作者:xujianguo
原创作品转载请注明出处,《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
——————————————————————————————————————————————————————-————
实验目的:
- 使用gdb跟踪分析一个schedule()函数 ,验证您对Linux系统进程调度与进程切换过程的理解;;
- 理解进程上下文的切换机制,以及与中断上下文切换的关系;
实验环境:
实验楼:www.shiyanlou.com。
实验步骤:
1.配置环境,登录实验楼网站。
按照以前的实验方式配置好环境,具体过程见图示:

测试安装是否成功:

成功。
2.3.配置调试系统,和gdb调试配置。
3设置断点,测试进程调度。


——schedule:测试安排。


switch_to:进入点同上。
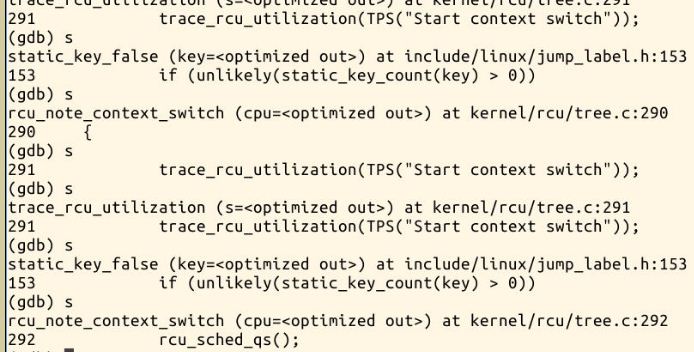
实验分析:
进程调度的时机:
1、进程状态转换的时刻:进程终止、进程睡眠;
进程要调用sleep()或exit()等函数进行状态转换,这些函数会主动调用调度程序进行进程调度;
2、当前进程的时间片用完时(current->counter=0);
由于进程的时间片是由时钟中断来更新的,因此,这种情况和时机4是一样的。
3、设备驱动程序
当设备驱动程序执行长而重复的任务时,直接调用调度程序。在每次反复循环中,驱动程序都检查need_resched的值,如果必要,则调用调度程序schedule()主动放弃CPU。
4、进程从中断、异常及系统调用返回到用户态时;
不管是从中断、异常还是系统调用返回,最终都调用ret_from_sys_call(),由这个函数进行调度标志的检测,如果必要,则调用调用调度程序。那么,为什么从系统调用返回时要调用调度程序呢?这当然是从效率考虑。从系统调用返回意味着要离开内核态而返回到用户态,而状态的转换要花费一定的时间,因此,在返回到用户态前,系统把在内核态该处理的事全部做完。
用老师的话总结如下:
-
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
-
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
-
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
每个时钟中断(timer interrupt)发生时,由三个函数协同工作,共同完成进程的选择和切换,它们是:schedule()、do_timer()及ret_form_sys_call()。我们先来解释一下这三个函数:
schedule():进程调度函数,由它来完成进程的选择(调度);
do_timer():暂且称之为时钟函数,该函数在时钟中断服务程序中被调用,是时钟中断服务程序的主要组成部分,该函数被调用的频率就是时钟中断的频率即每秒钟100次(简称100赫兹或100Hz);
ret_from_sys_call():系统调用返回函数。当一个系统调用或中断完成时,该函数被调用,用于处理一些收尾工作,例如信号处理、核心任务等等。
进程的切换
-
为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
-
挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
-
进程上下文包含了进程执行需要的所有信息
-
用户地址空间: 包括程序代码,数据,用户堆栈等
-
控制信息 :进程描述符,内核堆栈等
-
硬件上下文
(4)恢复或装配所选进程的上下文,将CPU控制权交到所选进程手中。
其中关系最重要的就是schedule函数:
-
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
-
next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
-
context_switch(rq, prev, next);//进程上下文切换
-
switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
Linux系统的一般执行过程
最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
-
正在运行的用户态进程X
-
发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
-
SAVE_ALL //保存现场
-
中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
-
标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
-
restore_all //恢复现场
-
iret - pop cs:eip/ss:esp/eflags from kernel stack
-
继续运行用户态进程Y
特殊情况:
-
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
-
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
-
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
-
加载一个新的可执行程序后返回到用户态的情况,如execve;
代码分析:
*next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
*context_switch(rq, prev, next);//进程上下文切换
*switch_to利用了prev和next参数(prev指向当前进程,next指向被调度的进程)
asm volatile("pushfl
"
"pushl %p
" \将当前进程的堆栈基址压栈
"movl %%esp,%[prev_sp]
" \把当前的栈顶保存起来,保存到thread.sp "movl %[next_sp],%%esp
" \把下个进程的栈顶放到esp寄存器里面
"movl $1f,%[prev_ip]
" \保存当前进程的eip
"pushl %[next_ip]
" \将下一个进程的起点压到堆栈中来 next进程的 栈顶就是它的起点
__switch_canary
"jmp __switch_to
"
"1: " \开始执行next进程的第一条指令
"popl %p
" \pop的原因是因为next进程作为prev进程是曾经push过
"popfl
"
总结:
Linux系统一般执行过程主要是由进程的调度时机和进程的切换机制组成,进程的调度时机主要分上述四种情况,其中主要由schedule函数来完成进程的调度,switch_to完成关键上下文的切换。
进程调度的时机有以下四种:中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度以及在设备驱动程序的调度,具体情况参见实验分析。
系统进程切换机制和中断处理过程不一样,是在同一进程中进行切换,两者是需要区分开的。具体分析见实验分析。
谢谢老师详细的指导!
参考资料: