https://zhuanlan.zhihu.com/p/59327439
从应用开发的角度看,SOCK_STREAM、SOCK_DGRAM 这两类套接字似乎已经足够了。因为基于 TCP/IP 的应用,在传输层的确只可能建立于 TCP 或 UDP 协议之上,而这两种套接字SOCK_STREAM、SOCK_DGRAM 又分别对应于 TCP 和 UDP,所以几乎所有所有的应用都可以使用这两种套接字来实现。
但是,从另外的角度,这两种套接字有一些局限:
- 怎样发送一个 ICMP 协议包?
- 怎样伪装本地的 IP 地址?
- 怎样实现一个新设计的协议的数据包?
这两种套接字的局限在于它们只能处理数据载荷,数据包的头部在到达用户程序的时候已经被移除了。
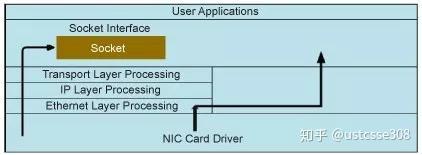
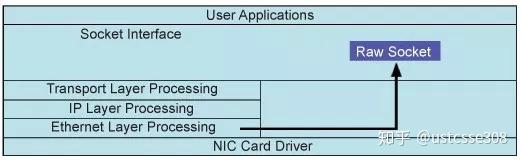
所以,这里我们要引入一个新的socket类型,原始套接字(SOCK_RAW)。原始套接字应用也很广泛,可以实现sniffer【之前使用pcap实现的sniffer也可以使用raw_socket实现】、IP 欺骗等,基于此,可以实现各种攻击。原始套接字之所以能够做到这一点,是因为它可以绕过系统内核的协议栈,使得用户可以自行构造数据包。原始套接字用于接收和发送原始数据包。 这意味着在以太网层接收的数据包将直接传递到原始套接字。 准确地说,原始套接字绕过正常的TCP / IP处理并将数据包发送到特定的用户应用程序。使用 raw套接字可以实现上至应用层的数据操作,也可以实现下至链路层的数据操作。因此也要求比应用开发更高的权限。
创建raw socket
要创建套接字,必须知道套接字族、套接字类型和协议三个方面。
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
int socket(int domain, int type, int protocol);内核中套接字是一层一层进行抽象展示的,把共性的东西抽取出来,这样对外提供的接口可以尽量的统一。内核中把套接字的定义会抽象出来展示,如struct sock->struct inet_sock->struct tcp_sock从抽象到具体。Socket函数中的三个参数其实就是把抽象的socket具体化的条件,domain参数决定了图中所示的第二层通信域,type决定了第三层的通信模式,protocol决定了第四层真正的通信协议。
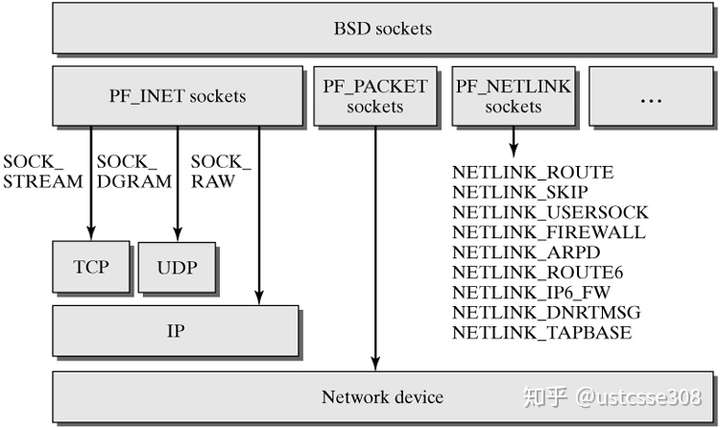
对于原始套接字,domain(family)套接字族可以是AF_INET、PF_INET、AF_PACKET和PF_PACKET;套接字类型是SOCK_RAW;至于协议,可以查阅if_ether.h头文件。 因此,可以看到使用各种参数的组合来创建原始套接字。这也是学习raw socket的时候很容易混淆的一点。

关于AF和PF的区别,上节中已经介绍了。这里,先分析下_NET和_PACKET的区别。
使用man packet,可以查到如下的内容。

使用AF_INET,用户程序无法获得链路层数据,也即,以太网头部。简单来说,使用AF_INET,是面向IP层的原始套接字;使用AF_PACKET,是面向链路层的套接字。
Type就是socket的类型,对于AF_INET协议族而言有流套接字(SOCK_STREAM)、数据包套接字(SOCK_DGRAM)、原始套接字(SOCK_RAW)。
/**
* enum sock_type - Socket types
* @SOCK_STREAM: stream (connection) socket
* @SOCK_DGRAM: datagram (conn.less) socket
* @SOCK_RAW: raw socket
* @SOCK_RDM: reliably-delivered message
* @SOCK_SEQPACKET: sequential packet socket
* @SOCK_DCCP: Datagram Congestion Control Protocol socket
* @SOCK_PACKET: linux specific way of getting packets at the dev level.
