生成对抗网络GAN(Generative Adversarial Network)


2014年Szegedy在研究神经网络的性质时,发现针对一个已经训练好的分类模型,将训练集中样本做一些细微的改变会导致模型给出一个错误的分类结果,这种虽然发生扰动但是人眼可能识别不出来,并且会导致误分类的样本被称为对抗样本,他们利用这样的样本发明了对抗训练(adversarial training),模型既训练正常的样本也训练这种自己造的对抗样本,从而改进模型的泛化能力。在未加扰动之前,模型认为输入图片有57.7%的概率为熊猫,但是加了之后,人眼看着好像没有发生改变,但是模型却认为有99.3%的可能是长臂猿。
生成对抗网络GAN是一种深度学习模型,它源于2014年发表的论文:《Generative Adversarial Nets》,论文地址:https://arxiv.org/pdf/1406.2661.pdf。
GAN的用途非常广泛,比如:有大量的卡通头像,想通过学习自动生成卡通图片,此问题只提供正例,可视为无监督学习问题。不可能通过人工判断大量数据。如何生成图片?如何评价生成的图片好坏?GAN为此类问题提供了解决方法。
GAN同时训练两个模型:生成模型G(Generative Model)和判别模型D(Discriminative Model),生成模型G的目标是学习数据的分布,判别模型D的目标是区别真实数据和模型G生成的数据。以生成卡通图片为例,生成网络G的目标是生成尽量真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。G和D构成了一个动态的“博弈过程”,通过迭代双方能力都不断提高。
生成对抗网络GAN的用途
- 生成数据 GAN常用于实现复杂分布上的无监督学习和半监督学习,学习数据的分布,模拟现有数据生成同类型的图片、文本、旋律等等。
- 数据增强 GAN也用于扩展现有的数据集,即数据增强。使用GAN训练好的生成网络,可以在数据不足时用于补充数据。
- 生成特定数据 GAN掌握了数据生成能力后,可通过加入限制,使模型生成特定类型的数据。比如改变图片风格,隐去敏感信息,实现诸如数据加密的功能。
- 使用判断模型 训练好的判别模型可以用于判断数据是否属于该类别,判断数据的真实性,以及判断异常数据。
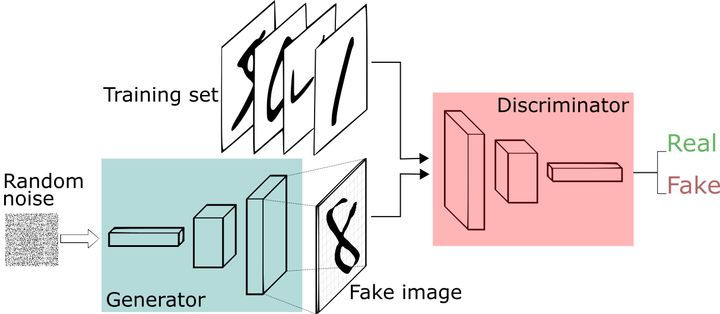
我们现在拥有大量的手写数字的数据集,我们希望通过GAN生成一些能够以假乱真的手写字图片。主要由如下两个部分组成:
- 定义一个模型作为生成器(图中蓝色部分Generator),能够输入一个向量,输出手写数字大小的像素图像。
- 定义一个分类器作为判别器(图中红色部分Discriminator)用来判别图片是真的还是假的(或者说是来自数据集Training set中的,还是生成器中生成的Fake image),输入为手写图片,输出为判别图片的标签。
如何训练GAN
基本流程如下:
- 初始化判别器D的参数
和生成器G的参数
。
- 从真实样本中采样
个样本 {
} ,从先验分布噪声中采样
} 并通过生成器获取
个生成样本 {
} 。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本,尽可能大地区分真实样本和生成的样本。
- 循环k次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽量使得判别器判别错误。
- 多次更新迭代之后,最终理想情况是使得判别器判别不出样本来自于生成器的输出还是真实的输出。亦即最终样本判别概率均为0.5。
Tips: 之所以要训练k次判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够较好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新。更直观的理解可以参考下图:
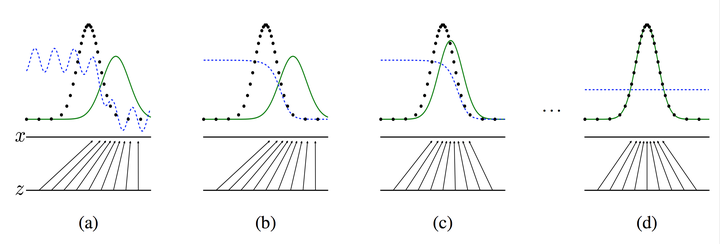 生成器判别器与样本示意图
生成器判别器与样本示意图
注:图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。表示噪声,
表示通过生成器之后的分布的映射情况。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。
可以看到在(a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。
