
- 如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。减少mapred.min.split.size的值
- 如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。减小mapred.map.tasks 为一个较小的值。
2. reduce数量
- 默认为-1,代表系统根据需要自行决定reduce个数(根据一个reduce能够处理的数据量来决定)
- 手动设置
12. MapReduce优化
数据输入:
- 在进行map任务前,合并小文件,大量的小文件会产生大量的map任务
- 采用combineTextInputformat来作为输入
Map阶段:
- 减少溢写(spill)次数:io.sort.mb 和 .sort.spill.percent 增大内存上限和溢写百分比
- 减少合并(merge)次数:调整io.sort.factor ,增大merge文件数目,减少merge次数
- 在map后,再不影响业务逻辑的情况下,先进行combiner处理
Reduce阶段:
- 设置合理的map和reduce数量:设置太少导致task任务等待,延长处理时间,太多会导致任务间资源竞争
- 增加每个Reduce去Map中拿数据的并行数
- 集群性能可以的前提下,增大 Reduce 端存储数据内存的大小。
I/O传输:
- 采用数据压缩的方式,减少网络 IO 的的时间。安装 Snappy 和 LZOP 压缩编码器。
- 使用orc,parquet,sequenceFile等文件格式
整体:
- MapTask 默认内存大小为 1G,可以增加 MapTask 内存大小为 4-5g
- ReduceTask 默认内存大小为 1G,可以增加 ReduceTask 内存大小为 4-5g
- 可以增加 MapTask 的 cpu 核数,增加 ReduceTask 的 CPU 核数
- 增加每个 Container 的 CPU 核数和内存大小
- 调整每个 Map Task 和 Reduce Task 最大重试次数
13. 用mapreduce怎么处理数据倾斜问题?
数据倾斜:map /reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜。
1)提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。
2)导致数据倾斜的key 大量分布在不同的mapper
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度
JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer
14. Hadoop高可用HA模式
HDFS高可用原理:
Hadoop HA(High Available)状态分别是Active和Standby. Standby Namenode作为热备份,从而允许在机器发生故障时能够快速进行故障转移,同时在日常维护的时候使用优雅的方式进行Namenode切换。Namenode只能配置一主一备,不能多于两个Namenode。
主Namenode处理所有的操作请求(读写),维护尽可能同步的状态,为了使Standby Namenode与Active Namenode数据保持同步,两个Namenode都与一组Journal Node进行通信。当主Namenode进行任务的namespace操作时,都会确保持久会修改日志到Journal Node节点中。Standby Namenode持续监控这些edit,当监测到变化时,将这些修改同步到自己的namespace。
当进行故障转移时,Standby在成为Active Namenode之前,会确保自己已经读取了Journal Node中的所有edit日志,从而保持数据状态与故障发生前一致。
确保任何时刻只有一个Namenode处于Active状态非常重要,否则可能出现数据丢失或者数据损坏。当两台Namenode都认为自己的Active Namenode时,会同时尝试写入数据(不会再去检测和同步数据)。为了防止这种脑裂现象,Journal Nodes只允许一个Namenode写入数据,内部通过维护epoch数来控制,从而安全地进行故障转移。
二、YARN
1. 集群资源分配参数(项目中遇到的问题)
集群有30台机器,跑mr任务的时候发现5个map任务全都分配到了同一台机器上,这个可能是由于什么原因导致的吗?
解决方案:yarn.scheduler.fair.assignmultiple 是否允许NodeManager一次分配多个容器 这个参数 默认是开的,需要关掉
2. yarn的几种调度器
FIFO: 单队列,先进先出,(生产环境一般不用)
CapacityScheduler(容量调度):多队列,队列内部任务先进先出 CDH默认
FairScheduler(公平调度):支持多队列,保证每个任务公平享有队列资源。apache 和 HDP 默认
3. yarn提交任务的流程

-
用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
-
ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster。
-
ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
-
ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
-
一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
-
NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
-
各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
-
应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
4. yarn中的 vcores 是什么意思?
