-->Title: 淺議SQL Server执行计划
-->Author: wufeng4552
-->Date :2009-10-20 15:08:24
前言:
最近溫習了執行計劃方面的部份知識,為了加深印象與方便初學者,特做了如下整理.
不對地方歡迎提出並指正.
查看执行计划的方式:
(1)菜單方式:
(1.1)显示实际执行计划
(1.2)显示预估的执行计划
以上兩種均位於位于”查询”下拉菜单中,两者的不同之处在于当实际运行一个查询时,当前的服务器上的运算也会被考虑进 去。大多数情况下,两种方式产生的执行计划产生的结果是相似的.
(2)命令方式
SET SHOWPLAN_TEXT ON
这条命令被执行后,所有在当前这个查询分析器会话中执行的查询都不会运行,而是会显示一个基于文本的执行计划
注意:执行某条用 到临时表的查询时,必须在执行查询先运行SET STATISTICS PROFILE ON语句 如:
go
if not object_id('tempdb..#t') is null
drop table #t
Go
Create table #t([日期] Datetime,[姓 名] nvarchar(2))
Insert #t
select '2009-10-01',N'张三' union all
select '2009-10-01',N'李四' union all
select '2009-10-02',N'赵六'
Go
SET STATISTICS PROFILE ON
go
select * from #T
SET STATISTICS PROFILE OFF
結果如圖1

圖1
為了討論方便 下 面以 Northwind 庫中表 [Order Details] 為例(我已經將主鍵刪除)
use Northwind
go
SET SHOWPLAN_TEXT ON
go
select ProductID,sum(Quantity)Quantity from [Order Details]
group by ProductID order by ProductID
go
SET SHOWPLAN_TEXT OFF
/*
StmtText
|--Sort(ORDER BY:([Northwind].[dbo].[Order Details].[ProductID] ASC))
|--Hash Match(Aggregate, HASH:([Northwind].[dbo].[Order Details].[ProductID]) DEFINE:([Expr1004]=SUM([Northwind].[dbo].[Order Details].[Quantity])))
|--Table Scan(OBJECT:([Northwind].[dbo].[Order Details]))
*/
use Northwind
go
----建一个聚集索引
CREATE CLUSTERED INDEX INDEX_ProductID on [Order Details](ProductID)
go
SET SHOWPLAN_TEXT ON
go
select ProductID,sum(Quantity)Quantity from [Order Details]
group by ProductID order by ProductID
go
SET SHOWPLAN_TEXT OFF
/*
StmtText
---------------------------------------
|--Stream Aggregate(GROUP BY:([Northwind].[dbo].[Order Details].[ProductID]) DEFINE:([Expr1004]=SUM([Northwind].[dbo].[Order Details].[Quantity])))
|--Clustered Index Scan(OBJECT:([Northwind].[dbo].[Order Details].[INDEX_ProductID]), ORDERED FORWARD)
(2 個資料列受到影響)
*/
如果在执行计划中看到如下所示的任何一项,从性能方面来说,下面所 示的每一项都是不理想的。
Index or table scans(索引或者表扫描):可能意味着需要更好的或者额外的索引。
Bookmark Lookups(书签查找):考虑修改当前的聚集索引,使用复盖索引,限制SELECT语句中的字段数量。
Filter(过滤):在WHERE从句中移除用到的任何函数,不要在SQL语句中包含视图,可能需要额外的索引。
Sort(排序):数据是否真的需要排序?可否使用索引来避免排序?在客户端排序是 否会更加有效率?
以上事項避免得越多,查询性能就会越快.
注 意:如果有在存储过程中或者其它T-SQL批处理代码中用到了临时表, 就不能在查询分析器或Management Studio使用”显示预估的执行计划”选项来评估查询。必须实际运 行这个存储过程或者批处理代码。这是因为使用”显示预估的执行计划”选项来运行一个查询时,它并没有实际被运行,临时表也没有创建。由于临 时表没有被创建,参考到临时表的代码就会失败,导致预估的执行计划不能成创建成功。从另一方面来说,如果使用的是表变量而不是临时表,则可以使用”显示预估的执行计划”选项.