* For writing rarp and other similar things on the user level.
*/
enum sock_type {
SOCK_STREAM = 1,
SOCK_DGRAM = 2,
SOCK_RAW = 3,
SOCK_RDM = 4,
SOCK_SEQPACKET = 5,
SOCK_DCCP = 6,
SOCK_PACKET = 10,
};
通过family和type已经基本确定了新建的socket具体是什么类型的套接字,最后一步通过protocol来确定socket到底支持的哪个协议(TCP?UDP?)
【关于这三个参数的详细的组合,需要结合内核源码深入理解,可以阅读参考7。在参考7中分情况讨论:socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); socket(AF_INET, SOCK_STREAM, 0);以及socket(AF_INET, SOCK_RAW, 0)(这个会报错)】
譬如,为了实现sniffer,可以使用下面的代码。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<netinet/ip_icmp.h>
#include<netinet/tcp.h>
#include<netinet/udp.h>
#include<arpa/inet.h>
#include<sys/socket.h>
#include<sys/types.h>
#define BUFFSIZE 1024
int main(){
int rawsock;
char buff[BUFFSIZE];
int n;
int count = 0;
rawsock = socket(AF_INET,SOCK_RAW,IPPROTO_TCP);
// rawsock = socket(AF_INET,SOCK_RAW,IPPROTO_UDP);
// rawsock = socket(AF_INET,SOCK_RAW,IPPROTO_ICMP);
// rawsock = socket(AF_INET,SOCK_RAW,IPPROTO_RAW);
if(rawsock < 0){
printf("raw socket error!
");
exit(1);
}
while(1){
n = recvfrom(rawsock,buff,BUFFSIZE,0,NULL,NULL);
if(n<0){
printf("receive error!
");
exit(1);
}
count++;
struct ip *ip = (struct ip*)buff;
printf("%5d %20s",count,inet_ntoa(ip->ip_src));
printf("%20s %5d %5d
",inet_ntoa(ip->ip_dst),ip->ip_p,ntohs(ip->ip_len));
printf("
");
}
}
为了接收所有分组,可以使用ETH_P_ALL,为了接收IP分组,可以使用ETH_P_IP。
sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))如果第一个参数是AF_PACKET,那么是面向链路层的套接字,第三个参数可以是
- ETH_P_IP - 只接收目的mac是本机的IP类型数据帧
- ETH_P_ARP - 只接收目的mac是本机的ARP类型数据帧
- ETH_P_RARP - 只接收目的mac是本机的RARP类型数据帧
- ETH_P_PAE - 只接收目的mac是本机的802.1x类型的数据帧
- ETH_P_ALL - 接收目的mac是本机的所有类型数据帧,同时还可以接收本机发出的所有数据帧,混杂模式打开时,还可以接收到目的mac不是本机的数据帧
完整代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<netinet/ip_icmp.h>
#include<netinet/tcp.h>
#include<netinet/udp.h>
#include<arpa/inet.h>
#include<sys/socket.h>
#include<sys/types.h>
#include<netinet/ether.h>
#define BUFFSIZE 1024
int main(){
int rawsock;
unsigned char buff[BUFFSIZE];
int n;
int count = 0;
rawsock = socket(AF_PACKET,SOCK_RAW,htons(ETH_P_ALL));
if(rawsock < 0){
printf("raw socket error!
