题外话
我第一次听说Python是在大二的时候,那个时候C语言都没有学好,于是就没有心思学其他的编程语言。现在,我的毕业设计要用到爬虫技术,在网上搜索了一下,Python语言在爬虫技术这方面获得一致好评。
所以从昨天开始就在网上查找各种Python爬虫小程序的源码,可是一天过去了,不仅没有写出一个简单的爬虫程序,反而对Python要引入的各种包和语法越来越迷糊了。去菜鸟教程一看,Python语言相对来讲还是蛮复杂的(虽然它的语法很简单,但是对于初学者,很多封装在一个包里的东西都非常陌生),我恶补了一下Python的语法,然后又开始在网上搜寻各种教程,总之把别人写的爬虫入门级程序都敲了一遍,可是还是无一奏效,有各种各样的错误。
可是,今天发现一篇博客,博主很细心的讲了最简单的爬虫有哪些步骤,用到哪些包,包括源码都一句一句进行了分析,于是我的第一个爬虫程序就成功了。下面分享一下这位博主的博客,并写下自己的感受。
博客地址:Python入门(一):爬虫基本结构&简单实例。
我的实践
下面这张图片就是我按照那位博主的代码,得到的结果。虽然过程中出了一点语法错误(完全是我自己的失误),但结果还是成功的获得了网页上的数据,还进行了筛选,并答应了出来。当然打出来的数据有很多,我只截了一小部分。大家看到的最后一个>>>后面的语句for循环语句块,就是将要进行迭代并打印迭代器的内容,这里就不放图了。
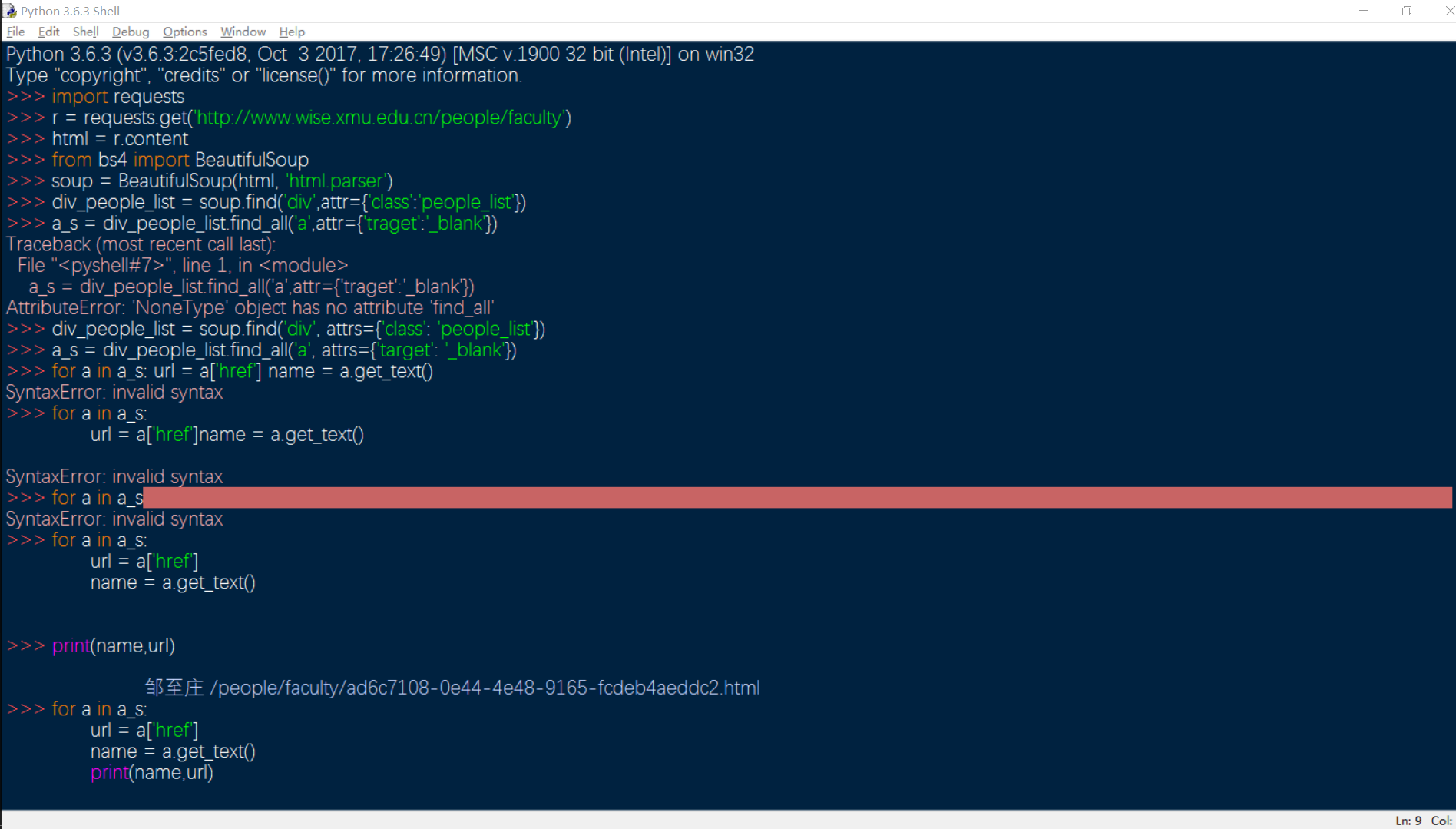
最后的结果就是,所有人的数据都打印出来了。
我的感受就是:Python能做很多事情,搜索引擎就是很大程度上利用了爬虫程序。