在yarn中使用的是虚拟CPU,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力不一,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。
三、HIVE
1. insert into 和 override write区别?
insert into:将数据写到表中
override write:覆盖之前的内容
2. order by 、sort by、disturb by 、cluster by 区别?
order by(全局排序)
order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个reducer,会导致当输入规模较大时,消耗较长的计算时间。
sort by (分区内排序)
不是全局排序,其在数据进入reducer前完成排序,也就是说它会在数据进入reduce之前为每个reducer都产生一个排序后的文件。因此,如果用sort by进行排序,并且设置mapreduce.job.reduces>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
distribute by(数据分发)
distribute by是控制在map端如何拆分数据给reduce端的。类似于MapReduce中分区partationer对数据进行分区
hive会根据distribute by后面列,将数据分发给对应的reducer,默认是采用hash算法+取余数的方式。
sort by为每个reduce产生一个排序文件,在有些情况下,你需要控制某写特定的行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
cluster by
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
-
order by 是全局排序,可能性能会比较差;
-
sort by分区内有序,往往配合distribute by来确定该分区都有那些数据;
-
distribute by 确定了数据分发的规则,满足相同条件的数据被分发到一个reducer;
-
cluster by 当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by,但是cluster by默认是升序,不能指定排序方向;
-
sort by limit 相当于每个reduce 的数据limit 之后,进行order by 然后再limit ;
3. 用hive创建表有几种方式?
hive建表有三种方式
-
直接建表法
-
查询建表法(通过AS 查询语句完成建表:将子查询的结果存在新表里,有数据,一般用于中间表)
-
like建表法(会创建结构完全相同的表,但是没有数据)
4. union all和union的区别
union 去重
union all 不去重
5. hive的优化
数据的压缩与存储格式
数据存储格式采用orc/parquet 列式存储格式
压缩格式采用snappy 或者lzo lzo支持压缩文件切分
合理利用分区分桶
分区是将表的数据在物理上分成不同的文件夹,以便于在查询时可以精准指定所要读取的分区目录,从来降低读取的数据量
分桶是将表数据按指定列的hash散列后分在了不同的文件中,将来查询时,hive可以根据分桶结构,快速定位到一行数据所在的分桶文件,从来提高读取效率
hive参数优化
开启任务并行执行 set hive.exec.parallel=true;
设置jvm重用 特别是很难避免小文件的场景或者task特别多的场景,这类场景大多数执行时间都很短。jvm的启动过程可能会造成相当大的开销,尤其是执行的job包含有成千上万个task任务的情况。
调整map切片大小
调整map tasks个数
调整每个reduce所接受的数据量大小 set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
直接设置reduce数量 set mapred.reduce.tasks = 20
map端聚合,降低传给reduce的数据量 set hive.map.aggr=true
开启hive内置的数倾优化机制 set hive.groupby.skewindata=true
sql优化
1. where条件优化
优化前(关系数据库不用考虑会自动优化)
select m.cid,u.id from order m join customer u on( m.cid =u.id )where m.dt='20180808';
优化后(where条件在map端执行而不是在reduce端执行)
select m.cid,u.id from (select * from order where dt='20180818') m join customer u on( m.cid =u.id);
2. count distinct优化
不要使用count (distinct cloumn) ,使用子查询
select count(1) from (select id from tablename group by id) tmp;
join 优化
Common/shuffle/Reduce JOIN 连接发生的阶段,发生在reduce 阶段, 适用于大表 连接 大表(默认的方式)
Map join :连接发生在map阶段 , 适用于小表 连接 大表
大表的数据从文件中读取
小表的数据存放在内存中(hive中已经自动进行了优化,自动判断小表,然后进行缓存)
SMB join
Sort -Merge -Bucket Join 对大表连接大表的优化,用桶表的概念来进行优化。在一个桶内发生笛卡尔积连接(需要是两个桶表进行join)
6. hive的数据倾斜问题
1)怎么产生的数据倾斜?