use Northwind
go
select a.* from [orders] a,[Order Details] b
where a.OrderID=b.OrderID
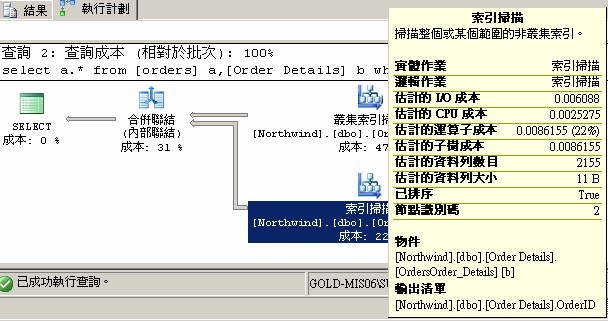
圖2
查看执行计划时记住如下几点:
(1) 非常复杂的执行计划会被分成多个部分,它们分别列出在屏幕上。每 个部分分别代表查询优化器为了得到最终结果而必须执行的单个处理或步骤。执行计划的每个步骤经常会被拆分成一个个更小的子步骤。不幸的是,它们是从右至左 显示在屏幕上的。这意味着你必须滚动到图形执行计划的最右边去查看每个步骤是从哪儿开始的
(2) 每个步骤与子步骤间通过箭头连接,藉此显示查询执行的路径。
(3) 最后,查询的所有部分在屏幕顶部的左边汇总到一起,如果将鼠标移动到连接步骤或子步骤的箭头上,就可以看到一个弹出 式窗口,上面显示有多少笔记录从一个步骤或子步骤移动到另一个步骤或子步骤(如圖3) 如果将 鼠标移动到任何执行计划任何步骤或者子步骤的上面,就会显示一个弹出式窗口,上面显示该步骤或子步骤的更加详细的信息如圖2彈出窗口

圖3
(4) 图形执行 计划上连接每个图标的箭头粗细不同(如圖3)。箭头的粗细 表示每个图标之间移动的数据行数量以及数据行大小移动所需的相对本。箭头越粗,相对成本就越高。可以使用这个指示器来快速 测量一个查询。你可能会特别关注粗箭头以了解它如何影响到查询的效能。例如,粗线头应该在图形执行计划的右边,而非左边。如果看到它们在左边,就意味着太 多的数据行被返回,这个执行计划也不是最佳的执行计划.
(5) 执 行计划的每个部分都被分配了一个成本百分比(如圖2,3)。它表示这个部 分耗用了整个执行计划的多少资源。当对一个执行计划进行分析的时候,应该将精力集中于有着高成本百分比的那些部分。这样就可以在有限的时间里找到可能性最 大的问题,从而回报了你在时间上的投资.
(6) 你 可能会注意到一个执行计划的某些部分被执行了不止一次。作为执行计划分析的一部分,应该将你的一些时间集中在任何执行了超过一次 的那些部分上,看看是否有什么方式减少它们执行的次数。执行的次数越少,查询的速度就越快。
(7) I/O 与CPU成本。查询优化器使用这些数字来做出最佳选择。它们可用来参考的一个意义是,较小的I/O或CPU成本比较大 的I/O或CPU成本使用更少的服务器资源.
