These are older papers, but they provide us with some historic information on how threading system evolved over time.
Sun/Solaris Papers
- "Beyond Multiprocessing: Multithreading the Sun OS Kernel" by Eykholt et. al.
- "Implementing Lightweight Threads" by Stein and Shah

First, let's start by revisiting the illustration we used in the threads and concurrency lecture.
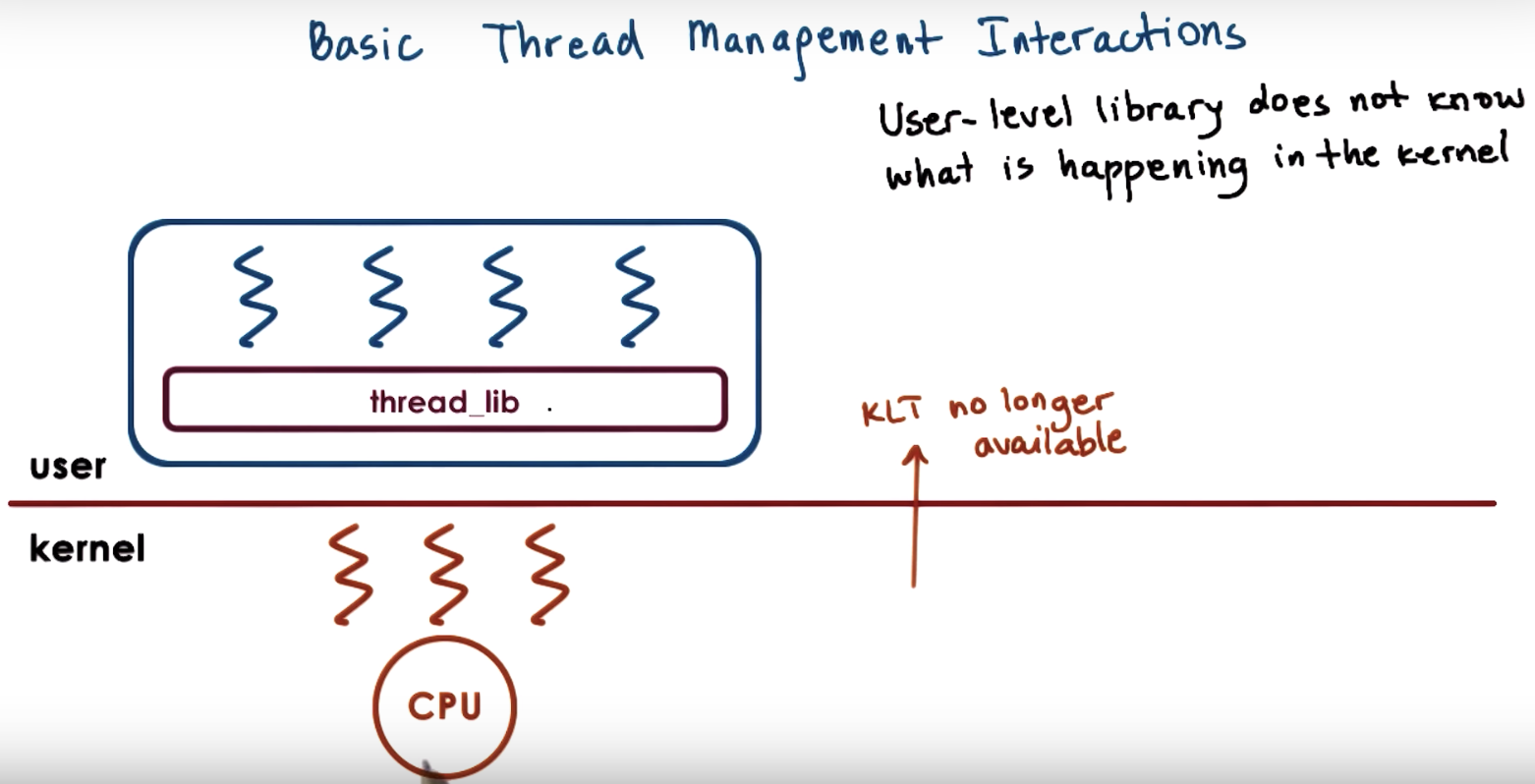
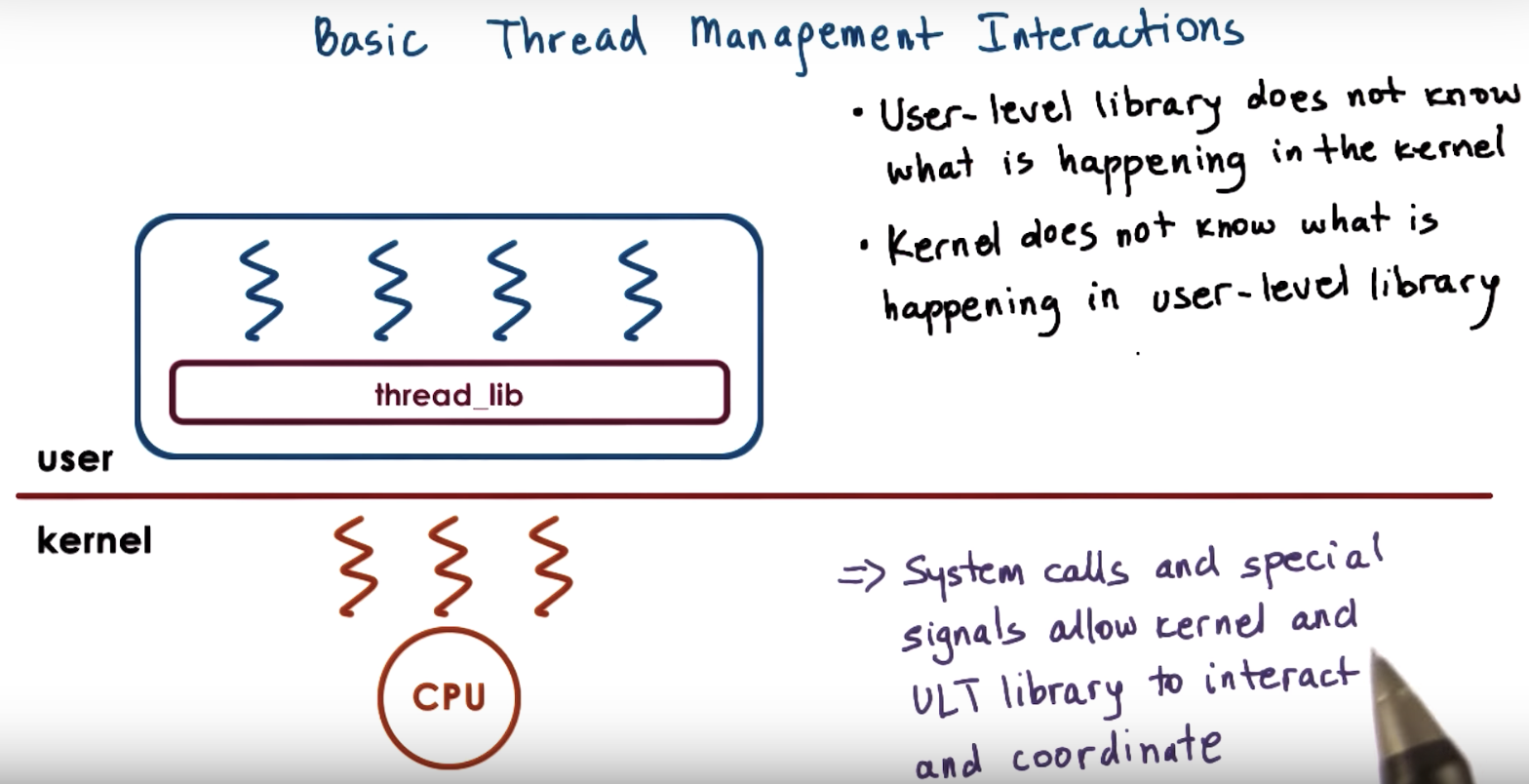
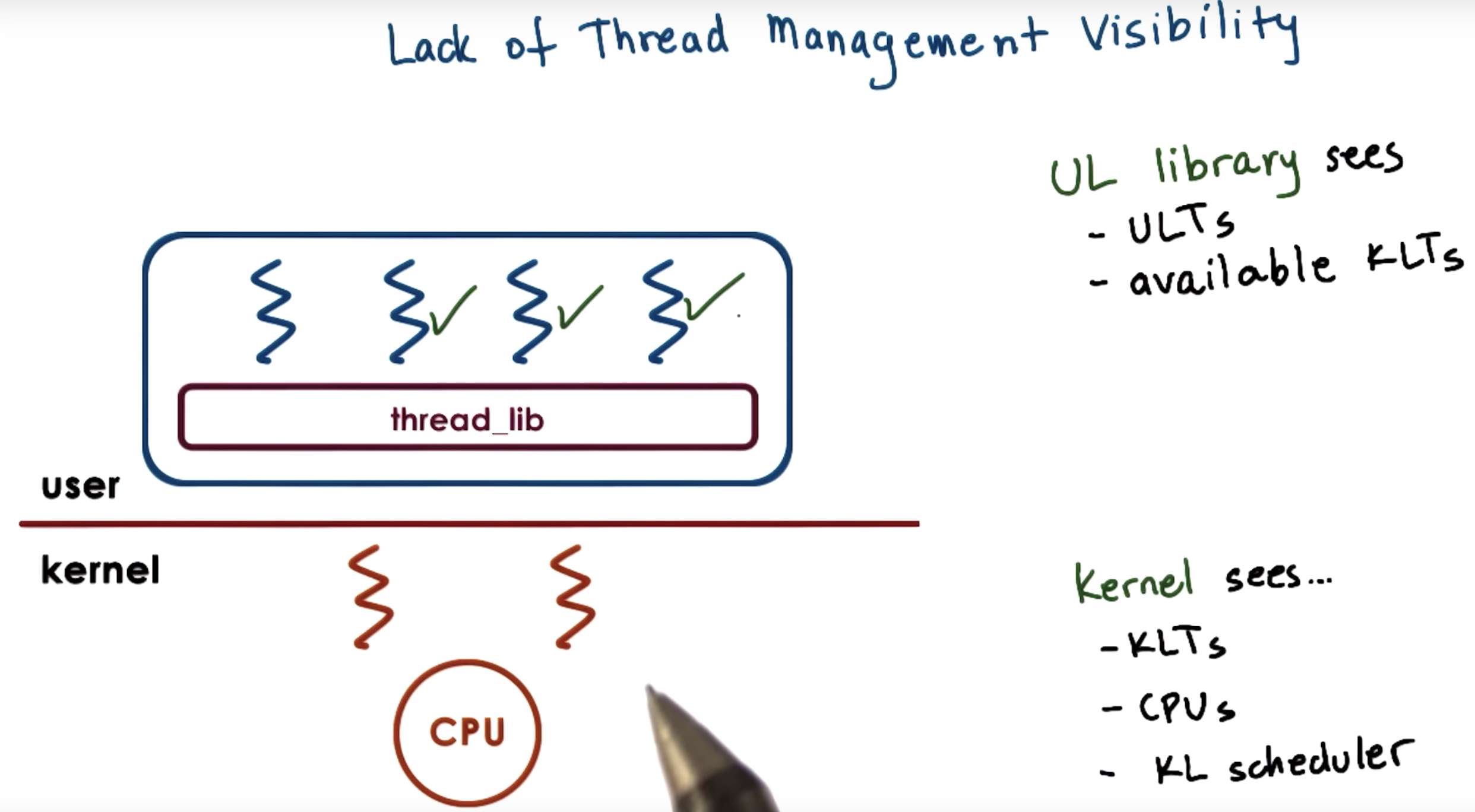
There, we explained that threads can be supported at user level, and at kernel level, or both.