(1)不同数据类型关联产生数据倾斜
情形:比如用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时。
后果:处理此特殊值的reduce耗时;只有一个reduce任务
默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。
解决方式:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)
(2)控制空值分布
在生产环境经常会用大量空值数据进入到一个reduce中去,导致数据倾斜。
解决办法:
自定义分区,将为空的key转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分不到多个Reducer。
注意:对于异常值如果不需要的话,最好是提前在where条件里过滤掉,这样可以使计算量大大减少
(3)group by
如果是在group by中产生了数据倾斜,是否可以讲group by的维度变得更细,如果没法变得更细,就可以在原分组key上添加随机数后分组聚合一次,然后对结果去掉随机数后再分组聚合
在join时,有大量为null的join key,则可以将null转成随机值,避免聚集
(4)count(distinct)
情形:某特殊值过多
后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务
解决方式:count distinct 时,将值为空的情况单独处理,比如可以直接过滤空值的行,
在最后结果中加 1。如果还有其他计算,需要进行 group by,可以先将值为空的记录单独处理,再和其他计算结果进行 union。
注意:有时count(distinct) 会比 group by 效率会高,因为group by 会启动2个job,而时间主要浪费在了数据传输,数据磁盘落地和中间任务的创建上,浪费I/O和网络资源,反而count(distinct)效率要高,那么什么时候 group by 比 count(distinct) 效率高呢,一个是发生数据倾斜,另一个是在数据量特别大的时候,因为count(distinct) 只会启动一个reduce任务,有种千军万马过独木桥的感觉,反而group by 会启动两个job任务,会先缩小数据量。
再者,hive3.0 将hive.optimize.countdistinct 设置为true,也能解决数据倾斜问题。
(5)key本身分布不均
可以在key上加随机数,或者增加reduceTask数量
开启数据倾斜时负载均衡
set hive.groupby.skewindata=true;
思想:就是先随机分发并处理,再按照 key group by 来分发处理。
操作:当选项设定为 true,生成的查询计划会有两个 MRJob。
第一个 MRJob 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 GroupBy Key 有可能被分发到不同的Reduce 中,从而达到负载均衡的目的;
第二个 MRJob 再根据预处理的数据结果按照 GroupBy Key 分布到 Reduce 中(这个过程可以保证相同的原始 GroupBy Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
7. hive小文件问题
小文件的产生有三个地方,map输入,map输出,reduce输出,小文件过多也会影响hive的分析效率:
设置map输入的小文件合并
set mapred.max.split.size=256000000; //一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并) set mapred.min.split.size.per.node=100000000; //一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并) set mapred.min.split.size.per.rack=100000000; //执行Map前进行小文件合并 set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
设置map输出和reduce输出进行合并的相关参数:
//设置map端输出进行合并,默认为true set hive.merge.mapfiles = true //设置reduce端输出进行合并,默认为false set hive.merge.mapredfiles = true //设置合并文件的大小 set hive.merge.size.per.task = 256*1000*1000 //当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。 set hive.merge.smallfiles.avgsize=16000000
8. hive常用的函数
类型转换:
cast(expr as <type>)
日期函数:
to_date(string timestamp)
from_unixtime(bigint unixtime, string format)
date_format(date/timestamp/string ts, string fmt)
nvl(T value, T default_value)
字符函数:
concat(string|binary A, string|binary B...)
concat_ws(string SEP, string A, string B...)
regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT)
split(string str, string pat)
substr(string|binary A, int start) substring(string|binary A, int start)
9. hive中null是如何存储的
hive在底层数据存储Null默认是‘N’中,是由 alter table name SET SERDEPROPERTIES('serialization.null.format' = 'N'); 参数控制的
10. left semi join和left join区别
-
LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。
-
LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方都不行。
-
因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
-
left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。因为右表只有 join key 参与关联计算了,而left join on 默认是整个关系模型都参与计算了
11. 聊聊hive的执行引擎,spark和mr的区别?