通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。
训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。
经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。
图中展示了两个模型的优化过程,其中黑色代表真实数据,绿色表示生成数据,蓝色表示判别结果;在图(a)中,生成模型没能很好地模拟真实数据分布,差别模型也效果不佳;图(b)优化了判别模型;图(c)随着生成模型的优化,生成数据逐渐接近真实数据;图(d)是最终效果,生成模型完美拟合真实数据,两种数据分布一致,判别模型将无法区分真实数据和生成数据D(x)=1/2。
GAN是一种全新的非监督式的架构(如下图所示)。GAN包括了两套独立的网络,两者之间作为互相对抗的目标。第一套网络是我们需要训练的分类器(下图中的D),用来分辨是否是真实数据还是虚假数据;第二套网络是生成器(下图中的G),生成类似于真实样本的随机样本,并将其作为假样本。
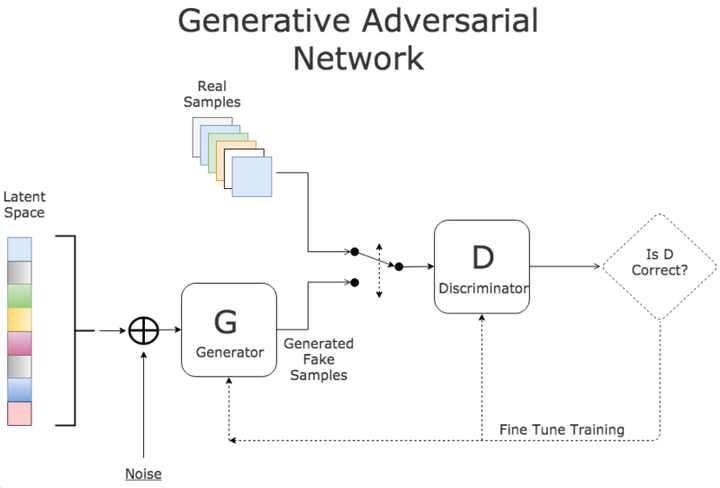
详细说明:
D作为一个图片分类器,对于一系列图片区分不同的动物。生成器G的目标是绘制出非常接近的伪造图片来欺骗D,做法是选取训练数据潜在空间中的元素进行组合,并加入随机噪音,例如在这里可以选取一个猫的图片,然后给猫加上第三只眼睛,以此作为假数据。
在训练过程中,D会接收真数据和G产生的假数据,它的任务是判断图片是属于真数据的还是假数据的。对于最后输出的结果,可以同时对两方的参数进行调优。如果D判断正确,那就需要调整G的参数从而使得生成的假数据更为逼真;如果D判断错误,则需调节D的参数,避免下次类似判断出错。训练会一直持续到两者进入到一个均衡和谐的状态。
训练后的产物是一个质量较高的自动生成器和一个判断能力较强的分类器。前者可以用于机器创作(自动画出“猫”“狗”),而后者则可以用来机器分类(自动判断“猫”“狗”)。
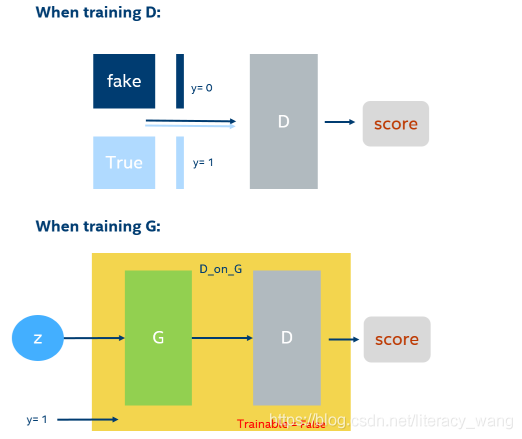
GAN模型的目标函数如下: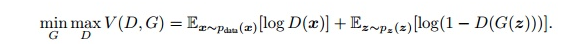
其中Pdata是真实数据的分布,式中左半部分将真实数据x代入判别模型D(x),D的输出范围是从0-1,0为假数据,1为真数据;由于x是真实数据,D模型希望D(x)=1;右半部分将随机噪声z代入生成模型G产生模拟数据G(z),并使用判别模型D判别它是否为真实数据,G模型希望D(G(z))=1,1-D(G(z))=0;相反,D模型希望D(G(z))=0,1-D(G(z))=1。也就是说,G希望上式结果越小越好,而D希望上式结果越大越好。最终函数V既非最大,也非最小,找到双方的利益平衡点——生成数据完全拟合真实数据时达到纳什平衡。
在这里,训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)和log(1—D(G(z)))),训练网络G最小化log(1-D(G(z))),即最大化D的损失。而训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布,也就是生成的样本更加的真实。
或者我们可以直接理解G网络的loss是log(1—D(G(z))),
D的loss是 —(log D(x))+log(1—D(G(z)))
然后从式子中解释对抗,我们知道G网络的训练是希望D(G(z))趋近于1,也就是正类,这样G的loss就会最小。而D网络的训练就是一个2分类,目标是分清楚真实数据和生成数据,也就是希望真实数据的D输出趋近于1,而生成数据的输出即D(G(z))趋近于0,或是负类。这里就是体现了对抗的思想。
探讨
GAN强大之处在于能自动学习原始真实样本集的数据分布,不管这个分布多么的复杂,只要训练的足够好就可以学出来。
传统的机器学习方法,一般会先定义一个模型,再让数据去学习。
比如知道原始数据属于高斯分布,但不知道高斯分布的参数,这时定义高斯分布,然后利用数据去学习高斯分布的参数,得到最终的模型。
再比如定义一个分类器(如SVM),然后强行让数据进行各种高维映射,最后变成一个简单的分布,SVM可以很轻易的进行二分类(虽然SVM放松了这种映射关系,但也给了一个模型,即核映射),其实也是事先知道让数据该如何映射,只是映射的参数可以学习。