Supporting threads at kernel level means that the OS kernel itself is multithreaded.
Supporting threads at user level means that there's a user-level library, that is linked with the application.
(In fact, different processes may use entirely different user-level libraries that have different ways to represent threads that support the different scheduling mechanisms, et cetera.)
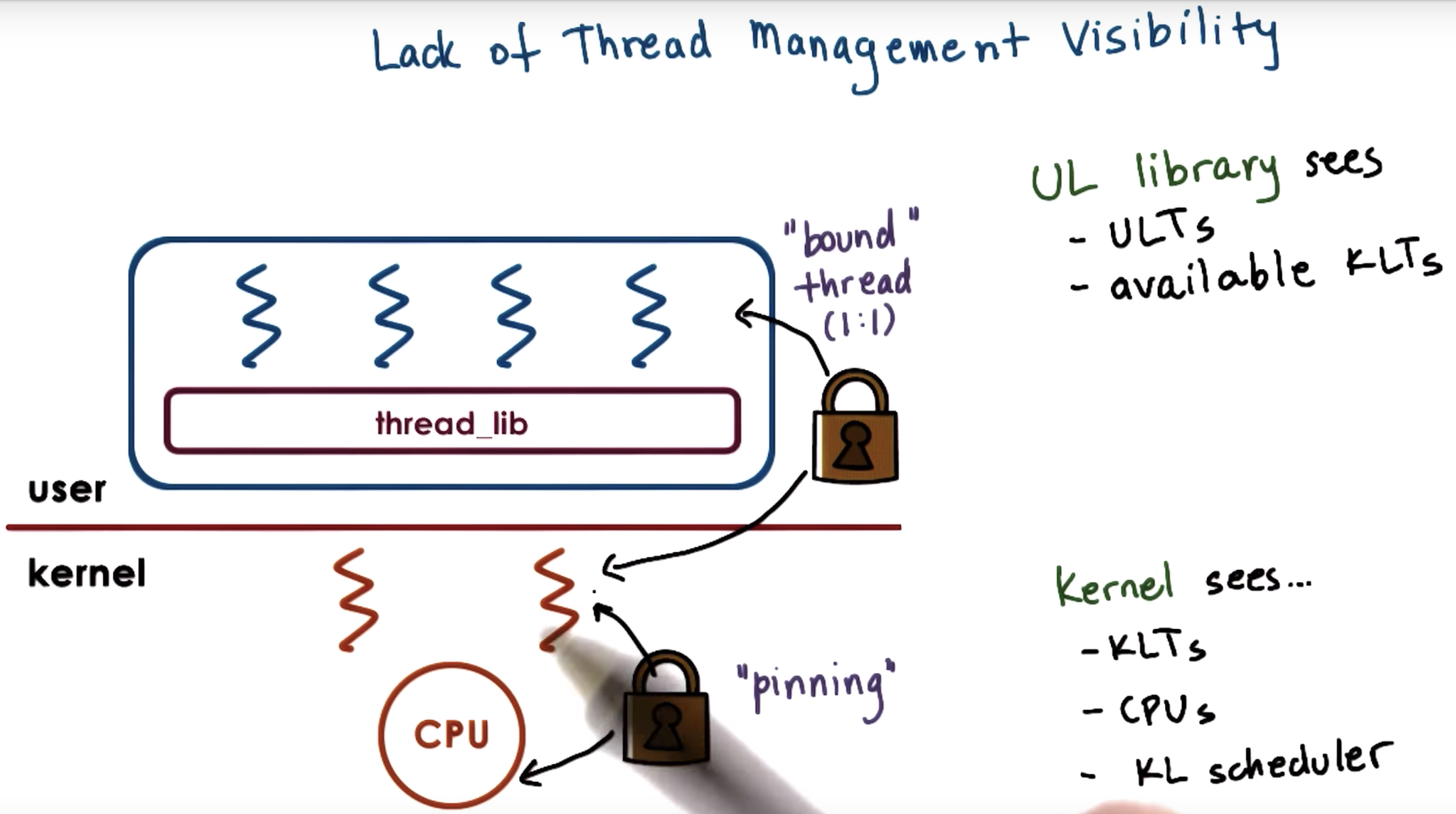
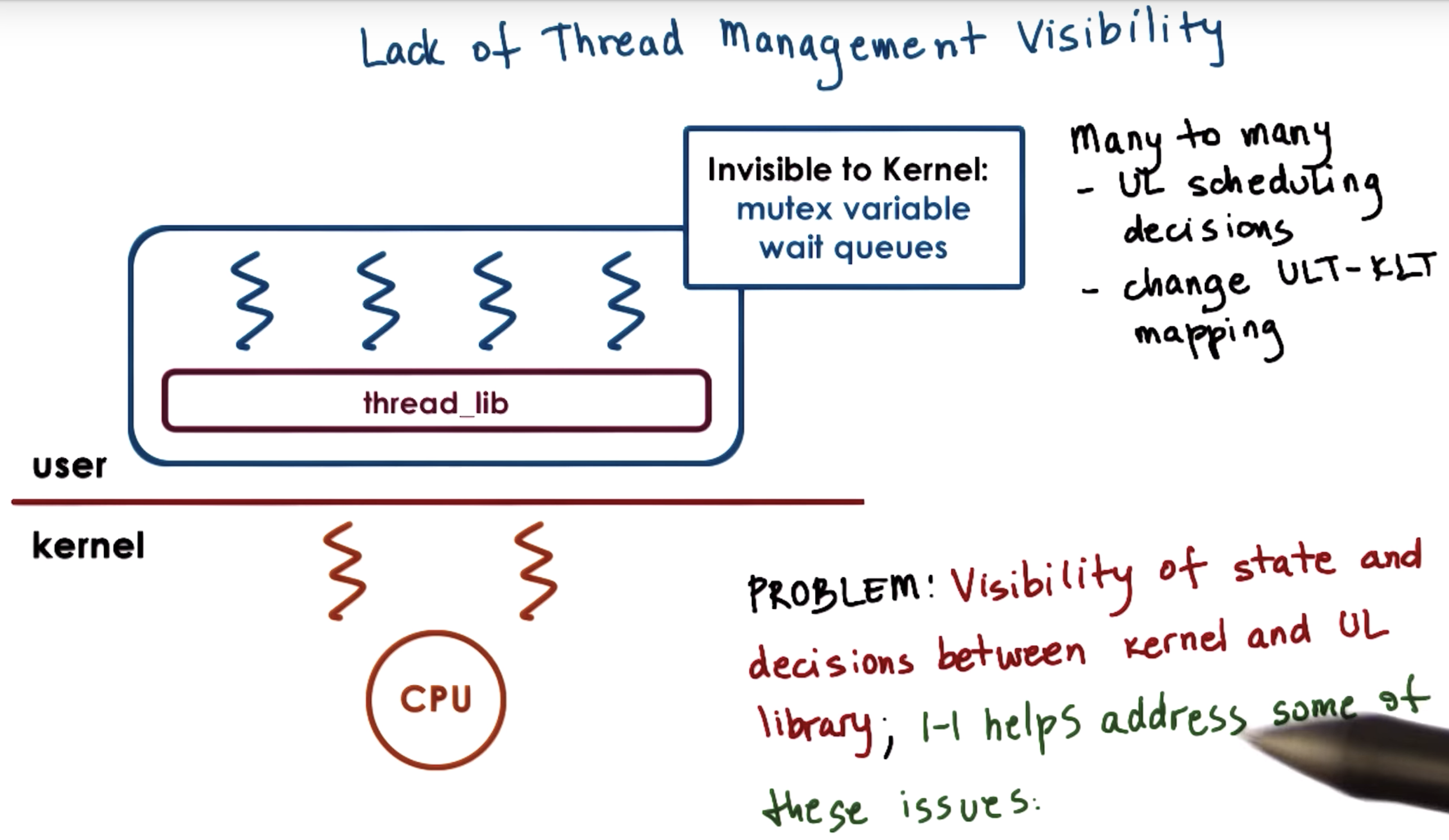