内存 vs 磁盘 ?
spark 和 mapreduce 计算都是发生在内存中,区别在于:Mapreduce 需要将中间计算的结果写入磁盘,然后再读取磁盘,从而导致了频繁的磁盘io。
spark则不需要将中间计算结果保存在磁盘,得益于RDD(弹性分布式数据集)和DAG(有向无环图)
DAG记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。
中间结果能够以RDD的形式存放在内存中,且能够从DAG中恢复,大大减少了磁盘IO。
Shuffle
MapReduce在Shuffle时需要花费大量时间进行排序,排序在MapReduce的Shuffle中似乎是不可避免的;
Spark在Shuffle时则只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时;
多进程模型 vs 多线程模型的区别
MapReduce采用了多进程模型,而Spark采用了多线程模型。
多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间。就是说MapReduce的Map Task和Reduce Task是进程级别的,而Spark Task则是基于线程模型的。
mapreduce 中的 map 和 reduce 都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间(假设容器启动时间大概1s,如果有1200个block,那么单独启动map进程事件就需要20分钟)
Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的开销。
12. Hive的执行流程?
-
用户提交查询等任务给Driver。
-
编译器获得该用户的任务Plan。
-
编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
-
编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
-
将最终的计划提交给Driver。
-
Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
-
获取执行的结果。
-
取得并返回执行结果。
四、HBase
1. RegionServer上部署多少个region合适?
主要的压力来源于:
- memStore,因为每个region的每个列簇都有一个memStore,所以region过多,可能导致会频繁触发regionServer级别的阻塞flush,这个时候,基本数据写入服务会被阻塞,而且会带来小文件过多的问题。
- RS故障恢复,region的迁移 需要切分的hlog也过多。线程压力大
- BlockCache, 在一个jvm下,lru会频繁的进行block置换。
- hbase:meta 表维护的region过多,压力有点大。
五、Kafka
1. 如何优雅的关闭kafka,并且这样的好处是什么?
使用 kill -s term $KAFKA_PID 或者 kill -15 $KAFKA_PID 来进行关闭kafka,kafka程序入口有个钩子函数,待 Kafka 进程捕获终止信号的时候会执行这个关闭钩子中的内容。
好处:
- 将日志同步到磁盘里,当重启时,以避免需要做任何的日志恢复。日志恢复需要时间,所以这样可以加快启动。
- 将所有leader分区服务器移动到其他的副本,并且把每个分区不可用的几毫秒的时间降至更低。
其他更多kafka面试题:
https://www.cnblogs.com/erlou96/p/14401394.html
六、Zookeeper
七、spark
1. spark on Yarn,Yarn cluster 和 Yarn client模式区别:
Yarn cluster模式中,一般用于线上生产。应用程序都作为Yarn框架所需要的主应用程序(Application Master),并通过Yarn资源管理器(Yarn ResourceManager)为其分配的一个随机节点上运行。
Yarnclient模式中,一般用于本地代码调试,因为该模型下Spark上下文(Spark-Context)会运行在本地,如Spark Shell和Shark等。
2. spark常见的算子:
spark算子分为transform 和 action :
Transform :
- map
- flatmap
- mapPartitions
- sample(抽样)
- groupByKey
- reduceByKey
- union
- distinct
- join
- sortByKey
- repartition
- coalesce
Action:
- count(统计个数)
- collect(将结果收集到driver,容易oom)
- saveAsText
- take (提取前n个元素)
- first = take(1)
- reduce -> 将RDD内部的数据集按照顺序两两合并,直到产生最后一个值为止,并将其返回。即首先合并前两个元素,将结果与第三个元素合并,以此类推。
- foreach 函数func应用在数据集的每一个元素上,通常用于更新一个累加器,或者和外部存储系统进行交互,例如Redis.
3. repartition 和 coalesce 的区别?
