对文本对抗性样本的研究极少,近期论文归纳如下:
文本对抗三个难点:
- text data是离散数据,multimedia data是连续数据,样本空间不一样;
- 对text data的改动可能导致数据不合法;
- 基于word的改动(替换、增、删)会有语义兼容性的问题;
论文:
Deep Text Classification Can be Fooled 和 Towards Crafting Text Adversarial Samples:
针对文本分类生成对抗样本——对输入文本进行增删改处理,使得文本分类出现分类错误
- 两篇文章都提出:用梯度来度量word对分类的影响程度;
![]()
- 第二篇文章还提出可以用后验概率来计算对分类的影响,不过这种方法计算每个word会很耗时;
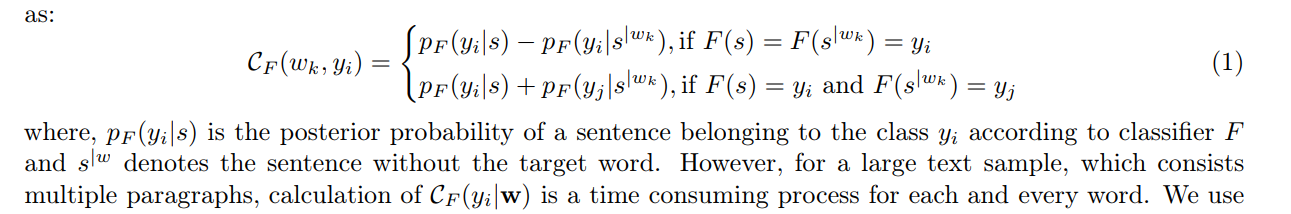
- 产生同义词候选集用到的词向量,需要经过后处理,在这篇文章中提出:

可以在后处理过的词向量空间中采用KNN等算法,找到N个最接近的同义词

Adversarial Examples for Evaluating Reading Comprehension Systems:
针对QA系统生成对抗样本——对原文paragraph增添句子,让QA系统回答错误