");
exit(1);
}
while(1){
n = recvfrom(rawsock,buff,BUFFSIZE,0,NULL,NULL);
if(n<0){
printf("receive error!
");
exit(1);
}
count++;
struct ip *ip = (struct ip*)(buff+14);
printf("%4d %15s",count,inet_ntoa(ip->ip_src));
printf("%15s %5d %5d
",inet_ntoa(ip->ip_dst),ip->ip_p,n);
int i=0,j=0;
for(i=0;i<n;i++){
if(i!=0 && i%16==0){
printf(" ");
for(j=i-16;j<i;j++){
if(buff[j]>=32&&buff[j]<=128)
printf("%c",buff[j]);
else printf(".");
}
printf("
");
}
if(i%16 == 0) printf("%04x ",i);
printf("%02x",buff[i]);
if(i==n-1){
for(j=0;j<15-i%16;j++) printf(" ");
printf(" ");
for(j=i-i%16;j<=i;j++){
if(buff[j]>=32&&buff[j]<127)
printf("%c",buff[j]);
else printf(".");
}
}
}
printf("
");
}
}
课上有同学提问 IPPROTO_RAW 的socket能不能收包。根据参考6和参考7,在Linux中IP层处理新的传入IP数据报后,它将调用ip_local_deliver_finish()内核函数,该函数负责通过检查IP报头的协议字段来调用注册的传输协议处理程序。在将数据报传递给处理程序之前,它将每次检查应用程序是否使用*相同*协议号创建了原始套接字。 如果存在一个或多个这样的应用程序,它将复制数据报并将其也传递给它们。
具体说,网卡驱动收到报文后在软中断上下文由netif_receive_skb()处理,对于IP报文且目的地址为本机的会由ip_rcv()最终调用ip_local_deliver_finish()函数。ip_local_deliver_finish()中对每一个数据包都会调用raw_local_deliver(),raw_local_deliver()就是原始套接字接收的入口。
原始套接字的接收流程主要是:先根据报文的L4层协议类型hash值在raw_v4_htable表中查找是否有匹配的sock。如果有匹配的sock结构,就进一步调用raw_v4_input()处理网络层原始套接字,在raw_v4_input()中进一步调用__raw_v4_lookup()函数进行匹配,原始套接字的源IP、目的IP、绑定的接口eth等是否匹配,最后调用raw_rcv()。
因此,对数据包进行的第一次筛选就是根据数据包的protocol生成的hash从raw_v4_htable中查找对应的raw socket,从网卡接收回来的数据包的L4层protocol肯定是TCP、UDP、ICMP等有效的值,没有哪个数据包的protocol是IPPROTO_RAW,所以用protocol等于IPPROTO_RAW来新建原始套接字最后生成的hash值也就不会匹配到任何的数据包了。也就是说用IPPROTO_RAW新建的套接字只适合发送,不能接收数据包。
以上内容是sniffer,如果是构造发包的话,使用AF_INET时,那么是面向IP层的套接字,protocol字段定义在netinet/in.h中,常见的包括IPPROTO_TCP、IPPROTO_UDP、IPPROTO_ICMP和IPPROTO_RAW。如果第三个参数是IPPROTO_TCP、IPPROTO_UDP、IPPROTO_ICMP,则我们所构造的报文从IP首部之后的第一个字节开始,IP首部由内核自己维护,首部中的协议字段会被设置为我们调用socket()函数时传递给它的protocol字段。也即,如果没有开启IP_HDRINCL选项,那么内核会帮忙处理IP头部。如果设置了IP_HDRINCL选项,那么用户需要自己生成IP头部的数据,其中IP首部中的标识字段和校验和字段总是内核自己维护。可以通过下面代码开启IP_HDRINCL:
const int on = 1;
if(setsockopt(fd,SOL_IP,IP_HDRINCL,&on,sizeof(int)) < 0)
{
printf("set socket option error!
