转自:https://blog.csdn.net/weixin_37766087/article/details/100940409
说明
这篇文章是来自Hadoop Hive UDAF Tutorial - Extending Hive with Aggregation Functions:的不严格翻译,因为翻译的文章示例写得比较通俗易懂,此外,我把自己对于Hive的UDAF理解穿插到文章里面。
udfa是hive中用户自定义的聚集函数,hive内置UDAF函数包括有sum()与count(),UDAF实现有简单与通用两种方式,简单UDAF因为使用Java反射导致性能损失,而且有些特性不能使用,已经被弃用了;在这篇博文中我们将关注Hive中自定义聚类函数-GenericUDAF,UDAF开发主要涉及到以下两个抽象类:
-
org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver
-
源码链接
博文中的所有的代码和数据可以在以下链接找到:hive examples
示例数据准备
首先先创建一张包含示例数据的表:people,该表只有name一列,该列中包含了一个或多个名字,该表数据保存在people.txt文件中。
~$ cat ./people.txt
John Smith
John and Ann White
Ted Green
Dorothy
把该文件上载到hdfs目录/user/matthew/people中:
hadoop fs -mkdir people
hadoop fs -put ./people.txt people
下面要创建hive外部表,在hive shell中执行
CREATE EXTERNAL TABLE people (name string)
ROW FORMAT DELIMITED FIELDS
TERMINATED BY ' '
ESCAPED BY ''
LINES TERMINATED BY '
'
STORED AS TEXTFILE
LOCATION '/user/matthew/people';
相关抽象类介绍
创建一个GenericUDAF必须先了解以下两个抽象类:
org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
为了更好理解上述抽象类的API,要记住hive只是mapreduce函数,只不过hive已经帮助我们写好并隐藏mapreduce,向上提供简洁的sql函数,所以我们要结合Mapper、Combiner与Reducer来帮助我们理解这个函数。要记住在hadoop集群中有若干台机器,在不同的机器上Mapper与Reducer任务独立运行。
所以大体上来说,这个UDAF函数读取数据(mapper),聚集一堆mapper输出到部分聚集结果(combiner),并且最终创建一个最终的聚集结果(reducer)。因为我们跨域多个combiner进行聚集,所以我们需要保存部分聚集结果。
AbstractGenericUDAFResolver
Resolver很简单,要覆盖实现下面方法,该方法会根据sql传入的参数数据格式指定调用哪个Evaluator进行处理。
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException;
GenericUDAFEvaluator
UDAF逻辑处理主要发生在Evaluator中,要实现该抽象类的几个方法。
在理解Evaluator之前,必须先理解objectInspector接口与GenericUDAFEvaluator中的内部类Model。
ObjectInspector
作用主要是解耦数据使用与数据格式,使得数据流在输入输出端切换不同的输入输出格式,不同的Operator上使用不同的格式。可以参考这两篇文章:first post on Hive UDFs、Hive中ObjectInspector的作用,里面有关于objectinspector的介绍。
Model
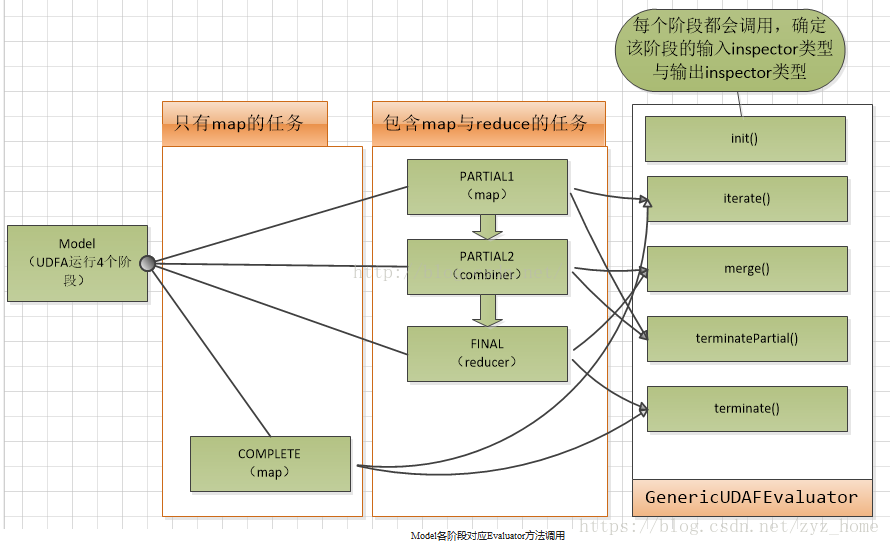
Model代表了UDAF在mapreduce的各个阶段。
public static enum Mode { /** * PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合 * 将会调用iterate()和terminatePartial() */ PARTIAL1, /** * PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合: * 将会调用merge() 和 terminatePartial() */ PARTIAL2, /** * FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合 * 将会调用merge()和terminate() */ FINAL, /** * COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合 * 将会调用 iterate()和terminate() */ COMPLETE };
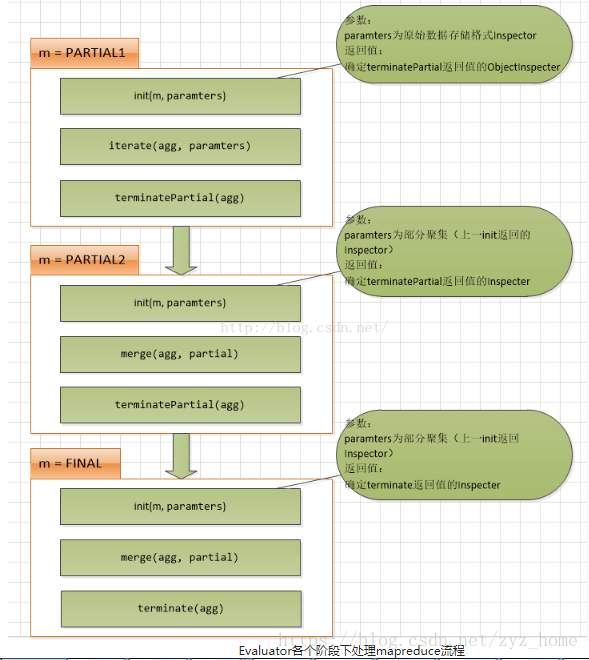
一般情况下,完整的UDAF逻辑是一个mapreduce过程,如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer),如果还有combiner,那就会经历PARTIAL1(mapper),PARTIAL2(combiner),FINAL(reducer)。
而有一些情况下的mapreduce,只有mapper,而没有reducer,所以就会只有COMPLETE阶段,这个阶段直接输入原始数据,出结果。
GenericUDAFEvaluator的方法
// 确定各个阶段输入输出参数的数据格式ObjectInspectors
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException; // 保存数据聚集结果的类 abstract AggregationBuffer getNewAggregationBuffer() throws HiveException; // 重置聚集结果 public void reset(AggregationBuffer agg) throws HiveException; // map阶段,迭代处理输入sql传过来的列数据 public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException; // map与combiner结束返回结果,得到部分数据聚集结果 public Object terminatePartial(AggregationBuffer agg) throws HiveException; // combiner合并map返回的结果,还有reducer合并mapper或combiner返回的结果。 public void merge(AggregationBuffer agg, Object partial) throws HiveException; // reducer阶段,输出最终结果 public Object terminate(AggregationBuffer agg) throws HiveException;