1)关系:
两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle
一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用coalesce
4. map 、flatMap 和 mapPartitions 的区别?
5. reduceByKey和groupBykey的区别
reduceByKey会传一个聚合函数, 相当于 groupByKey + mapValues
reduceByKey 会有一个分区内聚合,而groupByKey没有 最核心的区别
结论:reduceByKey有分区内聚合,更高效,优先选择使用reduceByKey。
6. spark读取hdfs文件的分区数
spark读hdfs文件的分区数由hdfs文件占用的文件块数决定。
例如:如果读取的一个hdfs文件大小为1280MB,可能是存储为10块,那么spark读取这个文件的分区数就是10。spark的并行度是同一时刻进行任务计算的task的最大数量。如果分区数超过了并行度,那么就会排队计算。
比如读取的文件分区数是10,spark任务的并行度是5,同一时刻只会计算5个分区的内容,当某个分区计算完成空出资源之后才会计算其他分区。
7. SparkSession 和 SparkContext 关系
SparkSession是Spark 2.0引如的新概念。
我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。
例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。
SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
8. 使用 saveAsHadoopFile 时生产 _SUCCESS 文件问题
使用 saveAsHadoopFile 保存文件时,有时候会产生 _SUCCESS 文件。使用下面的设置就可以不产生这个文件:
sparkConf.set(“spark.hadoop.mapreduce.fileoutputcommitter.marksuccessfuljobs”, “false”);
9. 关于 Spark Streaming 中 LocationStrategies 的设置
- LocationStrategies.PreferBrokers():仅仅在你 spark 的 executor 在相同的节点上,优先分配到存在 kafka broker 的机器上;
- LocationStrategies.PreferConsistent():大多数情况下使用,一致性的方式分配分区所有 executor 上。(主要是为了分布均匀)
- LocationStrategies.PreferFixed():如果你的负载不均衡,可以通过这两种方式来手动指定分配方式,其他没有在 map 中指定的,均采用 preferConsistent() 的方式分配;
10. cache和checkPoint的比较
都是做 RDD 持久化的
1.缓存,是在触发action之后,把数据写入到内存或者磁盘中。不会截断血缘关系
(设置缓存级别为memory_only:内存不足,只会部分缓存或者没有缓存,缓存会丢失,memory_and_disk :内存不足,会使用磁盘)
2.checkpoint 也是在触发action之后,执行任务。单独再启动一个job,负责写入数据到hdfs中。(把rdd中的数据,以二进制文本的方式写入到hdfs中,有几个分区,就有几个二进制文件)
3.某一个RDD被checkpoint之后,他的父依赖关系会被删除,血缘关系被截断,该RDD转换成了CheckPointRDD,以后再对该rdd的所有操作,都是从hdfs中的checkpoint的具体目录来读取数据。缓存之后,rdd的依赖关系还是存在的。
八、Java
1. intern()
String str1=new StringBuilder("58").append("58").toString(); System.out.println(str1.intern() == str1); // true String str2=new StringBuilder("ja").append("va").toString(); System.out.println(str2.intern() == str2); // false
九、linux
1. 找出/data/目录下大于10k的文件,并将其移动到/databak下
find /data -size +10k -exec mv {} /databak ;
2. 设置linux 默认的文件权限
umask 0022 // 文件默认755,文件夹默认644(少一个可执行)
十、杂谈
1. http 错误状态码:
- 500 服务器内部错误,代码级别的
- 502 错误网关
- 403 - 禁止访问
- 404 - 无法找到文件
2. kerberos 主备切换,数据同步问题
1. 使用kdb5_util dump 备份kdc数据库
2. 在使用kprop -f /var/kerberos/krb5kdc/kdc.dumpkerberos2.example.com
以上命令,可以封装成一个bash,定时运行,即定时更新slave上的database。
3. parquet格式 和 orc格式区别
相同点:都是列式存储,都支持文件索引,都支持压缩
不同点:orc支持acid事务,和update,delete操作,而parquet不支持