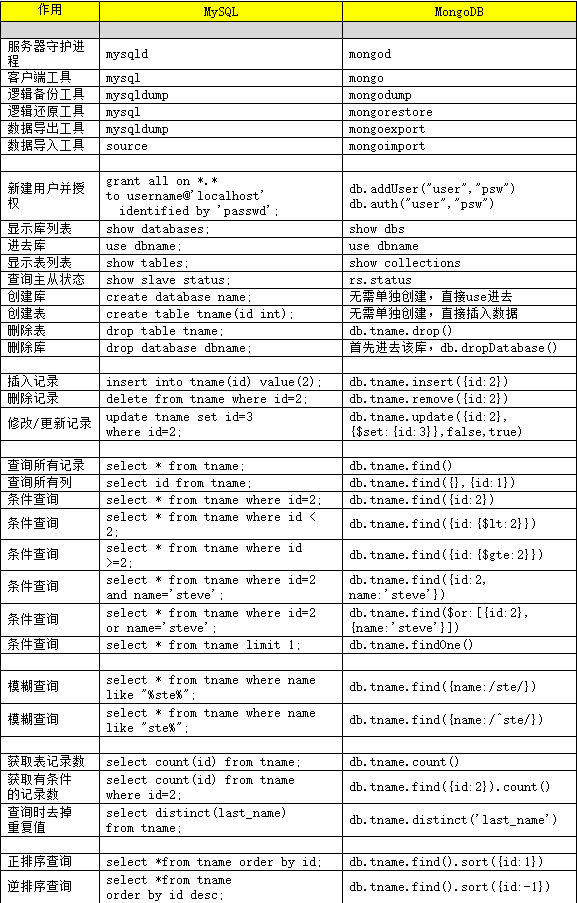
MongoDB 是一个基于分布式文件存储的数据库
MongoDB MySQL
数据库模型 非关系型 关系型
存储方式 以类JSON的文档的格式存储 不同引擎有不同的存储方式
查询语句 MongoDB查询方式(类似JavaScript的函数) SQL语句
数据处理方式 基于内存,将热数据存放在物理内存中,从而达到高速读写 不同引擎有自己的特点
成熟度 新兴数据库,成熟度较低 成熟度高
广泛度 NoSQL数据库中,比较完善且开源,使用人数在不断增长 开源数据库,市场份额不断增长
事务性 仅支持单文档事务操作,弱一致性 支持事务操作
占用空间 占用空间大 占用空间小
join操作 MongoDB没有join MySQL支持join
MongoDB的基本命令
MongoDB 创建数据库
use DATABASE_NAME
MongoDB 删除数据库(db.dropDatabase())_database(数据库)
> show dbs
local 0.078GB
runoob 0.078GB
test 0.078GB
> use runoob
switched to db runoob
> db.dropDatabase()
{ "dropped" : "runoob", "ok" : 1 }
> show dbs
local 0.078GB
test 0.078GB
MongoDB 创建集合(db.createCollection(name, options))__tables(表名)
> use test
switched to db test
> db.createCollection("runoob")
{ "ok" : 1 }
> show collections
runoob
创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection("mycol", { capped : true, autoIndexId : true, size:6142800, max : 10000 } )
MongoDB增,删,改,查
MongoDB 删除集合(db.collection.drop()) >use mydb switched to db mydb >show collections mycol mycol2 system.indexes runoob >db.mycol2.drop() true >show collections mycol system.indexes runoob MongoDB 插入文档(db.COLLECTION_NAME.insert(document)) >db.col.insert({title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '菜鸟教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }) > db.col.find() { "_id" : ObjectId("56064886ade2f21f36b03134"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } MongoDB 更新文档 db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> } ) query : update的查询条件,类似sql update查询内where后面的。 update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的 upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。 multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。 writeConcern :可选,抛出异常的级别。 >db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息 > db.col.find().pretty() { "_id" : ObjectId("56064f89ade2f21f36b03136"), "title" : "MongoDB", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } 要修改多条相同的文档,则需要设置 multi 参数为 true。 >db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true}) 只更新第一条记录: db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } ); 全部更新: db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true ); 只添加第一条: db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false ); 全部添加加进去: db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true ); 全部更新: db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true ); 只更新第一条记录: db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false ); MongoDB 删除文档 db.collection.remove( <query>, { justOne: <boolean>, writeConcern: <document> } ) query :(可选)删除的文档的条件。 justOne : (可选)如果设为 true 或 1,则只删除一个文档。 writeConcern :(可选)抛出异常的级别。 > db.col.find() { "_id" : ObjectId("56066169ade2f21f36b03137"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } { "_id" : ObjectId("5606616dade2f21f36b03138"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } 接下来我们移除 title 为 'MongoDB 教程' 的文档: >db.col.remove({'title':'MongoDB 教程'}) WriteResult({ "nRemoved" : 2 }) # 删除了两条数据 >db.col.find() …… # 没有数据 如果你只想删除第一条找到的记录可以设置 justOne 为 1: >db.COLLECTION_NAME.remove(DELETION_CRITERIA,1) 如果你想删除所有数据,可以使用以下方式(类似常规 SQL 的 truncate 命令): >db.col.remove({}) >db.col.find() 如删除集合下全部文档: db.inventory.deleteMany({}) 删除 status 等于 A 的全部文档: db.inventory.deleteMany({ status : "A" }) 删除 status 等于 D 的一个文档: db.inventory.deleteOne( { status: "D" } )