We also discussed several mechanisms, how user level threads can be mapped onto the underlying kernel level threads (1to1, Many to 1, many2many )
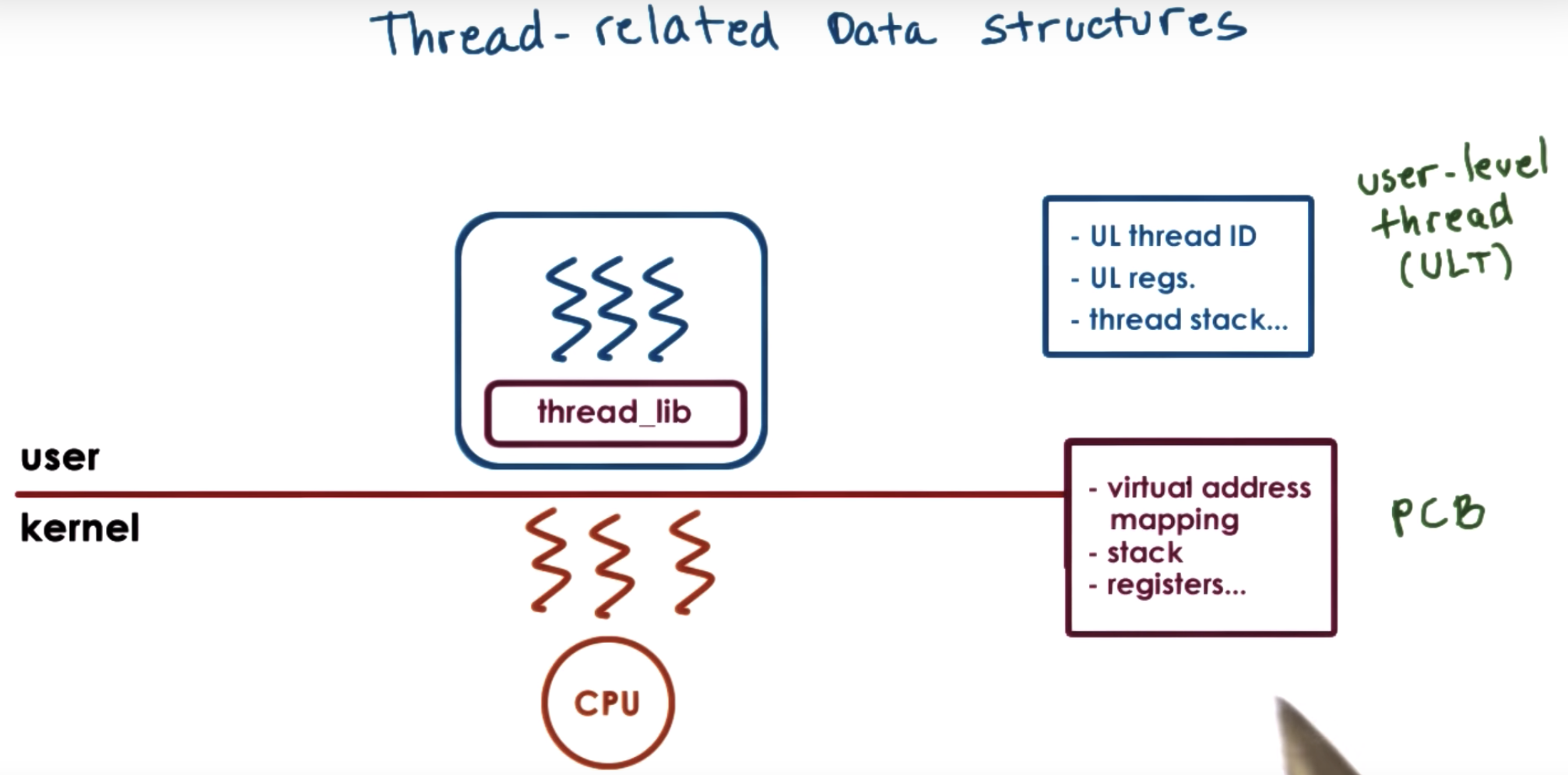
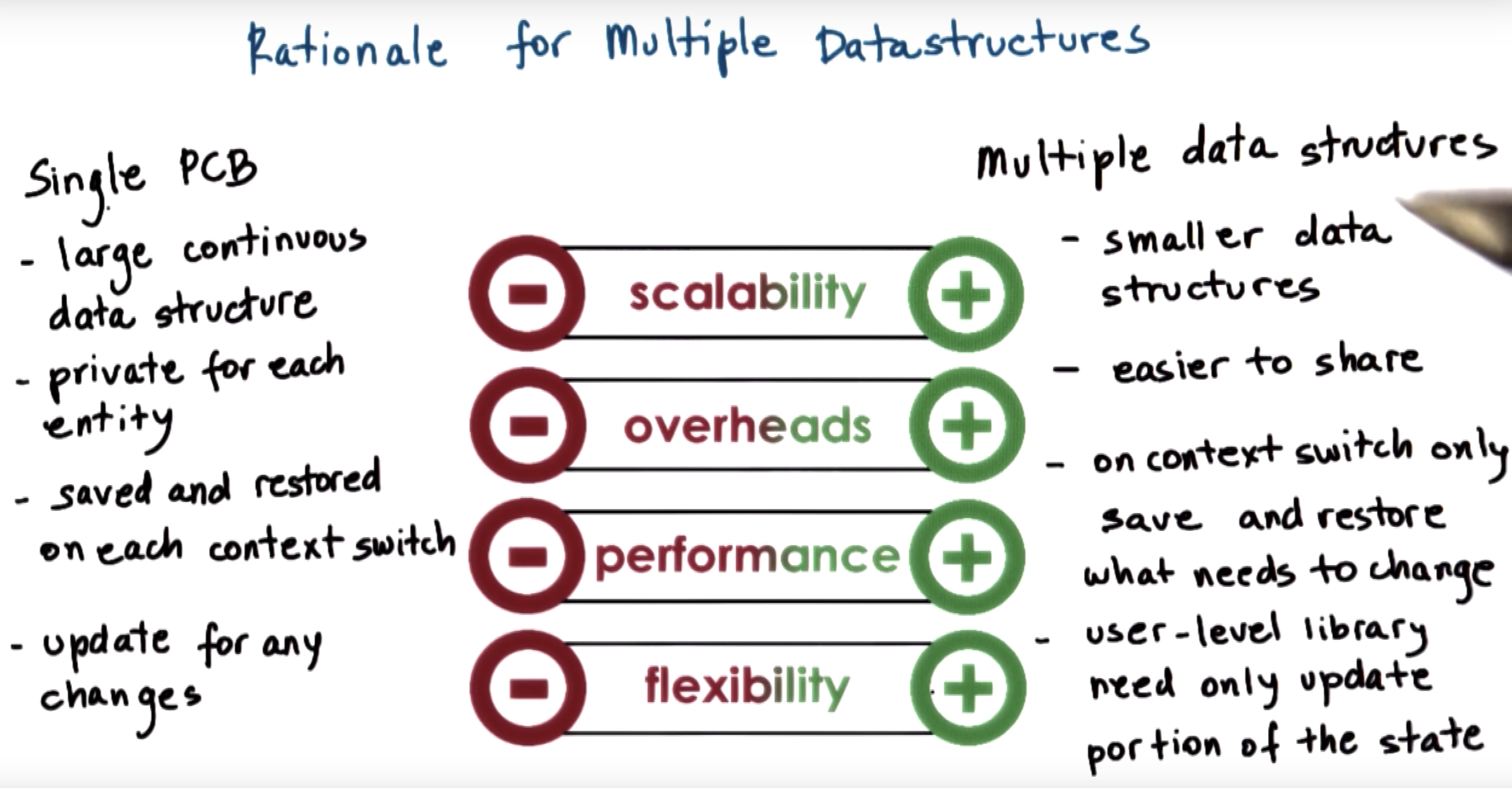
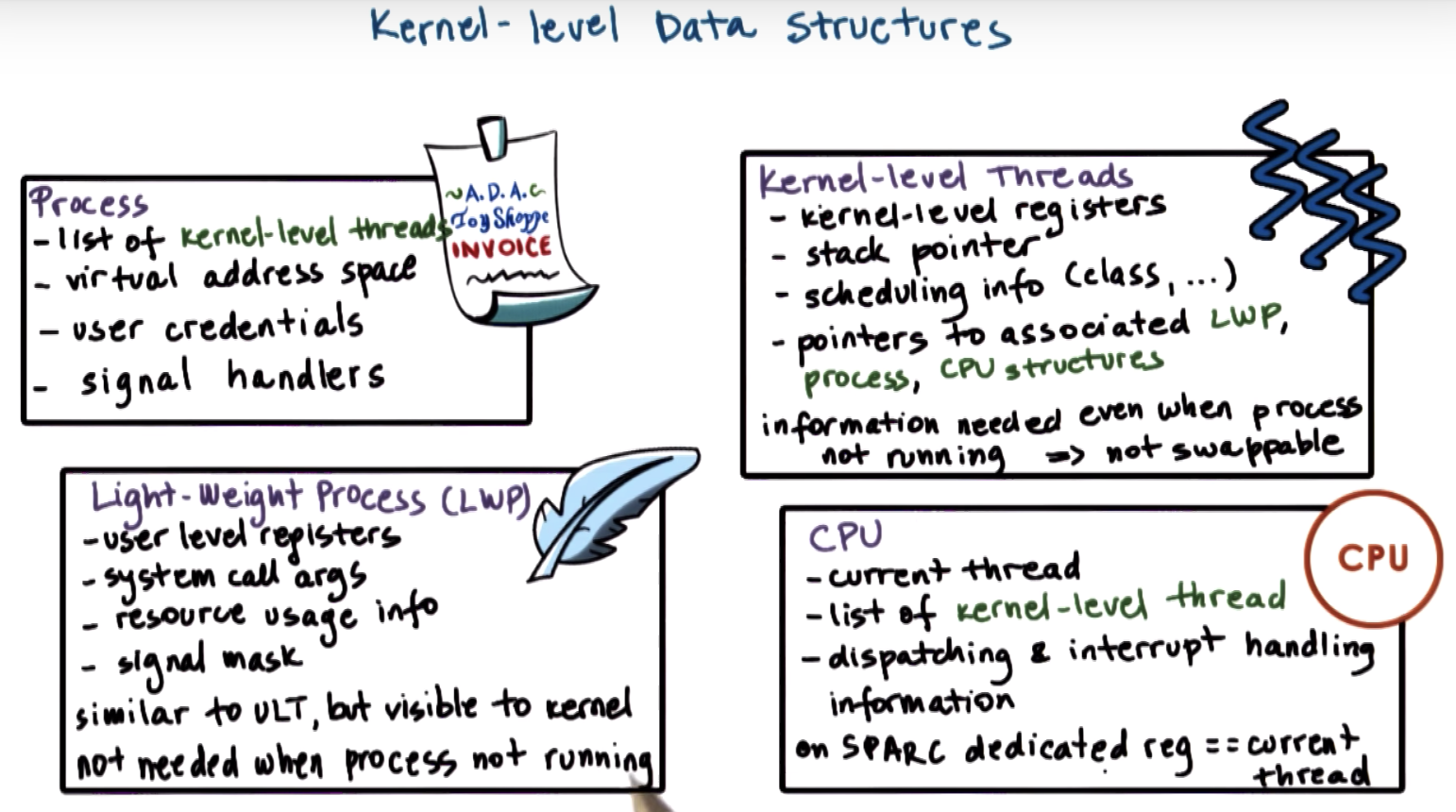
all the information about the state of this process is contained in its process control block.
however, we dont want to replicate this entire (PCB) data structure with just so as to represent different stack and register values for the kernel-level entities.
