一、解决的问题
采用传统编码器-解码器结构的LSTM/RNN模型存在一个问题,不论输入长短都将其编码成一个固定长度的向量表示,这使模型对于长输入序列的学习效果很差(解码效果很差)。
- 注意下图中,ax 和 axx 部分。
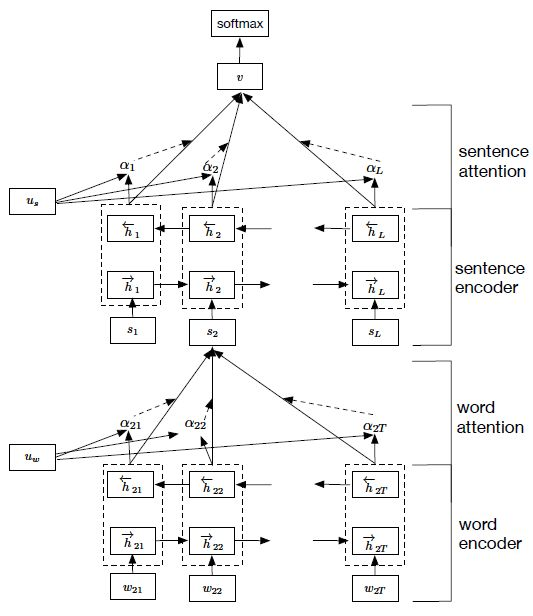
- 公式如下

科普:
http://www.jeyzhang.com/understand-attention-in-rnn.html
一文读懂Attention: https://mp.weixin.qq.com/s/0SWcAAiuN3BYtStDZXyAXg
二、基于Keras代码:
Attention Layer: https://gist.github.com/cbaziotis/6428df359af27d58078ca5ed9792bd6d
Github讨论
How to add Attention on top of a Recurrent Layer (Text Classification) #4962
可视化Attention权重:https://github.com/philipperemy/keras-attention-mechanism
三、应用
Text Classification, - Hierarchical attention network