");
}同时,如果第一个参数是AF_INET,最后一个IPPROTO_RAW的含义需要额外说明一下:
使用原始套接字编写底层网络程序时,最重要的决策之一是应用程序是否与传输级协议头,IP头一起构建。现在,告诉IP层不要预先添加自己的头的明显方法是调用setsockopt系统调用并设置IP_HDRINCL(包含头)选项。但是,并不总是存在此选项。在Net/3之前的版本中,没有IP_HDRINCL选项,并且没有内核预先添加自己的头的唯一方法是使用特定的内核补丁并将协议设置为IPPROTO_RAW。这些补丁最初是为4.3BSD和Net / 1制作的,以支持需要编写自己的完整IP数据报的Traceroute,因为它需要修改TTL字段。有趣的是,自从IP_HDRINCL出现以来,Linux和FreeBSD选择了不同的方式来继续“传统”。在Linux上将协议设置为IPPROTO_RAW时,默认情况下,内核会设置IP_HDRINCL选项,因此不会在其前面加上自己的IP头。
总结一下,对于socket的第一个参数,因为AF_INET、PF_INET、AF_PACKET和PF_PACKET中AF和PF基本等价,所以只需要区分_NET和_PACKET就行;第二个参数是一般是sock_raw;关于第三个参数,取决于第一个参数。
- 新建socket时候指定的protocol(如:IPPROTO_TCP、IPPROTO_UDP)在发送时没有用到,并不会用指定的protocol来填充IP头部,因为我们设置了IP_HDRINCL来指明由我们自己来填充IP头部。
- 发送的数据没有再经过IP层,最后直接调用dst_output发送数据报了,所以如果发送的数据报长度超过了MTU那么不会有IP分片产生,发送失败,返回EMSGSIZE错误码。 相反的如果没有设置IP_HDRINCL来由我们自己定义IP头部,那么流程会走到ip_append_data函数进行IP分片。
- 发送的数据报没有经过TCP层
实现自己的ping程序
下面我们通过一个简单的例子,实现自己的ping程序,来学习使用原始套接字。
首先,确定我们要使用的socket的类型,ping是ICMP协议,目前不需要篡改IP地址,所以,我们的参数可以使用:
sockfd = socket(AF_INET,SOCK_RAW,IPPROTO_ICMP);首先,回顾一下ping数据包的结构:
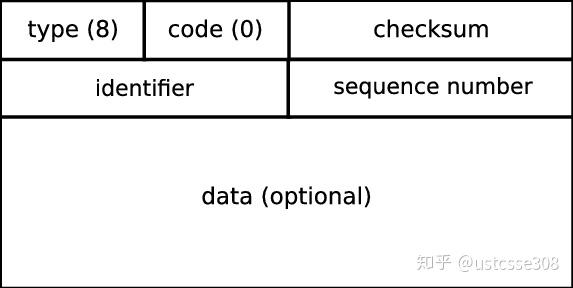
然后,查看一下icmp结构体(/usr/include/netinet/ip_icmp.h),可以找到这样的结构体:
struct icmp
{
u_int8_t icmp_type; /* type of message, see below */
u_int8_t icmp_code; /* type sub code */
u_int16_t icmp_cksum; /* ones complement checksum of struct */
union
{
u_char ih_pptr; /* ICMP_PARAMPROB */
struct in_addr ih_gwaddr; /* gateway address */
struct ih_idseq /* echo datagram */
{
u_int16_t icd_id;
u_int16_t icd_seq;
} ih_idseq;
u_int32_t ih_void;
....
