1.machine learning研究如何使机器从一开始的遵循简单规则到可以根据以往经验做出自主判断/行为预测(对data的pattern进行研究)
2. 举例:recommender systems: 第一种方法是找到过往搜索中出现过的pattern,推荐类似的应用;第二种方法是找到搜索过相同pattern的用户,查询这些用户搜索过的其他应用
3. data wrangling/processing:处理数据前所要进行的前期处理(gather,assess,clean)
feature extraction特征提取

4. machine learning可以分成supervised learning以及unsupervised learning
supervised learning:展示给machine正确的例子,即给出output以帮助machine判断正确性。用到的算法有classification以及regression
unsupervised learning:不给出正确的例子,只根据input进行判断(如将所给书籍分成两类,不指定分类规则)。用到的算法有clustering
5. regression: classification用于找到一个model以便预测离散数据中的某一个值
而对于连续数据,则需要用到regression
6. For the class of symbolic representations符号表示, machine learning is viewed as: searching a space of hypotheses. . .
represented in a formal hypothesis language (trees, rules, graphs . . . )
For the class of numeric representations, machine learning is viewed as: searching a space of functions . . .
represented as mathematical models (linear equations, neural nets, . . . )
7. linear regression:output与我们在input中所找到的特点存在线性关系


8. univariate regression: 一个input/feature用以预测一个output
multiple regression:多个input/feature用以预测一个output
9. error:预测的value与实际的value之间的区别
将全部error定义为sum of squared errors并找到n+1个参数使其最小化

在OLS框架中也被称作Residual Sum of Squares(RSS)
同时也可以写成:
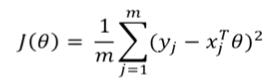 可被称为squared error或MSE
可被称为squared error或MSE
10. 有两个以上变量时,我们找到最好的hyper-plane,即超平面(3维空间,其超平面是2维平面;2维空间,其超平面是一维直线)
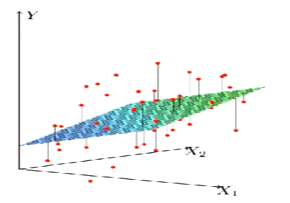
11. 如何找到使RSS最小的参数,已知有单一参数使其最小(RSS的图像像一个碗,总有最低点,如下图所示),故可以通过算法gradient descent
即从一个随机θ开始,根据所给算法随机进行调整


12.