So, we will start splitting up this PCB structure to separate the information that's specifically useful to represent the execution state of kernel-level threads.
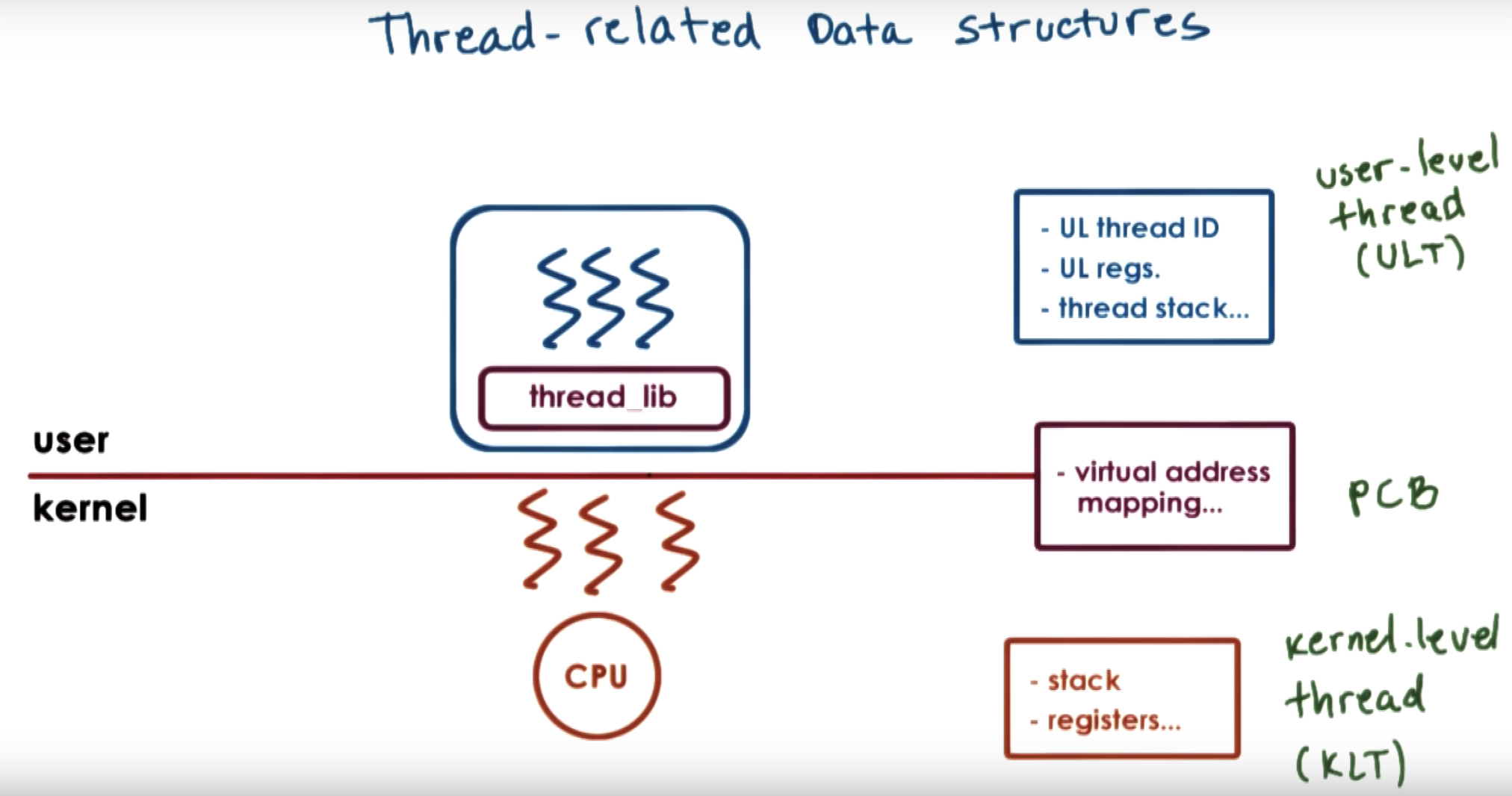
|
※ virtual address mapping ※ stack ※ registers |
↓
|
※ virtual address mapping |
|
※ stack ※ registers |
here we first assume there's only one CPU. Multithreads make the situation like there are multi virtual CPUs.
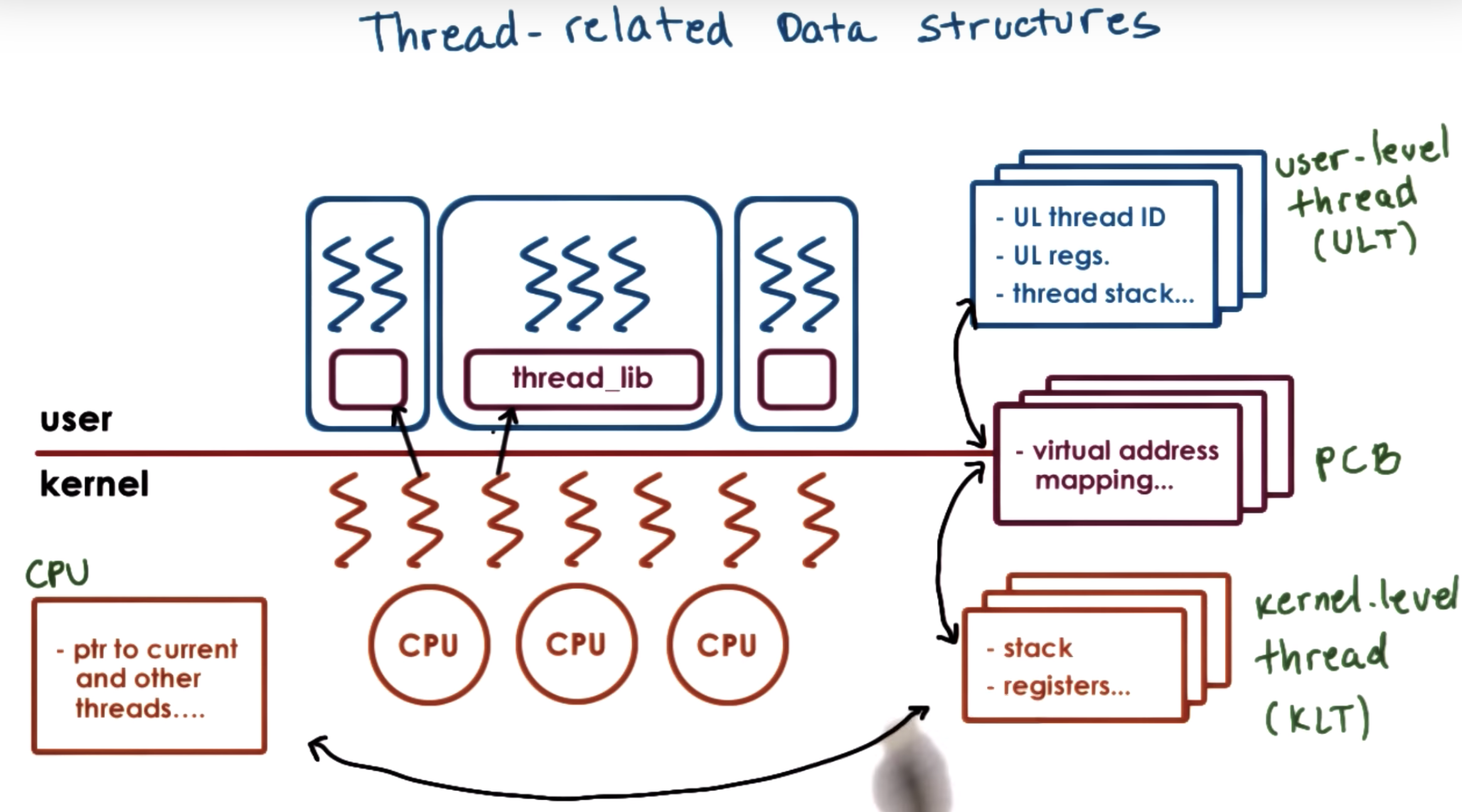
3 user level processes
7 kernels
3 CPUs
-----------------
When the kernel needs to schedule, or context switch among kernel-level threads that belong to different processes,
it can quickly determine that they point to a different process control block.
So they will have different virtual address mappings, and therefore can easily decide that it needs to invalidate the existing address mappings and restore new ones.
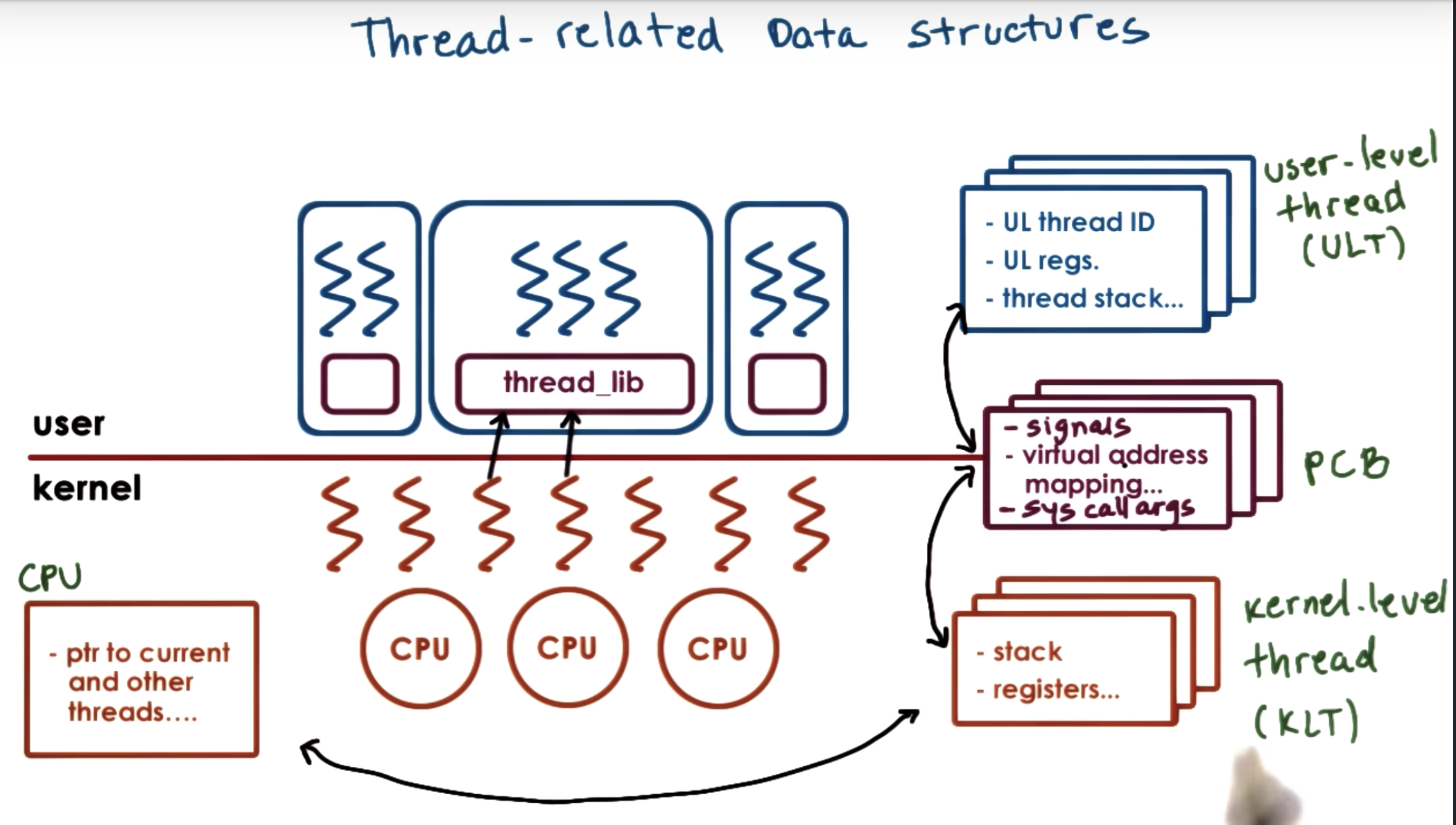
There's a portion of this PCB information that we want to preserve, like all the virtural address mappings.