MongoDB 查询文档 db.collection.find(query, projection) query :可选,使用查询操作符指定查询条件 projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。 以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下: >db.col.find().pretty() 格式 范例 RDBMS中的类似语句 等于 {<key>:<value>} db.col.find({"by":"菜鸟教程"}).pretty() where by = '菜鸟教程' 小于 {<key>:{$lt:<value>}} db.col.find({"likes":{$lt:50}}).pretty() where likes < 50 小于或等于 {<key>:{$lte:<value>}} db.col.find({"likes":{$lte:50}}).pretty() where likes <= 50 大于 {<key>:{$gt:<value>}} db.col.find({"likes":{$gt:50}}).pretty() where likes > 50 大于或等于 {<key>:{$gte:<value>}} db.col.find({"likes":{$gte:50}}).pretty() where likes >= 50 不等于 {<key>:{$ne:<value>}} db.col.find({"likes":{$ne:50}}).pretty() where likes != 50 >db.col.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty() MongoDB Limit与Skip方法 limit()方法来读取指定数量的数据,kip()方法来跳过指定数量的数据 >db.COLLECTION_NAME.find().limit(NUMBER) >db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) MongoDB 排序 >db.COLLECTION_NAME.find().sort({KEY:1}) 1 为升序排列,-1 是用于降序排列 { "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "php" ], "likes" : 200 } { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 } { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb" ], "likes" : 100 } 以下实例演示了 col 集合中的数据按字段 likes 的降序排列: >db.col.find({},{"title":1,_id:0}).sort({"likes":-1}) { "title" : "PHP 教程" } { "title" : "Java 教程" } { "title" : "MongoDB 教程" } MongoDB 正则表达式 >db.posts.find({post_text:{$regex:"runoob"}}) >db.posts.find({post_text:/runoob/}) >db.posts.find({post_text:{$regex:"runoob",$options:"$i"}}) #$options 为 $i。 数组元素使用正则表达式 >db.posts.find({tags:{$regex:"run"}})
Help()
> db.boss.help() DBCollection help db.boss.find().help() - show DBCursor help db.boss.bulkWrite( operations, <optional params> ) - bulk execute write operations, optional parameters are: w, wtimeout, j db.boss.count( query = {}, <optional params> ) - count the number of documents that matches the query, optional parameters are: limit, skip, hint, maxTimeMS db.boss.copyTo(newColl) - duplicates collection by copying all documents to newColl; no indexes are copied. db.boss.convertToCapped(maxBytes) - calls {convertToCapped:'boss', size:maxBytes}} command db.boss.createIndex(keypattern[,options]) db.boss.createIndexes([keypatterns], <options>) db.boss.dataSize() db.boss.deleteOne( filter, <optional params> ) - delete first matching document, optional parameters are: w, wtimeout, j db.boss.deleteMany( filter, <optional params> ) - delete all matching documents, optional parameters are: w, wtimeout, j db.boss.distinct( key, query, <optional params> ) - e.g. db.boss.distinct( 'x' ), optional parameters are: maxTimeMS db.boss.drop() drop the collection db.boss.dropIndex(index) - e.g. db.boss.dropIndex( "indexName" ) or db.boss.dropIndex( { "indexKey" : 1 } ) db.boss.dropIndexes() db.boss.ensureIndex(keypattern[,options]) - DEPRECATED, use createIndex() instead db.boss.explain().help() - show explain help db.boss.reIndex() db.boss.find([query],[fields]) - query is an optional query filter. fields is optional set