以上这些方法都在直接或间接的告诉数据该如何映射,只是不同的映射方法能力不一样。
而GAN的生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型掌握了从随机噪声到人脸数据的分布规律。GAN一开始并不知道这个规律是什么样,也就是说GAN是通过一次次训练后学习到的真实样本集的数据分布。
优点 vs. 缺点
优点:
模型只用到了反向传播,而不需要马尔科夫链
训练时不需要对隐变量做推断
理论上,只要是可微分函数都可以用于构建D和G,因为能够与深度神经网络结合做深度生成式模型
G的参数更新不是直接来自数据样本,而是使用来自D的反向传播(这也是与传统方法相比差别较大的)
从实际结果来看,GAN看起来能产生更好的生成样本
GAN框架可以训练任何一种生成器网络(理论上,然而在实践中,很难使用增强学习去训练有离散输出的生成器),大多数其他架构需要生成器有一些特定的函数形式,就像输出层必须是高斯化的.另外所有其他框架需要生成器整个都是非零权值(put non-zero mass everywhere),然而,GANs可以学习到一个只在靠近真实数据的地方(神经网络层)产生样本点的模型( GANs can learn models that generate points only on a thin manifold that goes near the data.)【指的是GAN学习到的分布十分接近真实分布,这里把分布密度函数看作高维流行当中的点,某个类型的真实分布,可能是这个高维空间中的低维流行,想象三维空间中一张卷曲的纸。GAN学习的G能够尽量的“收敛”到这张纸上,而别的生成模型不行,总是在真实的流行之外有一定的分布,不够收敛。非零的mass指的是分布的“密度”,或者分布的“微元”】
没有必要遵循任何种类的因式分解去设计模型,所有的生成器和判别器都可以正常工作
相比PixelRNN, GAN生成采样的运行时间更短,GANs一次产生一个样本,然而PixelRNNs需要一个像素一个像素的去产生样本
相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
相比深度玻尔兹曼机, GANs没有变分下界,也没有棘手的配分函数,样本是一次生成的,而不是重复的应用马尔科夫链来生成的
相比GSNs, GANs产生的样本是一次生成的,而不是重复的应用马尔科夫链来生成的
相比NICE和Real NVE,GANs没有对潜在变量(生成器的输入值)的大小进行限制
GANs是一种以半监督方式训练分类器的方法.在你没有很多带标签的训练集的时候,你可以不做任何修改的直接使用我们的代码,通常这是因为你没有太多标记样本
GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据
GANs不需要蒙特卡洛估计来训练网络,人们经常抱怨GANs训练不稳定,很难训练,但是他们比训练依赖于蒙特卡洛估计和对数配分函数的玻尔兹曼机简单多了.因为蒙特卡洛方法在高维空间中效果不好,玻尔兹曼机从来没有拓展到像ImgeNet任务中.GANs起码在ImageNet上训练后可以学习去画一些以假乱真的狗
相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊
相比非线性ICA(NICE, Real NVE等,),GANs不要求生成器输入的潜在变量有任何特定的维度或者要求生成器是可逆的
相比玻尔兹曼机和GSNs,GANs生成实例的过程只需要模型运行一次,而不是以马尔科夫链的形式迭代很多次
缺点:
可解释性差,生成模型的分布 Pg(G)没有显式的表达
比较难训练,D与G之间需要很好的同步(例如D更新k次而G更新一次),GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
网络难以收敛,目前所有的理论都认为GAN应该在纳什均衡上有很好的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。
训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但在实践中它还是比训练玻尔兹曼机稳定的多
它很难去学习生成离散的数据,就像文本
相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素, 你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值
代码