But then there's a portion of it, that's really specific to the particular kernel level thread and it depends on what is the user level thread that's currently executing.
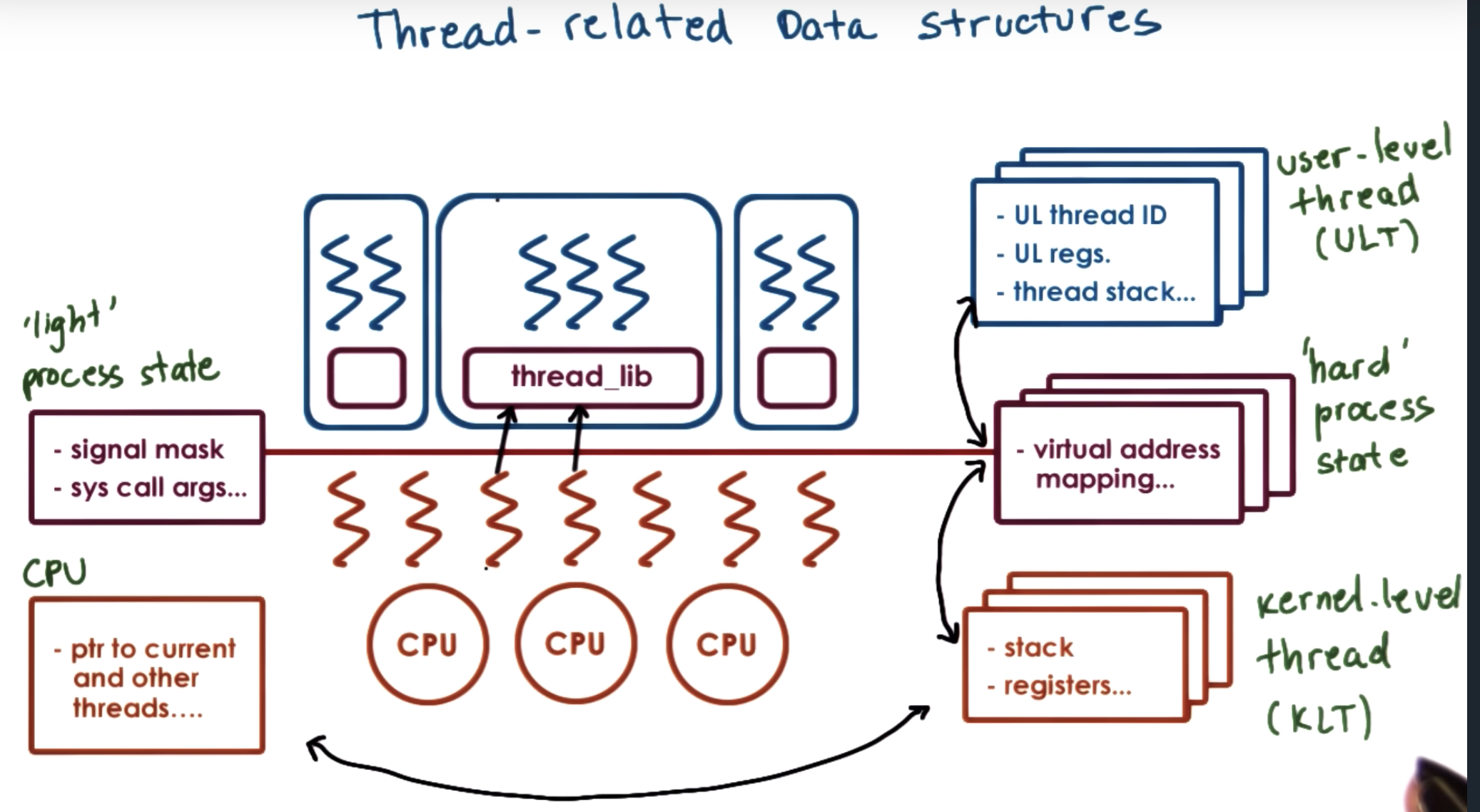
So we will split up the information that was contained originally in the PCB, and we will separate it into hard process state that's relevant for all the user level threads that execute within that process.
And the lightweight portion of process state is just a subset of the user level threads that are currently associated with a particular kernel-level thread.

Links
- Free Electrons Linux Cross Reference
- Use the Identifier Search and find the source files in which structures are defined
- Interactive Linux Kernel Map
Errata
ktread_worker is mispelled; it should read kthread_worker. You can find this struct defined in Linux Cross References such as free-electrons.com.

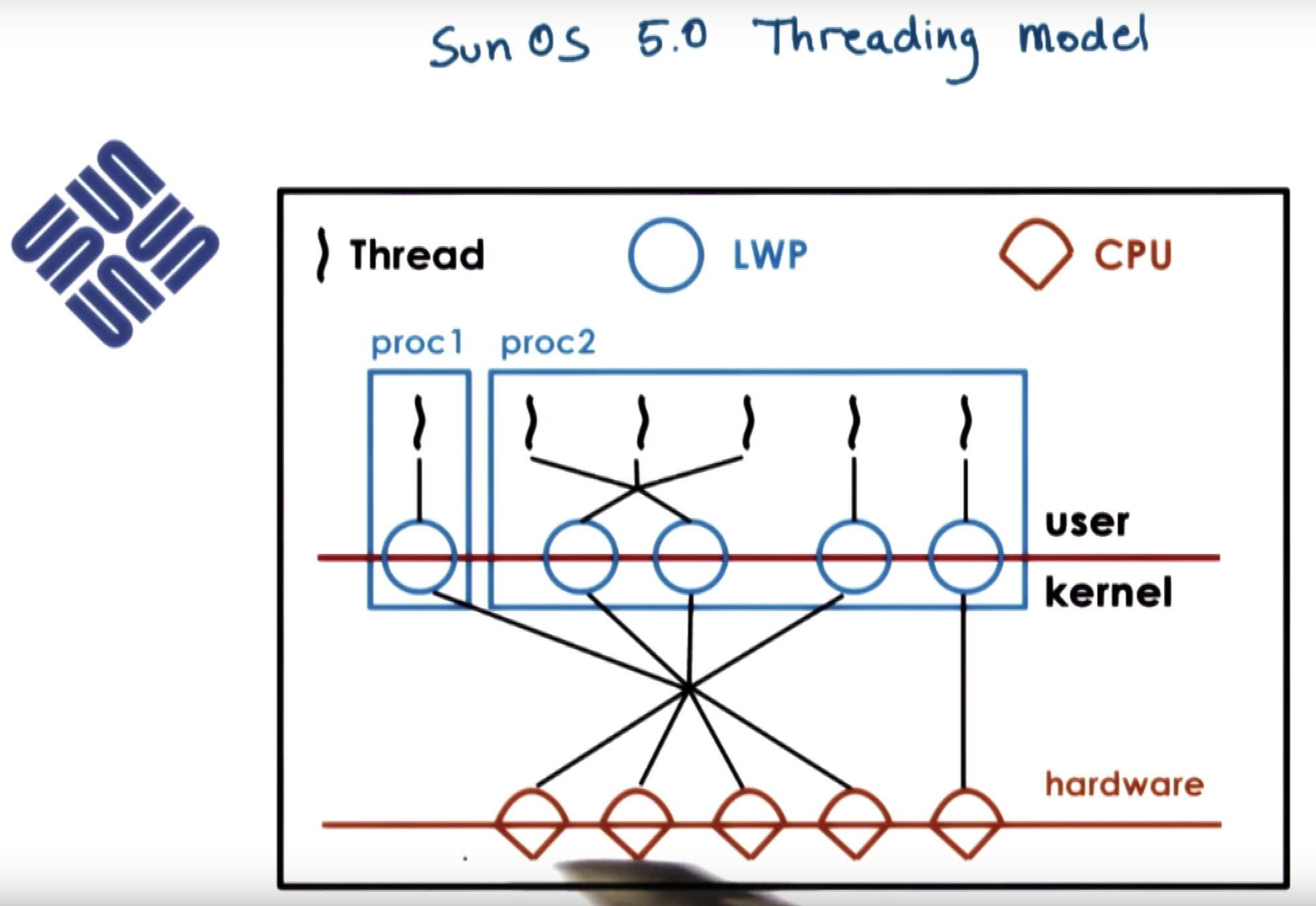
credit to Stein and Shah Paper, Figure 1.
it quickly illustrates quickly the threading model supported in the OS.
Going from the bottom up, the OS is intended for multiprocesser systems, with multiple CPUs
and the kernel itself is multi-threaded.
Both one2one and many2many mapppings are supported.
each kernel level thread that's executing a user-level thread, has a lightweight process data structure associated with it.
