题源:https://blog.csdn.net/weixin_42110638/article/details/85233701 、 https://www.cnblogs.com/YY666/p/11826948.html
2017
判断题#
1-1 图的关键路径上任意活动的延期都会引起工期的延长 T#
1-2 所有的排序算法中,关键字的比较操作都是不可避免的 F@
基数排序是采用分配和收集实现的,不需要进行关键字的比较,而其他几种排序方法都是通过关键字的比较实现的。
1-3 某二叉树的前序和中序遍历序列正好一样,则该二叉树中的任何结点一定都无左孩子 T#
1-4 折半查找的判定树一定是平衡二叉树 T@#
1-5 查找某元素时,折半查找法的查找速度一定比顺序查找法快 F#
1-6 用邻接矩阵法存储图,占用的存储空间数只与图中结点个数有关,而与边数无关 T#
1-7 基于比较的排序算法中,只要算法的最坏时间复杂度或者平均时间复杂度达到了次平方级O(N * logN),则该排序算法一定是不稳定的 F
例外:归并排序
1-8 B-树中一个关键字只能在树中某一个节点上出现,且节点内部关键字是有序排列的 T
B-树定义:平衡的多路查找树
1-9 采用顺序存储结构的循环队列,出队操作会引起其余元素的移动 F@#
1-10 二叉树中至少存在一个度为2的结点 F
选择题
2-1 下面代码段的时间复杂度是 D D
i = 1; while( i<=n ) i=i*3;
A.O(n)
B. O(n2)
C. O(1)
D. O(log3n)
O(log
2-2 设一段文本中包含4个对象{a,b,c,d},其出现次数相应为{4,2,5,1},则该段文本的哈夫曼编码比采用等长方式的编码节省了多少位数?C#
A.5
B.0
C.2
D.4
24-22=2
2-3 在双向循环链表结点p之后插入s的语句是:D
A.s->prior=p;s->next=p->next; p->next=s; p->next->prior=s;
B.p->next=s;s->prior=p; p->next->prior=s ; s->next=p->next;
C.p->next->prior=s;p->next=s; s->prior=p; s->next=p->next;
D.s->prior=p;s->next=p->next; p->next->prior=s; p->next=s;
2-4 下图为一个AOV网,其可能的拓扑有序序列为 B
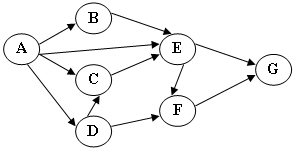
A.ABCDFE
B.ABCEDF
C.ACBDEF
D.ABCEFD
2-5对于模式串'abaaab',利用KMP算法进行模式匹配时,其对应的Next取值(注意是未改进的Next值)为:B
A.0 1 1 2 3 1
B.0 1 1 2 2 2
C.0 1 2 3 4 5
D.0 1 2 2 2 1
2-6 给定散列表大小为11,散列函数为H(Key)=Key%11。采用平方探测法处理冲突:hi(k)=(H(k)±i2)%11将关键字序列{ 6,25,39,61 }依次插入到散列表中。那么元素61存放在散列表中的位置是: A
A.5
B.6
C.7
D.8

6%11=6,占据下标6
25%11=3,占据下标3
39%11=6,(6+1)%11=7,占据下标7
61%11=6,(6-1)%11=5,占据下标5
2-7 设栈S和队列Q的初始状态均为空,元素a、b、c、d、e、f、g依次进入栈S。若每个元素出栈后立即进入队列Q,且7个元素出队的顺序是b、d、c、f、e、a、g,则栈S的容量至少是:A
A.3
B.4
C.1
D.2
2-8 有组记录的排序码为{46,79,56,38,40,84 },采用快速排序(以位于最左位置的对象为基准而)得到的第一次划分结果为:D
A.{38,79,56,46,40,84}
B.{38,46,56,79,40,84}
C.{38,46,79,56,40,84}
D.{40,38,46,56,79,84}
2-9 设森林F中有三棵树,第一、第二、第三棵树的结点个数分别为M1,M2和M3。则与森林F对应的二叉树根结点的右子树上的结点个数是:B#B
A. M1+M2
B. M2+M3
C. M1
D. M3
2-10 在决定选取何种存储结构时,一般不考虑()D
A.结点个数的多少
B.对数据有哪些运算
C.所用编程语言实现这种结构是否方便
D.各结点的值如何
2-11 将{ 3, 8, 9, 1, 2, 6 }依次插入初始为空的二叉排序树。则该树的后序遍历结果是:B
A. 1, 2, 8,6, 9, 3
B. 2,1, 6, 9, 8, 3
C. 1, 2, 3,6, 9, 8
D. 2, 1, 3,6, 9, 8
2-12 具有65个结点的完全二叉树其深度为(根的深度为1):C#
A. 6
B. 5
C. 8
D. 7
2-13 在图中自d点开始进行深度优先遍历算法可能得到的结果为:A
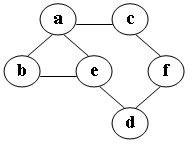
A. d,e,a,c,f,b
B. d,f,c,e,a,b
C. d,a,c,f,e,b
D. d,a,e,b,c,f
2-14 我们用一个有向图来表示航空公司所有航班的航线。下列哪种算法最适合解决找给定两城市间最经济的飞行路线问题?B
A. Kruskal算法
B. Dijkstra算法