在图像处理领域使用生成对抗网络可以让模型学习生成特定类型的图片。推荐生成卡通人物图片的例程:
https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter7-GAN生成动漫头像
(《深度学习框架PyTorch:入门与实践》第七章的配套代码)
README中有对应的资源下载地址,该程序只有两三百行代码,在没有GPU支持的机器上花几个小时也能训练完成。模型效果如下图所示:其中左图为第一次迭代的结果,右图为第25次迭代后的结果。

程序使用两个模型,其中一个用于生成图像,另一个用于判断图像是否为模型生成,两个深度学习网络互为逆过程,判别网络由多个卷积构成,用于层层提取特征,最终判断是否为真实图片,而生成网络由多个反卷积层构成,它通过随机噪声层层扩展生成图片。在博弈过程中两个模型各自优化,最终使模型具备生成特定类型图片的能力。
需要注意的是上例中的图片和曲线拟合都针对连续型数据,可以通过调整网络参数的方法逐渐逼近最佳值,对于生成文本一类的离散数据,则需要进一步修改模型。
GAN的一些经典变种
CGAN
CGAN首次提出为GAN增加限制条件,从而增加GAN的准确率。原始的GAN产生的数据模糊不清,为了解决GAN太过自由这个问题,一个很自然的想法就是给GAN加一些约束,于是便有了这篇Conditional Generative Adversarial Nets,这篇工作的改进非常straightforward,在生成模型和判别模型分别为数据加上标签,也就是加上了限制条件。实验表明很有效。
DCGAN
DCGAN全称为Deep convolutional generative adversarial networks,即将深度学习中的卷积神经网络应用到了对抗神经网络中,这篇文章在工程领域内的意义及其大,解决了很多工程性的问题,再加上其源码的开放,将其推向了一个高峰。
这个模型为工业界具体使用CNN的对抗生成网络提供了非常完善的解决方案,并且生成的图片效果质量精细,为之后GAN的后续再应用领域的发展奠定了很好的基础,当然也可以说提供了一个标杆。
iGAN
iGAN完美地将DCGAN和manifold learning融合在一起,很好的展现了一个DCGAN在实践应用方面的具体案例,将交互这种可能性实现,这对将来类似的应用提供了很好的模板。
LAPGAN
江湖人称拉普拉斯对抗生成网络,主要致力于生成更加清晰,更加锐利的数据。
LAPGAN事实上受启发与CGAN,同样在训练生成模型的时候加入了conditional variable,这也是本案例成功的一大重要原因。
SimGAN
Apple出品的SimGAN本质地利用了GAN可以产生和训练数据质量一样的生成数据这个特性,通过GAN生成大量的和训练数据一样真实的数据,从而解决当前大规模的精确标注数据难以获取,人工标注成本过高等一系列问题。
InfoGAN
InfoGAN是一种能够学习disentangled representation的GAN,比如人脸数据集中有各种不同的属性特点,如脸部表情、是否带眼镜、头发的风格眼珠的颜色等等,这些很明显的相关表示, InfoGAN能够在完全无监督信息(是否带眼镜等等)下能够学习出这些disentangled representation,而相对于传统的GAN,只需修改loss来最大化GAN的input的noise和最终输出之间的互信息。
AC-GAN
AC-GAN即auxiliary classifier GAN。
WGAN-GP
REF
https://blog.csdn.net/literacy_wang/article/details/109500829
https://zhuanlan.zhihu.com/p/33752313
https://zhuanlan.zhihu.com/p/26499443
https://zhuanlan.zhihu.com/p/26499443
https://blog.csdn.net/on2way/article/details/72773771
https://zhuanlan.zhihu.com/p/106717106
https://www.cnblogs.com/wangxiaocvpr/p/6069026.html
https://blog.csdn.net/xg123321123/article/details/78034859
https://blog.csdn.net/xg123321123/article/details/78034859