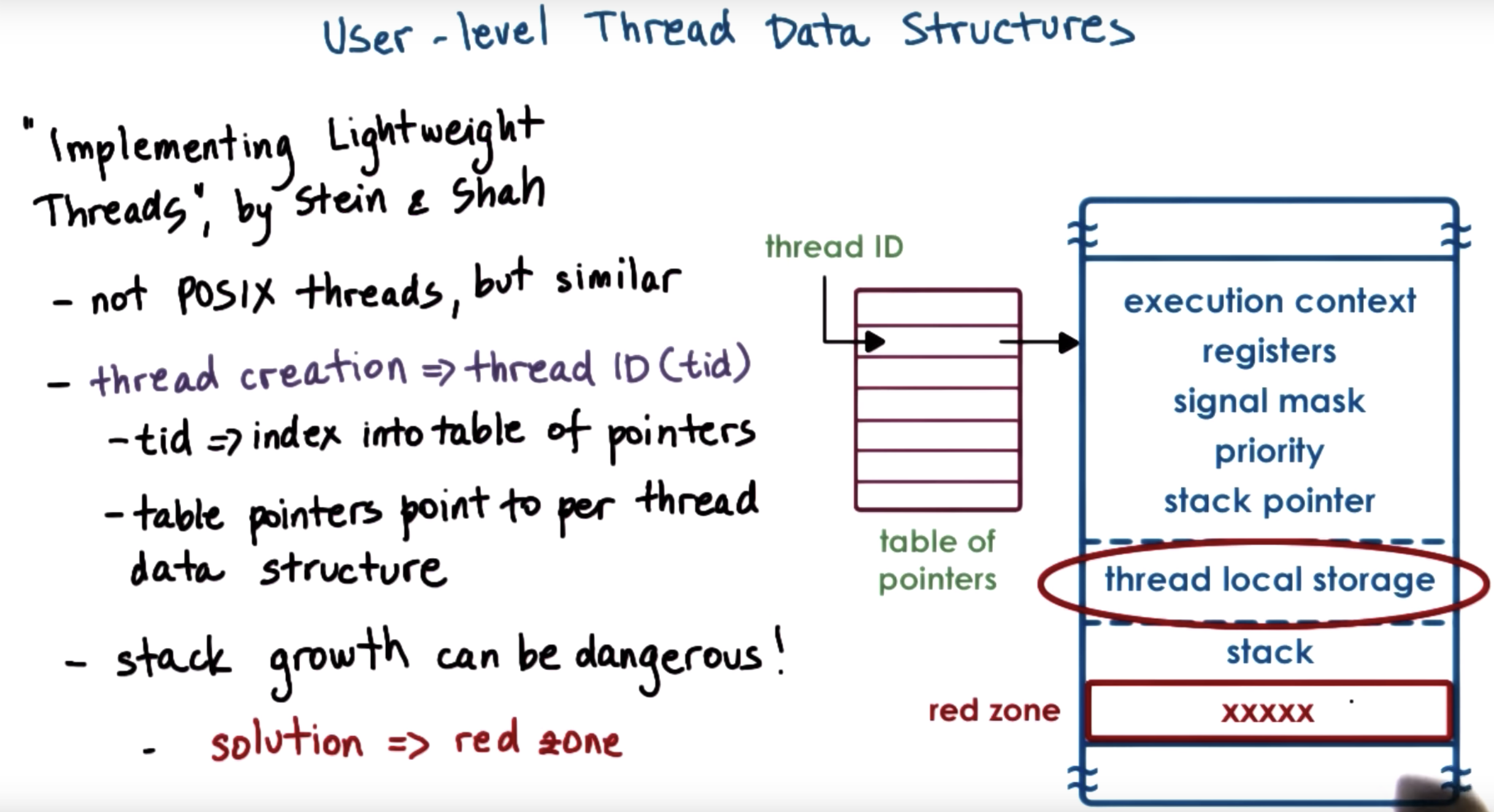
When a thread is created, the library returns a thread ID.
And this is not a direct pointer to the actual thread data structure
Instead, it's an index in a table of pointers.
it is the table pointers that in turn point to the actual thread data structure.
With this data structure, if the memory is corrupt, we can still get some useful feedback.
Also this table of pointers help the scheduler to coordinate.
The problem is stack can grow and overflow.
The solution to separate threads with a red zone.
Sun/Solaris Papers
- "Beyond Multiprocessing: Multithreading the Sun OS Kernel" by Eykholt et. al.
- "Implementing Lightweight Threads" by Stein and Shah
Sun/Solaris Figures
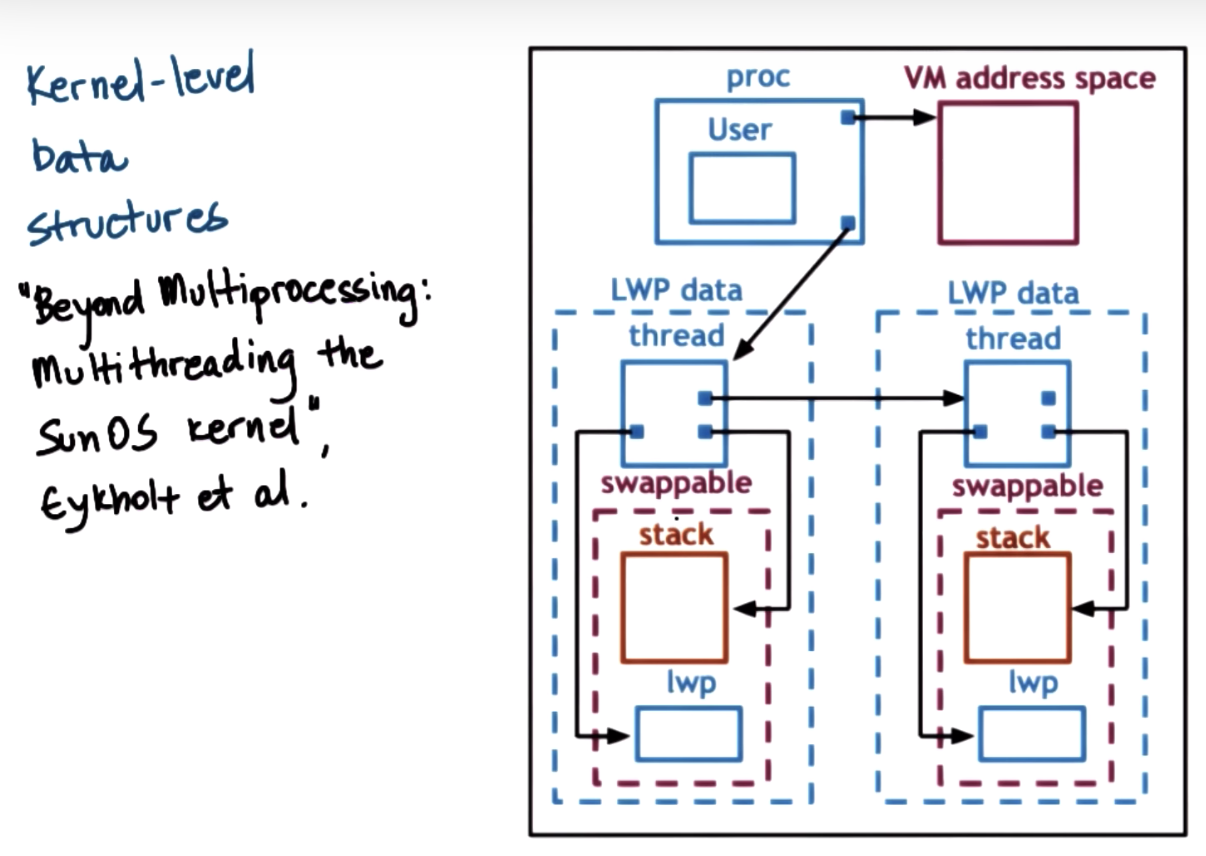
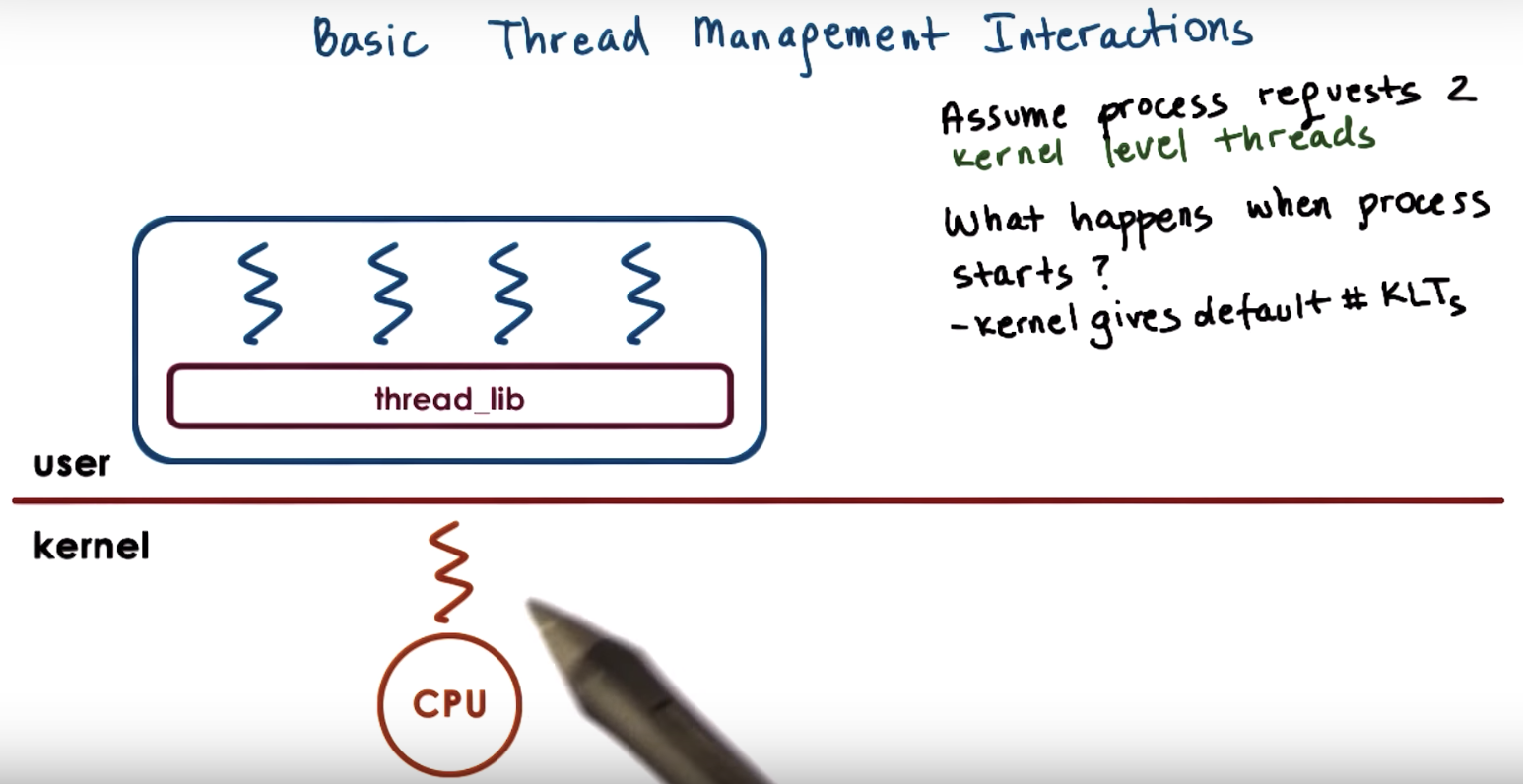
at any given point of time, the actual level of concurrency is 2.
first there's only one kernel level thread (by default), and the accompanying lightweight thread.