use Northwind
go
--刪除聚集索引
DROP INDEX [Order Details].INDEX_ProductID
--CREATE CLUSTERED INDEX INDEX_ProductID ON [Order Details](ProductID)
SET STATISTICS IO ON
select * from [Order Details] where ProductID=42
SET STATISTICS IO OFF
資料表'Order Details'。掃描計數1,邏輯讀取11,實體讀取0,讀取前讀取0,LOB 邏輯讀取0,LOB 實體讀取0,LOB 讀取前讀取0。
use Northwind
go
--刪除聚集索引
--DROP INDEX [Order Details].INDEX_ProductID
--建立聚集索引
CREATE CLUSTERED INDEX INDEX_ProductID ON [Order Details](ProductID)
go
SET STATISTICS IO ON
select * from [Order Details] where ProductID=42
SET STATISTICS IO OFF
資料表'Order Details'。掃描計數1,邏輯讀取2,實體讀取0,讀取前讀取0,LOB 邏輯讀取0,LOB 實體讀取0,LOB 讀取前讀取0。
以上可以看出邏輯讀相差很大,由此可以通过SET STATISTICS IO ON 来查看逻辑读,完成同一功能的不同SQL语句,逻辑读越小查询速度越快
(8)将鼠标移到图形执行计划上的表名(以及它的图 标)上面,就会弹出一个窗口,从它上面可以看到一些信息。这些信息让你知道是否有用到索引来从表中获取数据, 以及它是如何使用的。这些信息包括:
(8.1)Table Scan(表扫描):如果看到这 个信息,就说明数据表上没有聚集索引,或者查询优化器没有使用索引来查找。意即资料表的每一行都被检查到。如果资料表相对较小的话,表扫描可以非常快速, 有时甚至快过使用索引。因此,当看到有执行表扫描时,第一件要做的事就是看看数据表有多少数据行。如果不是太多的话,那么表扫描可能提供了最好的总体效 能。但如果数据表大的话,表扫描就极可能需要长时间来完成,查询效能就大受影响。在这种情况下,就需要仔细研究,为数据表增加一个适当的索引用于这个查 询。假设你发现某查询使用了表扫描,有一个合适的非聚集索引,但它没有用到。这意味着什么呢?为什么这个索引没有用到呢?如果需要获得的数据量相对数据表 大小来说非常大,或者数据选择性不高(意味着同一个字段中重复的值很多),表扫描经 常会比索引扫描快。例如,如果一个数据表有10000个数据行,查询返回1000行,如果这 个表没有聚集索引的话,那么表扫描将比使用一个非聚集索引更快。或者如果数据表有10000个数据行,且 同一个字段(WHERE条件句有用到这个字段)上有1000笔重复的数 据,表扫描也会比使用非聚集索引更快。查看图形执行计划上的数据表上的弹出式窗口时,请注意”预估的资料 行数(Estimated Row Count)”。这个数字是查询优化器作出的多少个数据行会被返回的最 佳推测。如果执行了表扫描且”预估的数据行数”数值很高的 话,就意味着返回的记录数很多,查询优化器认为执行表扫描比使用可用的非聚集索引更快
(8.2)Index Seek(索引查找):索引查找意 味着查询优化器使用了数据表上的非聚集索引来查找数据。性能通常会很快,尤其是当只有少数的数据行被返回时
(8.3)Clustered Index Seek(聚集索引查找):这指查询 优化器使用了数据表上的聚集索引来查找数据,性能很快。实际上,这是SQL Server能做的最快的 索引查找类型
(8.4)Clustered Index Scan(聚集索引扫描):聚集索引 扫描与表扫描相似,不同的是聚集索引扫描是在一个建有聚集索引的数据表上执行的。和一般的表扫描一样,聚集索引扫描可能表明存在效能问题。一般来说,有两 种原因会引此聚集索引扫描的执行。第一个原因,相对于数据表上的整体数据行数目,可能需要获取太多的数据行。查看”预估的数据 行数量(Estimated Row Count)”可以对此加以验证。第二个原因,可能是由于WHERE条件句中用 到的字段选择性不高。在任何情况下,与标准的表扫描不同,聚集索引扫描并不会总是去查找数据表中的所有数据,所以聚集索引扫描一般都会比标准的表扫描要 快。通常来说,要将聚集索引扫描改成聚集索引查找,你唯一能做的是重写查询语句,让语句限制性更多,从而返回更少的数据行
