1. Spark Shuffle
回顾一下MapReduce的shuffle,即先按照key聚合,再对key进行排序
而spark中的shuffle不一定按key排序,shuffle前称为MapTask阶段,shuffle之后称为ReduceTask阶段
每一个分区分配一个MapTask
shuffle这里主要讨论Hash Shuffle与Sort Shuffle
其中Hash Shuffle分为两个版本,一个是未经过优化的,还有一个是优化后的
2. 未经优化的HashShuffle
每一个Map Task都会生成Reduce Task数量这么多个文件
这样做的好处是到了reduce阶段,因为map task给下游stage的每个reduce task都创建了一个磁盘文件,每个reduce task只要从上游map task所在节点上,拉取属于自己的那一个磁盘文件即可
缺点是产生大量小文件,效率低下
#num of mappers*num of reducers
3. 优化后的HashShuffle(consolidateFiles)
默认使用未优化的HashShuffle
引入了shuffleFileGroup的概念,对于每一个Executor,一个executor上有多少个CPU core,就可以并行执行多少个Map task,每个core同一时间只能运行一个Map Task
第一批被运行的MapTask也会创建下游Reduce Task那么多个磁盘文件,并组成一个shuffleFileGroup,也就是说每一个core对应一个shuffleFileGroup,从第二批开始,每个Map Task都会复用第一批的shuffleFileGroup,而不产生新的文件
简单一点理解:因为同一时间一个core只能运行一个map task,所以存在等待
补充:data在hash阶段被分区, hash shuffle不给key排序
#numExecutor*numCores*numReduceTask (老师的版本cores/T是考虑可能同一个core同一时间运行多个task)
4. sort shuffle分为normal与by pass两个版本
sort shuffle normal跟MR shuffle基本一致,最终一个map对应一个文件,且为了reduce阶段更加方便生成index文件(最终一个mapper产生两个文件)
bypass也是产生两个文件,但是该机制下不会进行排序
若partition很小(shuffle read task很小)就启动bypass机制,相当于hash shuffle
5. LSH
需要用到distance判断两个事物的相似度,首先将事物的各个属性转化为一串可以计算的数字,然后套用距离公式进行计算,最常见的是之前9417讲过的L p norm distance
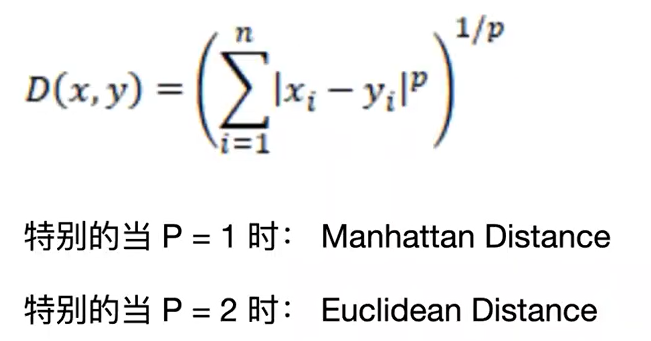
distance的计算方式有angular distance(角度),cosine distance【cos=(a b的内积)/(|a||b|), ab的内积等于a1b1+a2b2, 需要注意cos越大相似度越大】
6. Hash code
将每一个数据看成一个object,这个object会有很多属性,对每一个object基于她们的属性值对应唯一一个数,该值称为hash code(用各种不同的方法生成hash code)
注意属性相同hash code一定相同;但是属性不同,hash code可能相同;属性区别不大但是hash code可能差距很大
而similarity属相相同则相似度最高,属性稍微不同相似度也很高
7. 随着维度的增加,传统计算similarity的方法不是很有效,所以引用LSH(Locality Sensitive Hashing)
LSH依然是将Data转化为Hash Code,但与统一转化不一样的是,LSH的转化结合了similarity。希望达到的是相似的数据很大概率得到一样的hash key,不相似的数据很大概率得到不同的hash key
若想找到与A相似的,则首先计算A的hash code,利用该Hash Code查表,看哪些数据拥有相似的hash code,遍历找到distance最小的
8. 如何设计Hash Function
每次对object hash的结果是一个整数,在LSH中一般会生成m个h
对object hash m次,最终生成一个m味的superHash
9. 如何保证真正相似的数据hash code一定相同
将条件放宽,引入C2LSH
从hash code必须完全一样变为相差一位也可以,若是还是不全则继续放宽条件到两位
对两个m位的hash code,从第一位开始上下对比,一样的称为一个collision,数一共有多少collision,然后跟开始规定的阈值对比。若没有取得足够的candidate则放宽条件,若是上下两个数相差1也可以
10. C2LSH步骤
1)generate LSH function(random vectors and random uniform values)作业中已经有了
2)计算并存储hash function的值,作业中已经给出了n*m的列表(data数量*hash code位数)
3)计算A的hash code,老师已经给出了
选择跟A相似度达到多少的,放入列表,若是得到的数据不够多,放宽条件,直到得到足够的数据,candedate数量是规定好的
需要写测试case以及report,建议对RDD部分用lucidchart画图表
bonus取决于运行时间,最好少用shuffle,建议对数据进行分区
data_hashes输入的是一个RDD,需要对其做转化