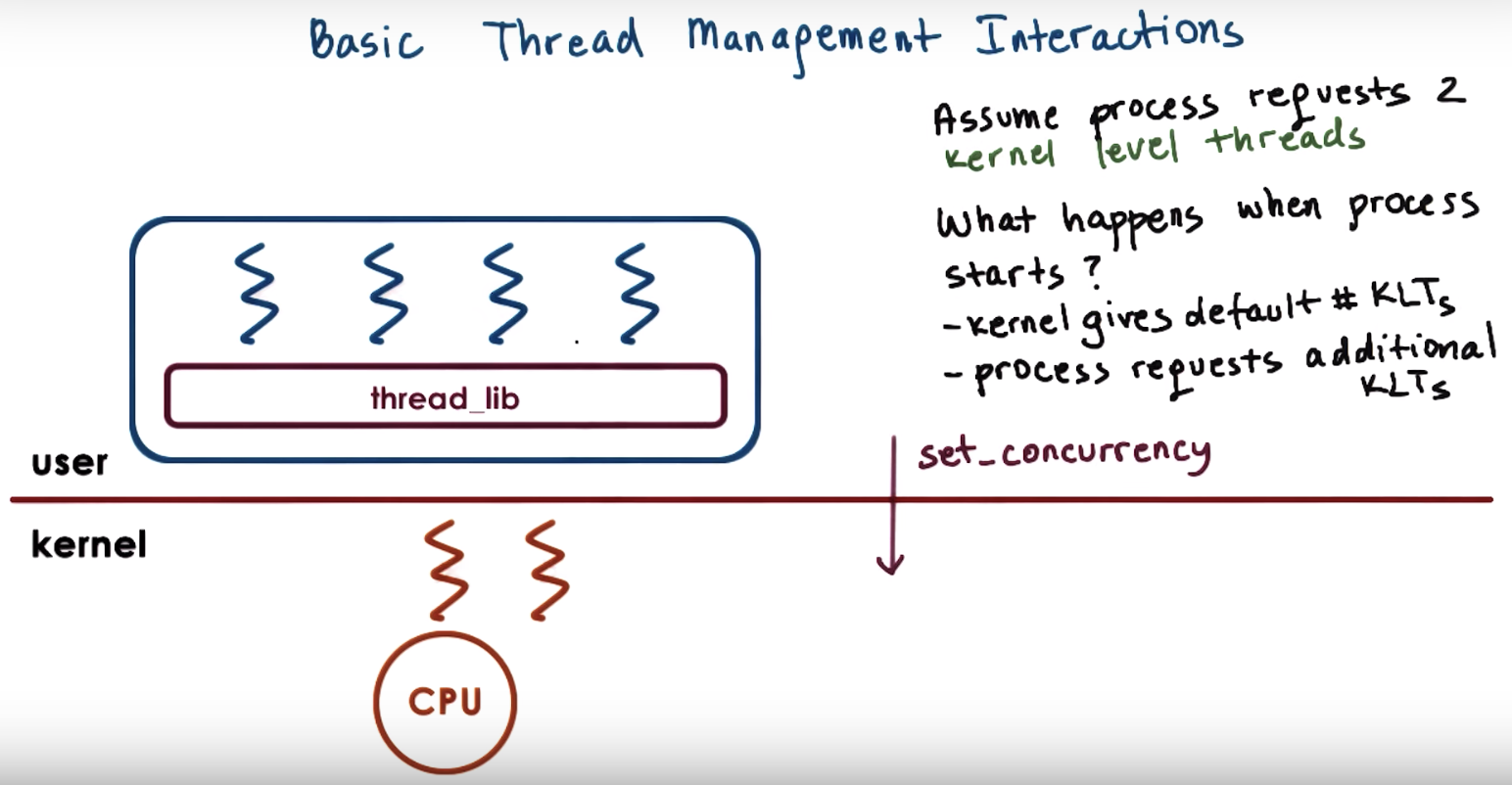
Then the process will request additional kernel-level thread, and the way it's done is that
the kernel now supports a system call, called "set_concurrency", creating a new thread.
Now the 2 user level threads, mapping to the kernel level threads, need to perform I/O operation.
So the kernel level threads are blocked as well.
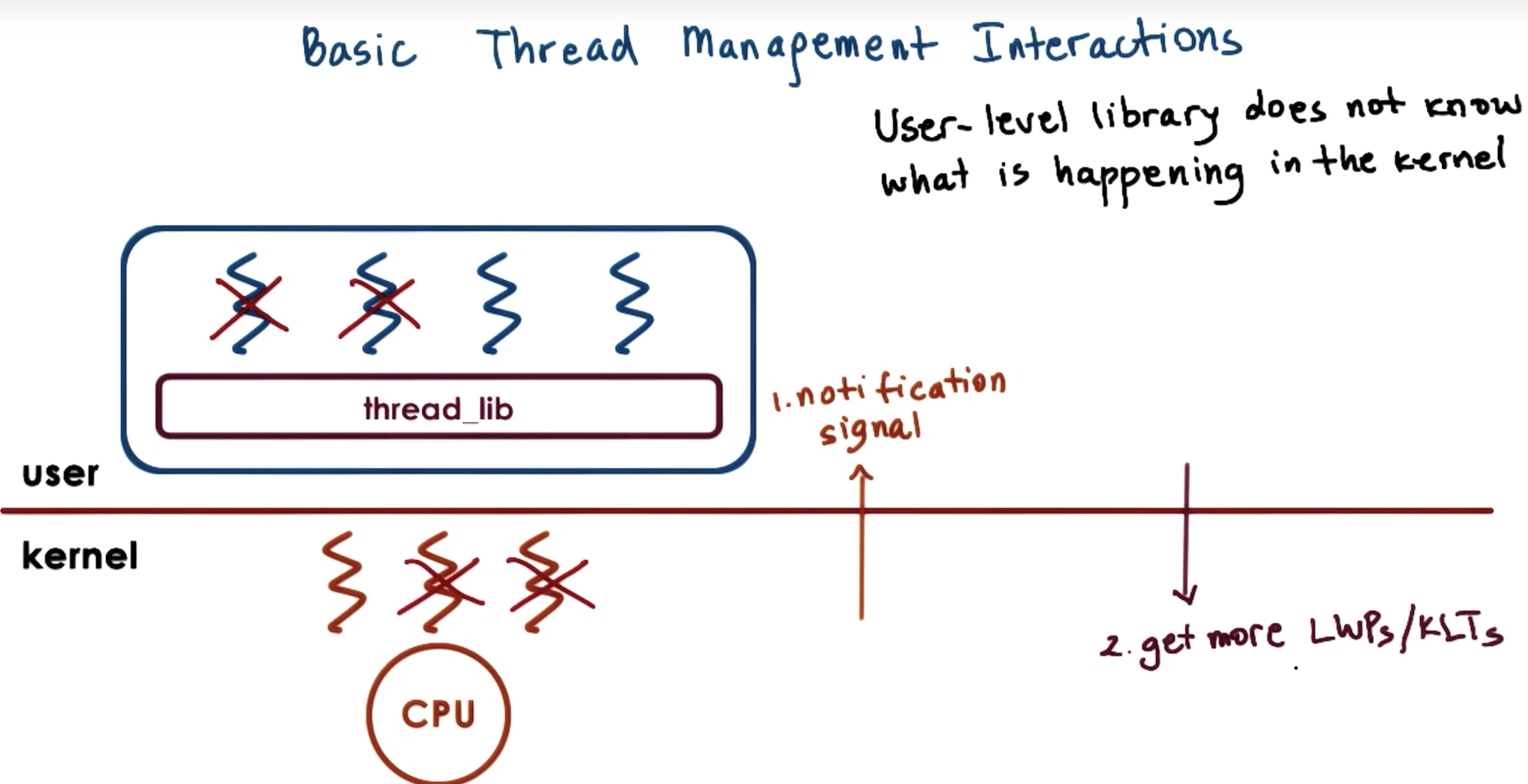
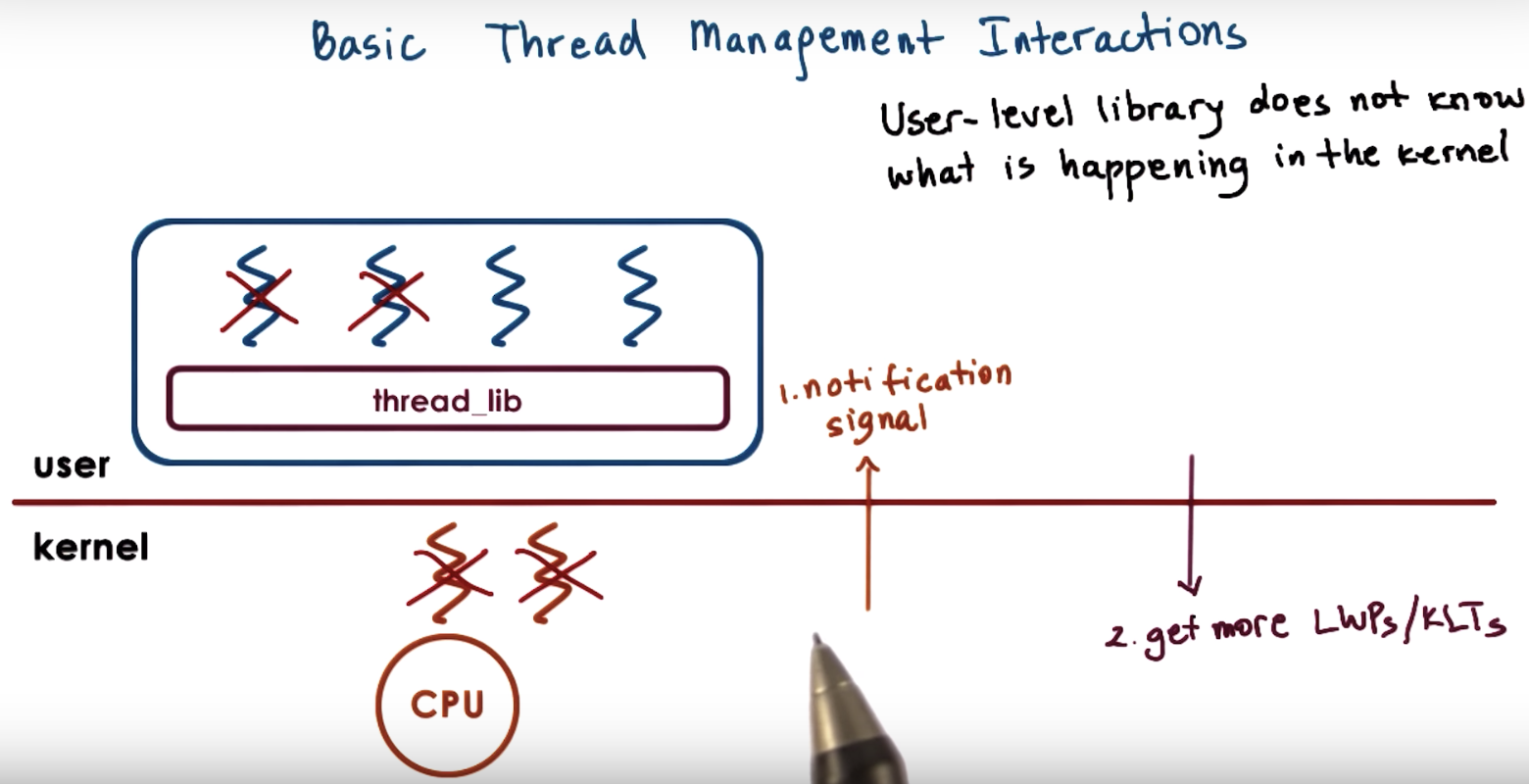
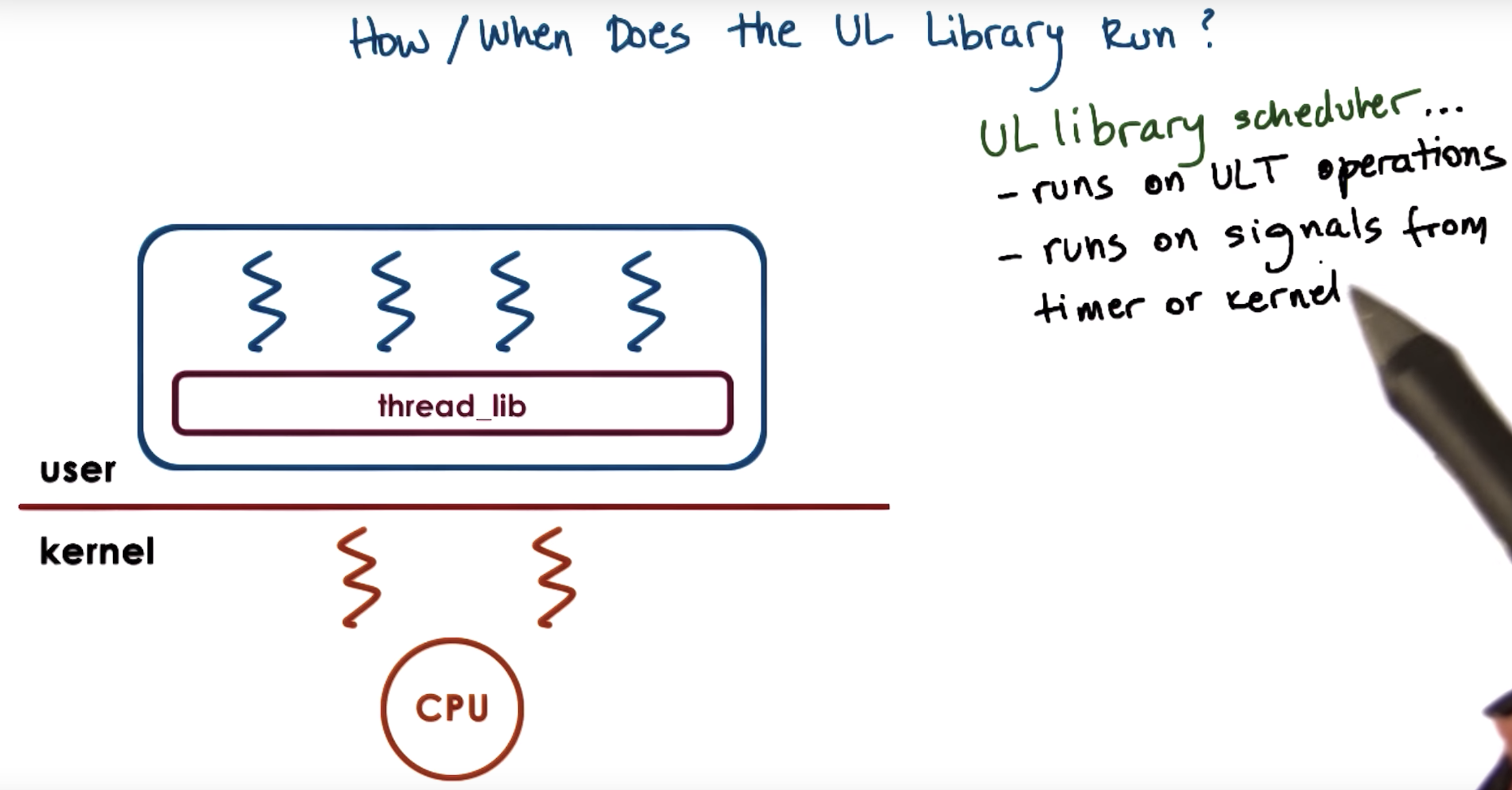
kernel should notify the user level library before it blocks the kernel-level threads.
Then the user level library can look at its run queue, it can see that it has multiple runnable user-level threads,