(9)绝大多数情况下,查询优化器会对连接进行分析,按最有效率的顺序,使用最有效率 的连接类型来对数据表进行连接。但并不总是如此。在图形执行计划中你可以看到代表查询所使用到的各种不同连接类型的图标。此外,每个连接 图标都有两个箭头指向它。指向连接图标的上面的箭头代表该连接的外部表,下面的箭头则代表这个连接的内部表。箭头的另一头则指向被连接的数据表名。有时在 多表连接的查询中,箭头的另一头指向的并不是一个数据表,而是另一个连接。如果将鼠标移到指向外部连接与内部连接的箭头上,就可以看到一个弹出式窗口,告 诉你有多少数据行被发送至这个连接来进行处理。外部表应该总是比内部表含有更少的数据行。如果不是,则说明查询优化器所选择的连接顺序可能不正确
(10) 查看图形执行计划时,你可能会发现某个图标的文字用红色显示,而非通常情 况下的黑色。这意味着相关的表的一些统计数据遗失,统计数据是查询优化器生成一个好的执行计划所必须的, 遗失的统计 数据可以通过右键这个图标,并选择”创建遗失的统计资料”来创建。这 时会弹出”创建遗失的统计数据”对话框,通过 它可以很容易地创建遗失的统计数据。 当可以选择去更新遗失的统计资料时,应该总是这样做,因为这样极有可能让你正在分析的查 询语句从中获得效能上的好处
(11) 有时你会在图形执行计划上看到标识了”Assert”的图标。这意味着查 询优化器正在验证查询语句是否有违反引用完整性或者条件约束。如果没有,则没有问题。但如果有的话,查询优化器将无法为该查询建立执行计划,同时会产生一 个错误
(12) 你常常会在图形执行计划上看到标识成”书签查找(Bookmark Lookup)”的图标。书签查找相当常见。书签查找的本质是告诉你查询处理器必 须从数据表或者聚集索引中来查找它所需要的数据行,而不是从非聚集索引中直接读取。 打比方说,如 果一个查询语句的SELECT,JOIN以及WHERE子句中的所有 字段,都不存在于那个用来定位符合查询条件的数据行的非聚集索引中,那么查询优化器就不得不做额外的工作在数据表或聚集索引中查找那些满足这个查询语句的 字段。另一种引起书签查找的原因是使用了SELECT *。由于在绝大多情况下它会返回比你实际所需更多的数据, 所以应该永不使用SELECT *. 从性能方面来说,书签查找是不理想的。因为它会请求额外 的I/O开销在字段中查找以返回所需的数据行。 如果认为书 签查找防碍了查询的性能,那么有四种选择可以用来避免它:可以建立WHERE子句会用到的 聚集索引,利用索引交集的优势,建立覆盖的非聚集索引,或者(如果是SQL Server 2000/2005企业版的话)可以建立索引视图。如果这些都不可能,或者使用它们中的 任何一个都会耗用比书签查找更多的资源,那么书签查找就是最佳的选择了。
(13) 有时查询优化器需要在tempdb数据库中建立临时工作表。如果是这样 的话,就意味着图形执行计划中有标识成Index Spool, Row Count Spool或者Table Spool的图标。 任何时候,使用到工作表一般都会防碍到性能,因为需要额外的I/O开销来维护 这个工作表。理想情况下应该不要用到工作表。不幸的是并不能总是避免用到工作表。有时当使用工作表比其它选择更有效率时,它的使用实际上会增强性能。不论 何种情况,图形执行计划中的工作表都应该引起你的警觉。应该仔细检查这样的查询语句,看看是否有办法重写查询来避免用到工作表。有可能没有办法。但如果有 的话,你就朝提升这个查询的性能方面前进了一步.
(14) 在图形执行计划上看到流聚合(Stream Aggregate)图标就意味着有对一个单一的输入进行了聚合。当使用了DISTINCT子句,或者 任何聚合函数时,如AVG, COUNT, MAX, MIN,或者SUM等,流聚合 操作就相当常见。
(15)查询分析器与Management Studio不是唯一的可以生成、 显示查询执行计划的工具。SQL Server Profiler也可以显示执行计划,但格式是文本形式的。使用SQL Server Profiler来显示执行计划的一个优势是,它能为实际运行的大量查询产生执行计划。如果使用查询分析器和Management Studio,则一次只能运行一个
(16)如果在查询中使用了OPTION FAST提示,那就必须小心 执行计划的结果可能不是你所期望的。这时你所看到的执行计划基于使用了FAST提示的结果, 而不是整个查询语句的实际执行计划。FAST提示用来告知果询优化器尽可能快地返回指定行数的数据 行,即便这样做会防碍查询的整体性能。使用这个提示的目的在于为使用者快速返回特定行数的记录,由此让他们产生速度非常快速的错觉。。当返回指定行数的数 据行后,剩余的数据行按照它们通常的速度返回。 因此,如果使用了FAST提示,那么 生成的执行计划只是基于那些FAST返回的数据行,而非查询要返回的所有数据行。如果想看所有数据行的执行计 划,那么就必须移除这个FAST提示.