of fields to return. e.g. db.boss.find( {x:77} , {name:1, x:1} ) db.boss.find(...).count() db.boss.find(...).limit(n) db.boss.find(...).skip(n) db.boss.find(...).sort(...) db.boss.findOne([query], [fields], [options], [readConcern]) db.boss.findOneAndDelete( filter, <optional params> ) - delete first matching document, optional parameters are: projection, sort, maxTimeMS db.boss.findOneAndReplace( filter, replacement, <optional params> ) - replace first matching document, optional parameters are: projection, sort, maxTimeMS, upsert, returnNewDocument db.boss.findOneAndUpdate( filter, update, <optional params> ) - update first matching document, optional parameters are: projection, sort, maxTimeMS, upsert, returnNewDocument db.boss.getDB() get DB object associated with collection db.boss.getPlanCache() get query plan cache associated with collection db.boss.getIndexes() db.boss.group( { key : ..., initial: ..., reduce : ...[, cond: ...] } ) db.boss.insert(obj) db.boss.insertOne( obj, <optional params> ) - insert a document, optional parameters are: w, wtimeout, j db.boss.insertMany( [objects], <optional params> ) - insert multiple documents, optional parameters are: w, wtimeout, j db.boss.mapReduce( mapFunction , reduceFunction , <optional params> ) db.boss.aggregate( [pipeline], <optional params> ) - performs an aggregation on a collection; returns a cursor db.boss.remove(query) db.boss.replaceOne( filter, replacement, <optional params> ) - replace the first matching document, optional parameters are: upsert, w, wtimeout, j db.boss.renameCollection( newName , <dropTarget> ) renames the collection. db.boss.runCommand( name , <options> ) runs a db command with the given name where the first param is the collection name db.boss.save(obj) db.boss.stats({scale: N, indexDetails: true/false, indexDetailsKey: <index key>, indexDetailsName: <index name>}) db.boss.storageSize() - includes free space allocated to this collection db.boss.totalIndexSize() - size in bytes of all the indexes db.boss.totalSize() - storage allocated for all data and indexes db.boss.update( query, object[, upsert_bool, multi_bool] ) - instead of two flags, you can pass an object with fields: upsert, multi db.boss.updateOne( filter, update, <optional params> ) - update the first matching document, optional parameters are: upsert, w, wtimeout, j db.boss.updateMany( filter, update, <optional params> ) - update all matching documents, optional parameters are: upsert, w, wtimeout, j db.boss.validate( <full> ) - SLOW db.boss.getShardVersion() - only for use with sharding db.boss.getShardDistribution() - prints statistics about data distribution in the cluster db.boss.getSplitKeysForChunks( <maxChunkSize> ) - calculates split points over all chunks and returns splitter function db.boss.getWriteConcern() - returns the write concern used for any operations on this collection, inherited from server/db if set db.boss.setWriteConcern( <write concern doc> ) - sets the write concern for writes to the collection db.boss.unsetWriteConcern( <write concern doc> ) - unsets the write concern for writes to the collection db.boss.latencyStats() - display operation latency histograms for this collection