C. 深度优先搜索
D. 拓扑排序算法
2-15 若对N阶对称矩阵A以行优先存储的方式将其下三角形的元素(包括主对角线元素)依次存放于一维数组B[1..(N(N+1))/2]中,则A中第i行第j列(i和j从1开始,且i>j)的元素在B中的位序k(k从1开始)为 (3分):D#
A. j*(j-1)/2+i
B. i*(i+1)/2+j
C. j*(j+1)/2+i
D. i*(i-1)/2+j
程序题
1 删除单链表中最后一个与给定值相等的结点#
本题要求在链表中删除最后一个数据域取值为x的节点。L是一个带头结点的单链表,函数ListLocateAndDel_L(LinkList L, ElemType x)要求在链表中查找最后一个数据域取值为x的节点并将其删除。例如,原单链表各个节点的数据域依次为1 3 1 4 3 5,则ListLocateAndDel_L(L,3)执行后,链表中剩余各个节点的数据域取值依次为1 3 1 4 5。
函数接口定义:
void ListLocateAndDel_L(LinkList L, ElemType x);
其中 L 是一个带头节点的单链表。 x 是一个给定的值。函数须在链表中定位最后一个数据域取值为x的节点并删除之。
裁判测试程序样例:
输入样例:
输出样例:
1 3 1 4 5
答案:
void ListLocateAndDel_L(LinkList L, ElemType x) { if(!L) return;//表空啥也不干 else { LinkList p = L->next,q,t=L;//t指向头结点 while(p) { if(p->data==x) t = q;//记录并更新相同位置(t也是要删除位置的直接前驱) q = p;//这两部就是不等就一直往后更新 p = p->next; } if(t!=L)//大概的意思就是t往后移动了,就可以删了(不知道不写这句行不行) { t->next = t->next->next;//删除操作 } } }
另一个方法:
void ListLocateAndDel_L(LinkList L, ElemType x); { if(L->next==NULL) return ; else { LNode *p=L->next; LNode *q; int count=0; int recount=0; while(p) { if(p->data==x) count++; p=p->next; } while(L) { if(p->data==x) { recount++; if(recount==count) { q=L->next; L->next=L->next->next; free(q); } } L=L->next; } } }
2 计算二叉树的深度#
编写函数计算二叉树的深度。二叉树采用二叉链表存储结构
函数接口定义:
int GetDepthOfBiTree ( BiTree T);
其中 T是用户传入的参数,表示二叉树根节点的地址。函数须返回二叉树的深度(也称为高度)。
裁判测试程序样例:
//头文件包含 #include <stdlib.h> #include <stdio.h> #include <malloc.h> //函数状态码定义 #define TRUE 1 #define FALSE 0 #define OK 1 #define ERROR 0 #define OVERFLOW -1 #define INFEASIBLE -2 #define NULL 0 typedef int Status; //二叉链表存储结构定义 typedef int TElemType; typedef struct BiTNode { TElemType data; struct BiTNode *lchild, *rchild; } BiTNode, *BiTree; //先序创建二叉树各结点,输入0代表空子树 Status CreateBiTree(BiTree &T) { TElemType e; scanf("%d", &e); if (e == 0) T = NULL; else { T = (BiTree)malloc(sizeof(BiTNode)); if (!T) exit(OVERFLOW); T->data = e; CreateBiTree(T->lchild); CreateBiTree(T->rchild); } return OK; } //下面是需要实现的函数的声明 int GetDepthOfBiTree(BiTree T); //下面是主函数 int main() { BiTree T; int depth; CreateBiTree(T); depth = GetDepthOfBiTree(T); printf("%d ", depth); } /*请在这里填写答案*/
输入样例(输入0代表创建空子树):
1 3 0 0 5 7 0 0 0
输出样例:
3
答案:
int GetDepthOfBiTree ( BiTree T) { int l,r; if(!T) return 0; else { l=GetDepthOfBiTree(T->lchild); r=GetDepthOfBiTree(T->rchild); return l>r?++l:++r; } }
2018
选择题



判断题