}icmp_hun因为不同的ICMP数据包中内容不同,所以有不少的联合体,为了好用,专门重定义:
#define icmp_id icmp_hun.ih_idseq.icd_id
#define icmp_seq icmp_hun.ih_idseq.icd_seq这些字段就是我们构造ping request所需要用到的字段。
icmp = (struct icmp*)sendbuff;
icmp->icmp_type = ICMP_ECHO;
icmp->icmp_code = 0;
icmp->icmp_cksum = 0;
icmp->icmp_id=2;
icmp->icmp_seq=3;
当然,上面的cksum没有正确计算,id和seq也不对。但即使是这样,当运行时,也能发出去可以被wireshark识别的ping包。
完整代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<sys/socket.h>
#include<sys/types.h>
#include<netinet/ip.h>
#include<netinet/ip_icmp.h>
struct sockaddr_in target, from;
int main(int argc, char ** argv){
int sockfd;
char sendbuff[8];
struct icmp * icmp;
sockfd = socket(AF_INET,SOCK_RAW,IPPROTO_ICMP);
icmp = (struct icmp*)sendbuff;
icmp->icmp_type = ICMP_ECHO;
icmp->icmp_code = 0;
icmp->icmp_cksum = 0;
icmp->icmp_id=2;
icmp->icmp_seq=3;
printf("buff is %x.
",*sendbuff);
if(argc!=2)
{
printf("Usage:%s targetip",argv[0]);exit(1);
}
if(inet_aton(argv[1],&target.sin_addr)==0){
printf("bad ip address %s
",argv[1]);
exit(1);
}
while(1){
sendto(sockfd,sendbuff,8,0,(struct sockaddr *)&target,sizeof(target));
sleep(1);
}
close(sockfd);
return 0;
}
运行:

使用wireshark抓包:

wireshark中指出了checksum不正确。
接下来可以进行改进,增加checksum,以及增加接收回复的部分:
//This is a ping which can both send and receive ICMP packets
#include <sys/types.h>
#include <unistd.h>
#include <errno.h>
#include <signal.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <linux/tcp.h>
#include <netinet/ip_icmp.h>
#include<strings.h>
#include <stdio.h>
#include <stdlib.h>
#include<string.h>
#include <arpa/inet.h>
char buff[28]={0};
int sockfd;
struct sockaddr_in target;
struct sockaddr_in source;
unsigned short in_cksum(unsigned short *addr, int len)
{
int sum=0;
unsigned short res=0;
while( len > 1) {
sum += *addr++;
len -=2;
// printf("sum is %x.
",sum);
}
if( len == 1) {
*((unsigned char *)(&res))=*((unsigned char *)addr);
sum += res;
}
sum = (sum >>16) + (sum & 0xffff);
sum += (sum >>16) ;
res = ~sum;
return res;
}
int main(int argc, char * argv[]){
int send, recv,i;
send = 0;
recv = 0;
i = 0;
if(argc != 2){
printf("usage: %s targetip
", argv[0]);
exit(1);
}
if(inet_aton(argv[1],&target.sin_addr)==0){
printf("bad ip address %s
",argv[1]);
exit(1);
}
int recvfd = socket(AF_INET,SOCK_RAW,IPPROTO_ICMP);
struct icmp * icmp = (struct icmp*)(buff);
if((sockfd=socket(AF_INET,SOCK_RAW,IPPROTO_ICMP))<0)
{ perror("socket error!");exit(1); }
icmp->icmp_type = ICMP_ECHO;
icmp->icmp_code = 0;
icmp->icmp_cksum = 0;
icmp->icmp_id = 2;
icmp->icmp_seq = 3;
while(send < 4)
{
send++;
icmp->icmp_seq = icmp->icmp_seq+1;
icmp->icmp_cksum = 0;
icmp->icmp_cksum = in_cksum((unsigned short *)icmp,8);
sendto(sockfd, buff, 28,0,(struct sockaddr *)&target,sizeof(target));
sleep(1);
}
struct sockaddr_in from;
int lenfrom = sizeof(from);
char recvbuff[1024];
int n;
while(recv<4){
memset(recvbuff,0,1024);
if((n = recvfrom(recvfd,recvbuff,sizeof(recvbuff),0,(struct sockaddr *)&from,&lenfrom))<0) {perror("receive error!
