周末看到一个很好的片子,非常适合我这种AI/ML的小白用户,便于比较快速的弄清楚这个领域涉及的内容和OpenShift的定位。
这篇文章就把主要的关键点和自己的理解记录如下,供自己参考。
首先,在AI的领域中,模型只是很小的一块,需要依赖于外部很多的技术
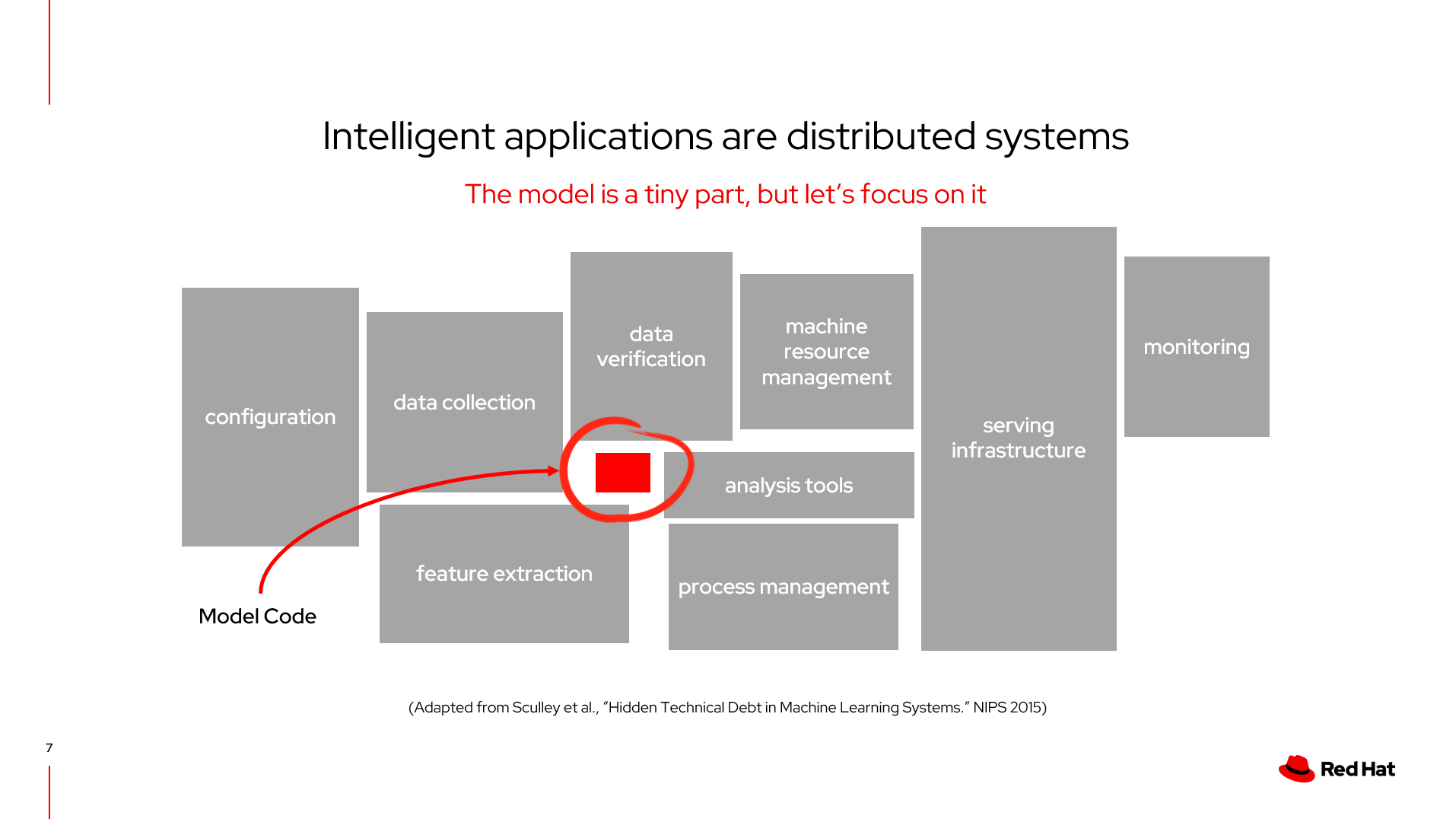
机器学习各个阶段的分工和角色划分
