现在开始养成读源码写笔记的习惯。
转载请注明出处: https://www.cnblogs.com/elyw/p/10282424.html
目录
slick源码阅读笔记 目录&总览
slick源码阅读笔记一 slick.ast
slick源码阅读笔记二 slick.lifted.Rep
slick源码阅读笔记三 ShapedValue 在Table和Query上的应用
slick源码阅读笔记四 隐式转换--column与Query查询功能实现
slick源码阅读笔记五 Query查询条件生成与OptionMapper
1. sql抽象语法树
slick.ast 定义了整个抽象语法树, 抽象语法树可以和sql互相转换。 slick也是通过抽象语法树和scala的macro来生成最终用来执行的sql。几乎所有的orm框架都有类似的实现, spark的LogicalPlan也是类似的结构。
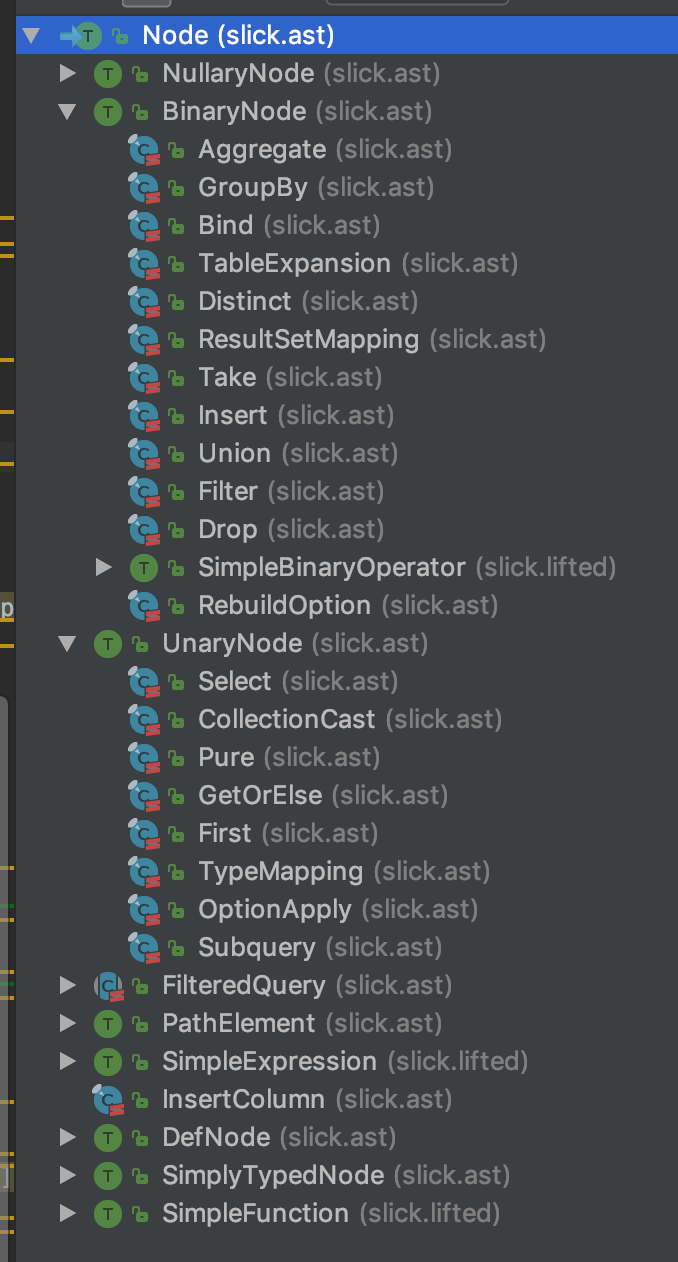
1.1 Node分类
Node主要分为 NullaryNode, BinaryNode, UnaryNode 和 PathElement。
1.1.1 NullNode
NullaryNode是没有子节点的Node,主要用来表示数据源。(类似spark的LeafNode)
比如 :数据库表Table, 字面量 LiteralNode
对应sql: select 1; select * from t1; 中的 ”1“ 和 "t1"表
1.1.2. BinaryNode
BinaryNode是有两个字节点的Node, 主要用来表示 group by, join 等概念。 (类似spark的BinaryNode)
比如: group by 会有key和对应的数据来源, join 有左右两个 Query节点。
对应sql: select a, sum(b) from t1 group by a ; 的 a 和 t1。
对应sql: select * from t1 join t2 on t1.a = t2.a ; 的 t1 和 t2。
1.1.3 UnaryNode
UnaryNode是只有一个子节点的Node, 主要用来表示sql function, select之类的概念。( 类似spark的UnaryNode)
1.1.4 PathElement
PathElemnt是用来溯源的,会掺杂到不同的Node中,一般不会独立存在。 (spark没有类似父类,不过在对逻辑计划进行优化的时候会做类似的判断,并且具体Node的实现会带有类似的功能, 比如MultiInstanceRelation)
例如:sum(a) 需要溯源这个a字段是从哪来的。
例如:select 既是 pathElement 又是
1.2 Node 类型
大部分Node是没有类型,少数有类型的节点是为了和数据库字段类型之间做类型映射而存在的。
因此直接用ast包来进行编程很复杂,而且没有类型检查很容易出错。
所以为了可以使用类似scala.collection的语法以及编译时/运行时的类型检查,slick使用slick.lifted包来实现。