");exit(1);};
struct ip *ip=(struct ip *)recvbuff;
struct icmp *icmp = (struct icmp*)(ip+1);
printf("n is %d,ip header length is %d
",n,ip->ip_hl);
if((n-ip->ip_hl*4)<8) {printf("Not ICMP Reply!
");break;}
printf("ttl is %d
",ip->ip_ttl);
printf("protocol is %d
",ip->ip_p);
if((icmp->icmp_type==ICMP_ECHOREPLY)&&(icmp->icmp_id==2)){
printf("%d reply coming back from %s: icmp sequence=%u ttl=%d
",recv+1,inet_ntoa(from.sin_addr),icmp->icmp_seq,ip->ip_ttl);
printf("src is %s
",inet_ntoa(ip->ip_src));
printf("dst is %s
",inet_ntoa(ip->ip_dst));
recv++;}
}
return 0;
}
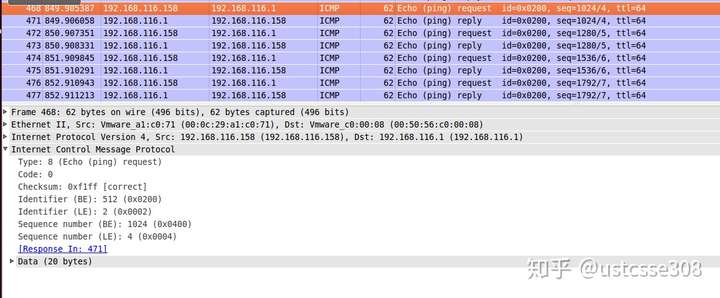
可以看到wireshark中能够收到回复:
安全问题:
如果需要对所有使用raw socket的程序都设置root访问权限,那么有可能程序可以对系统造成严重损害,特别足够复杂的网络程序,可能很容易出现错误。
Linux Capabilities
为了解决root权限问题,Linux推出了capability这一功能,程序不必以完全root访问权限运行。简而言之,capability是对root权限的细分。譬如raw socket就只需要root权限中很少一部分功能,也即CAP_NET_RAW。这样的话,以前仅限于以root用户身份运行的进程(使用sudo)的某些功能由非特权进程使用,只要相关的capability打开就行。
使用setcap命令在每个文件的基础上设置相应的capability。 此示例将CAP_NET_RAW和CAP_NET_ADMIN功能应用于a.out二进制文件。 一旦在文件上设置了这些功能,非root用户就可以运行这些程序。
$ sudo setcap cap_net_admin,cap_net_raw=eip a.out可以检查一下:
$ sudo getcap a.out
a.out = cap_net_admin,cap_net_raw+eip【2020年check】更新为
yan@ubuntu:/bin$ ll ping
-rwxr-xr-x 1 root root 44168 May 8 2014 ping*
yan@ubuntu:/bin$ sudo setcap cap_net_raw=eip ping
yan@ubuntu:/bin$ ping localhost
PING localhost (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.022 ms
64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.029 ms
64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.070 ms
注意:
不能简单地理解IPPROTO_IP就是用于IP协议;它的值为0。详见参考4.
In thein.hfile, the comment says:Dummy protocol for TCP.
This constant has the value 0. It's actually anautomatic choice depending on socket type and family.
If you use it, and if the socket type isSOCK_STREAMand the family isAF_INET, then the protocol will automatically be TCP (exactly the same as if you'd used IPPROTO_TCP). Buf if you useIPPROTO_IPtogether withAF_INETandSOCK_RAW, you will have an error, because the kernel cannot choose a protocol automatically in this case.
参考:
- A Guide to Using Raw Sockets - open source for you
- https://blog.csdn.net/banruoju/article/details/61925346
- https://github.com/ia/connect/blob/master/docs/sock_raw.txt
- https://stackoverflow.com/questions/24590818/what-is-the-difference-between-ipproto-ip-and-ipproto-raw
- https://blog.csdn.net/liuxingen/article/details/45622517
- https://sock-raw.org/papers/sock_raw