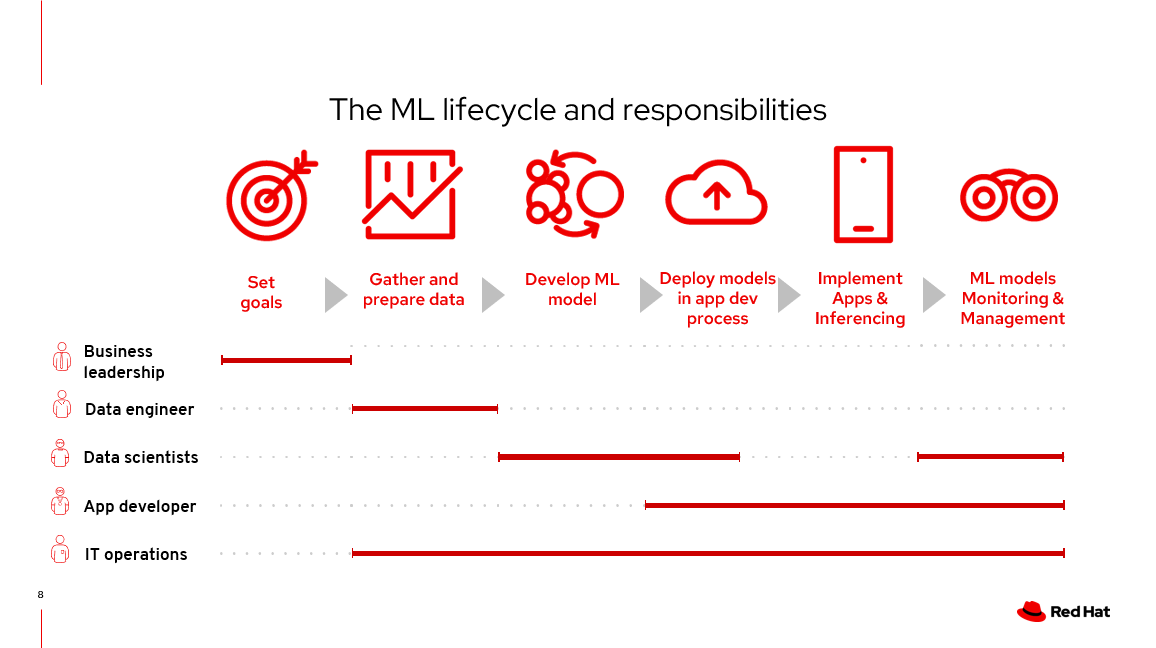
1.模型和验证(数据科学家)
技术领域中涉及的模块

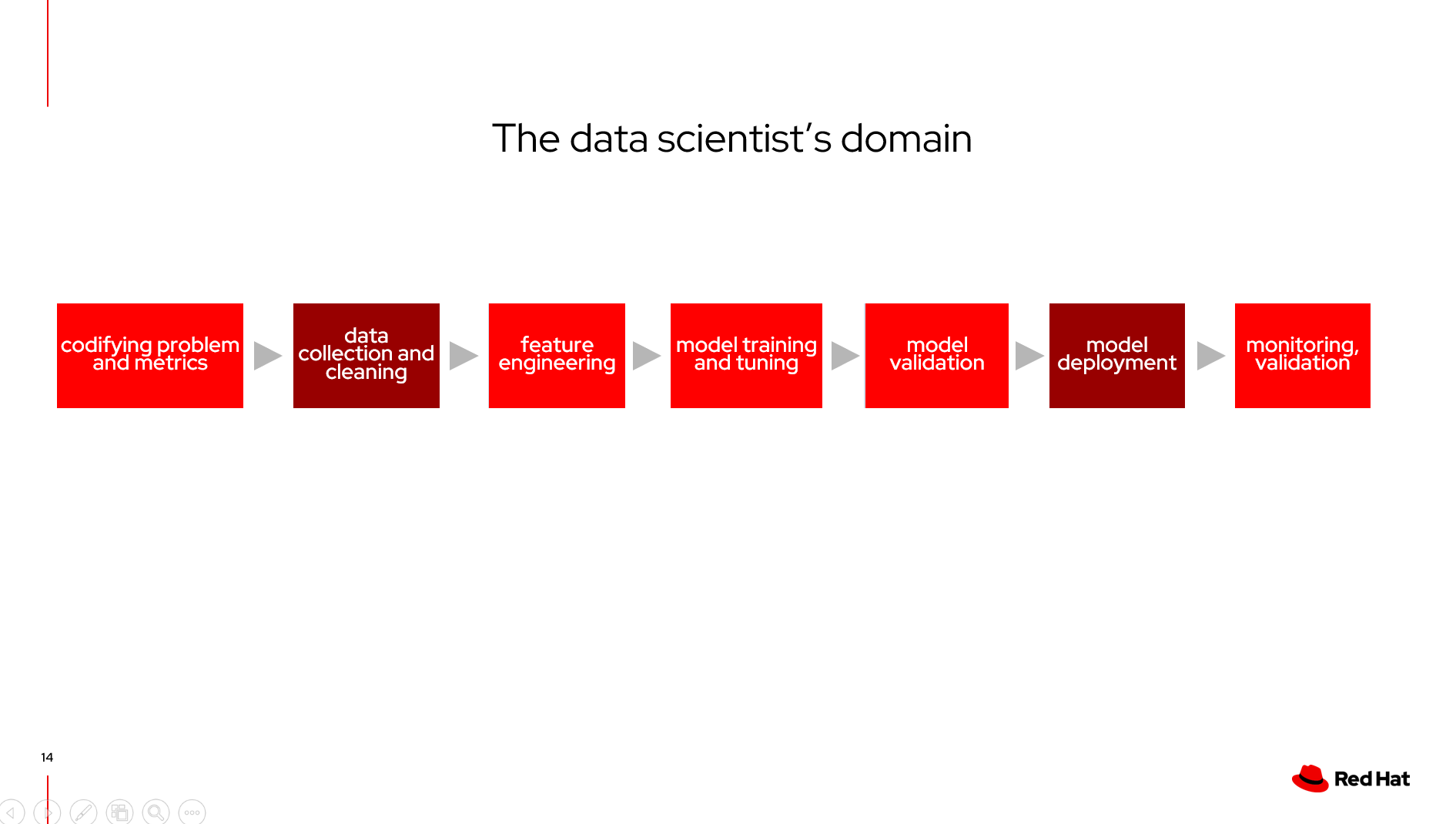
整个模块中,数据科学家的关注点(标记浅红色的部分)
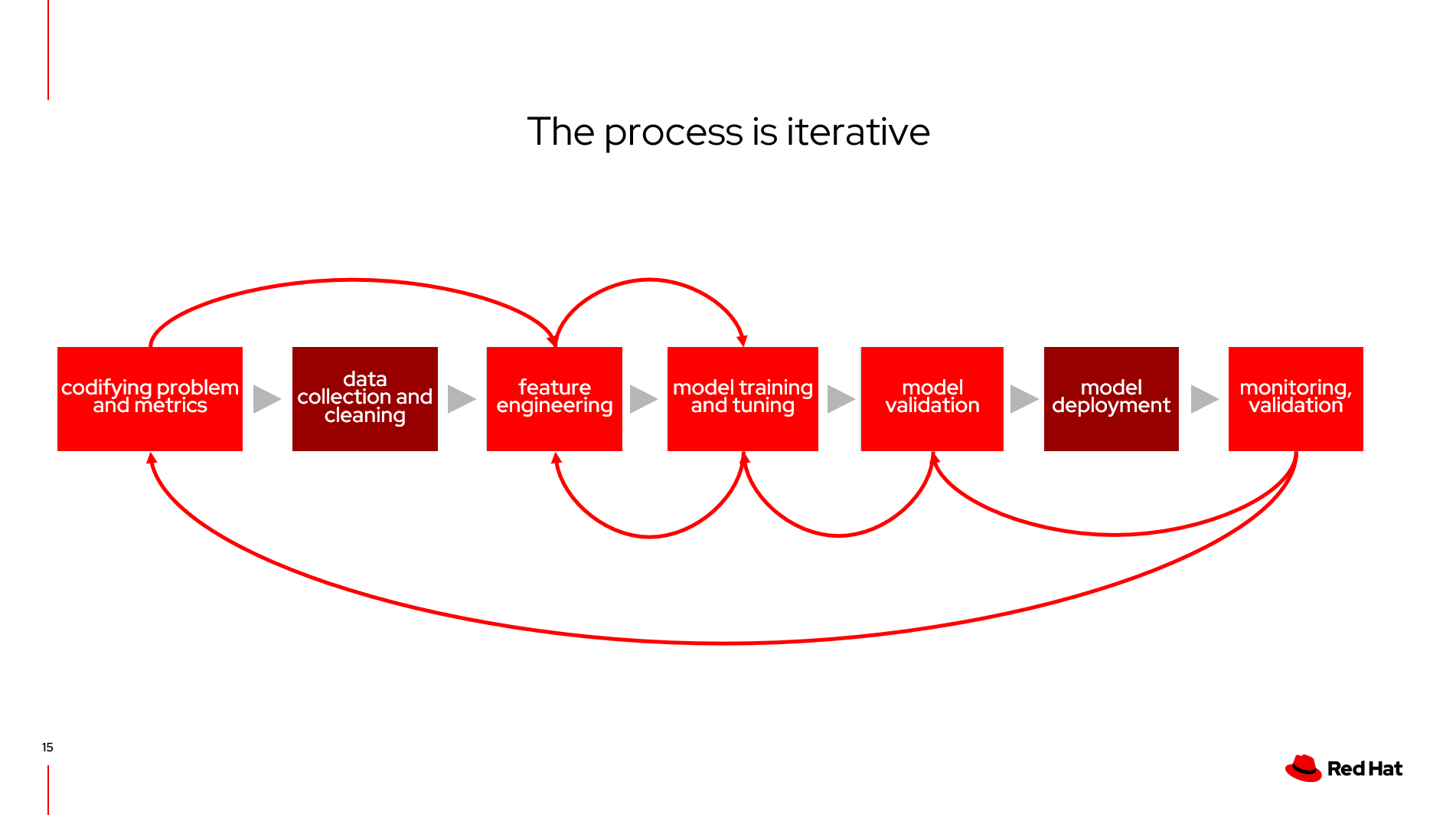
这个过程是一个迭代的过程