图解Model与Evaluator关系
实例
下面将讲述一个聚集函数UDAF的实例,我们将计算people这张表中的name列字母的个数。
下面的函数代码是计算指定列中字符的总数(包括空格)
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.parse.SemanticException; import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver; import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory.ObjectInspectorOptions; import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo; import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils; import org.apache.hadoop.hive.ql.exec.Description; @Description(name = "letters", value = "_FUNC_(expr) - Returns total number of letters in all the strings of a column.") public class TotalNumOfLettersGenericUDAF extends AbstractGenericUDAFResolver { @Override public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException { if (parameters.length != 1) { throw new UDFArgumentTypeException(parameters.length - 1, "Exactly one argument is expected."); } ObjectInspector oi = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(parameters[0]); if (oi.getCategory() != ObjectInspector.Category.PRIMITIVE){ throw new UDFArgumentTypeException(0, "Argument must be PRIMITIVE, but " + oi.getCategory().name() + " was passed."); } PrimitiveObjectInspector inputOI = (PrimitiveObjectInspector) oi; if (inputOI.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){ throw new UDFArgumentTypeException(0, "Argument must be String, but " + inputOI.getPrimitiveCategory().name() + " was passed."); } return new TotalNumOfLettersEvaluator(); } public static class TotalNumOfLettersEvaluator extends GenericUDAFEvaluator { PrimitiveObjectInspector inputOI; ObjectInspector outputOI; PrimitiveObjectInspector integerOI; int total = 0; @Override public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException { assert (parameters.length == 1); super.init(m, parameters); // init input object inspectors if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) { inputOI = (PrimitiveObjectInspector) parameters[0]; } else { integerOI = (PrimitiveObjectInspector) parameters[0]; } // init output object inspectors // For partial function - array of integers outputOI = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class, ObjectInspectorOptions.JAVA); return outputOI; } /** * class for storing the current sum of letters */ static class LetterSumAgg implements AggregationBuffer { int sum = 0; void add(int num){ sum += num; } } @Override public AggregationBuffer getNewAggregationBuffer() throws HiveException { LetterSumAgg result = new LetterSumAgg(); return result; } @Override public void reset(AggregationBuffer agg) throws HiveException { LetterSumAgg myagg = new LetterSumAgg(); } private boolean warned = false; @Override