Jupyter在这个过程中的定位

这个过程的核心瓶颈

在模型开始阶段,因为涉及到多租户方式使用,需要自服务,需要可以重复和共享的环境,需要可以重复共享的经验,以及如何利用GPU资源提速。
在生产阶段,更快的发布和扩展,如何利用GPU资源提速。

2.环境建立和共享
开始阶段,自然而然的变成容器化模式,进而形成多租户的Jupyter as Service

3.模型部署和运行
而在投产阶段,更快速的形成镜像进行运行和Scale out


OpenDataHub项目覆盖的内容
OpenShift的OpenDataHub项目就是利用这些开源的技术和项目在底层平台上利用Operator形成了自动化的部署和生命周期的管理。
OpenDataHub的架构
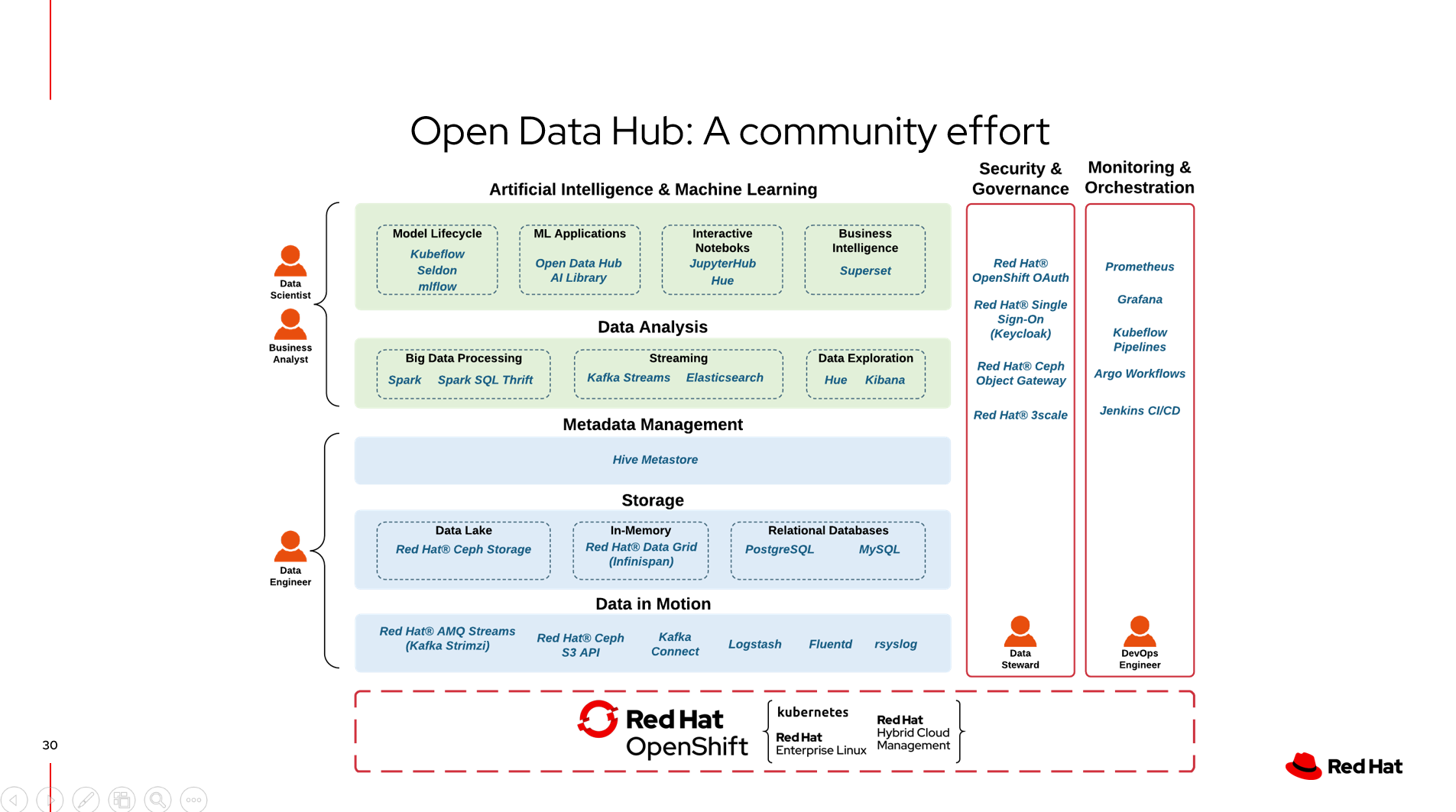
目前,版本是1.1.0,目前支持的项目如下,我在Lab环境中尝试安装了JupyterHub和Spark Cluster, 因为消耗资源比较多所以实验环境被停止了 :(

总体说来,主要价值点在:
- 数据的供应:包括数据存储,数据移动,数据响应
- AI/ML框架支持:各类开源框架基于Operator的部署
- GPU算力支持:支持MIG, 资源共享和资源的控制
- 网络优化:SR-IOV的高性能
总体来说,可以参考这张图