public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException { assert (parameters.length == 1); if (parameters[0] != null) { LetterSumAgg myagg = (LetterSumAgg) agg; Object p1 = ((PrimitiveObjectInspector) inputOI).getPrimitiveJavaObject(parameters[0]); myagg.add(String.valueOf(p1).length()); } } @Override public Object terminatePartial(AggregationBuffer agg) throws HiveException { LetterSumAgg myagg = (LetterSumAgg) agg; total += myagg.sum; return total; } @Override public void merge(AggregationBuffer agg, Object partial) throws HiveException { if (partial != null) { LetterSumAgg myagg1 = (LetterSumAgg) agg; Integer partialSum = (Integer) integerOI.getPrimitiveJavaObject(partial); LetterSumAgg myagg2 = new LetterSumAgg(); myagg2.add(partialSum); myagg1.add(myagg2.sum); } } @Override public Object terminate(AggregationBuffer agg) throws HiveException { LetterSumAgg myagg = (LetterSumAgg) agg; total = myagg.sum; return myagg.sum; } } }
代码说明
这里有一些关于combiner的资源,Philippe Adjiman 讲得不错。
AggregationBuffer 允许我们保存中间结果,通过定义我们的buffer,我们可以处理任何格式的数据,在代码例子中字符总数保存在AggregationBuffer 。
/** * 保存当前字符总数的类 */ static class LetterSumAgg implements AggregationBuffer { int sum = 0; void add(int num){ sum += num; } }
这意味着UDAF在不同的mapreduce阶段会接收到不同的输入。Iterate读取我们表中的一行(或者准确来说是表),然后输出其他数据格式的聚集结果。artialAggregation合并这些聚集结果到另外相同格式的新的聚集结果,然后最终的reducer取得这些聚集结果然后输出最终结果(该结果或许与接收数据的格式不一致)。在init()方法中我们指定输入为string,结果输出格式为integer,还有,部分聚集结果输出格式为integer(保存在aggregation buffer中);terminate()与terminatePartial()两者输出一个integer。
// init方法中根据不同的mode指定输出数据的格式objectinspector if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) { inputOI = (PrimitiveObjectInspector) parameters[0]; } else { integerOI = (PrimitiveObjectInspector) parameters[0]; } // 不同model阶段的输出数据格式 outputOI = ObjectInspectorFactory .getReflectionObjectInspector(Integer.class, ObjectInspectorOptions.JAVA);
iterate()函数读取到每行中列的字符串,计算与保存该字符串的长度。
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException { ... Object p1 = ((PrimitiveObjectInspector) inputOI).getPrimitiveJavaObject(parameters[0]); myagg.add(String.valueOf(p1).length()); } }
Merge函数增加部分聚集总数到AggregationBuffer
public void merge(AggregationBuffer agg, Object partial) throws HiveException { if (partial != null) { LetterSumAgg myagg1 = (LetterSumAgg) agg; Integer partialSum = (Integer) integerOI.getPrimitiveJavaObject(partial); LetterSumAgg myagg2 = new LetterSumAgg(); myagg2.add(partialSum); myagg1.add(myagg2.sum); } }
Terminate()函数返回AggregationBuffer中的内容,这里产生了最终结果。
public Object terminate(AggregationBuffer agg) throws HiveException { LetterSumAgg myagg = (LetterSumAgg) agg; total = myagg.sum; return myagg.sum; }
使用自定义函数
ADD JAR ./hive-extension-examples-master/target/hive-extensions-1.0-SNAPSHOT-jar-with-dependencies.jar; CREATE TEMPORARY FUNCTION letters as 'com.matthewrathbone.example.TotalNumOfLettersGenericUDAF'; SELECT letters(name) FROM people; OK 44 Time taken: 20.688 seconds
github上一些案例:https://github.com/rathboma/hive-extension-examples