and in response can let the kernel know, call a system call, to request more kernel level threads (KLT) or light weight processes.
Now the kernel allocates an additional KLT, and the
at a later time, the kernel knows that one thread is pretty much constantly idle,
because we said that's the natural state of this particular application.
Maybe the kernel can tell the user level library that the KLT is no longer available


complex situation: multiple CPUs
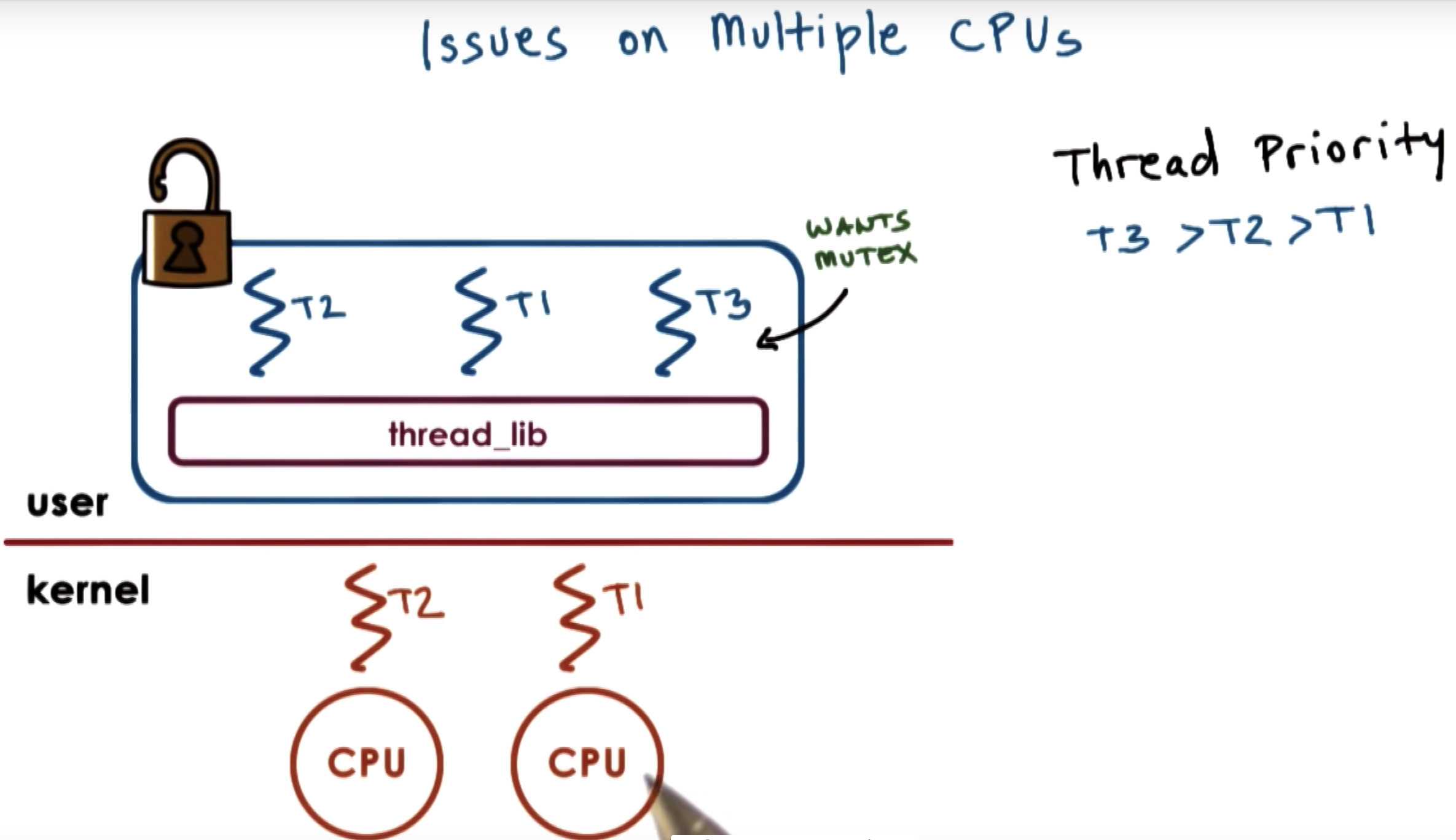
at first, T2 holds a block, and T3 is blocked, alghough having the highest priority.
and also T1 is running on the other kernel level thread on the other cpu
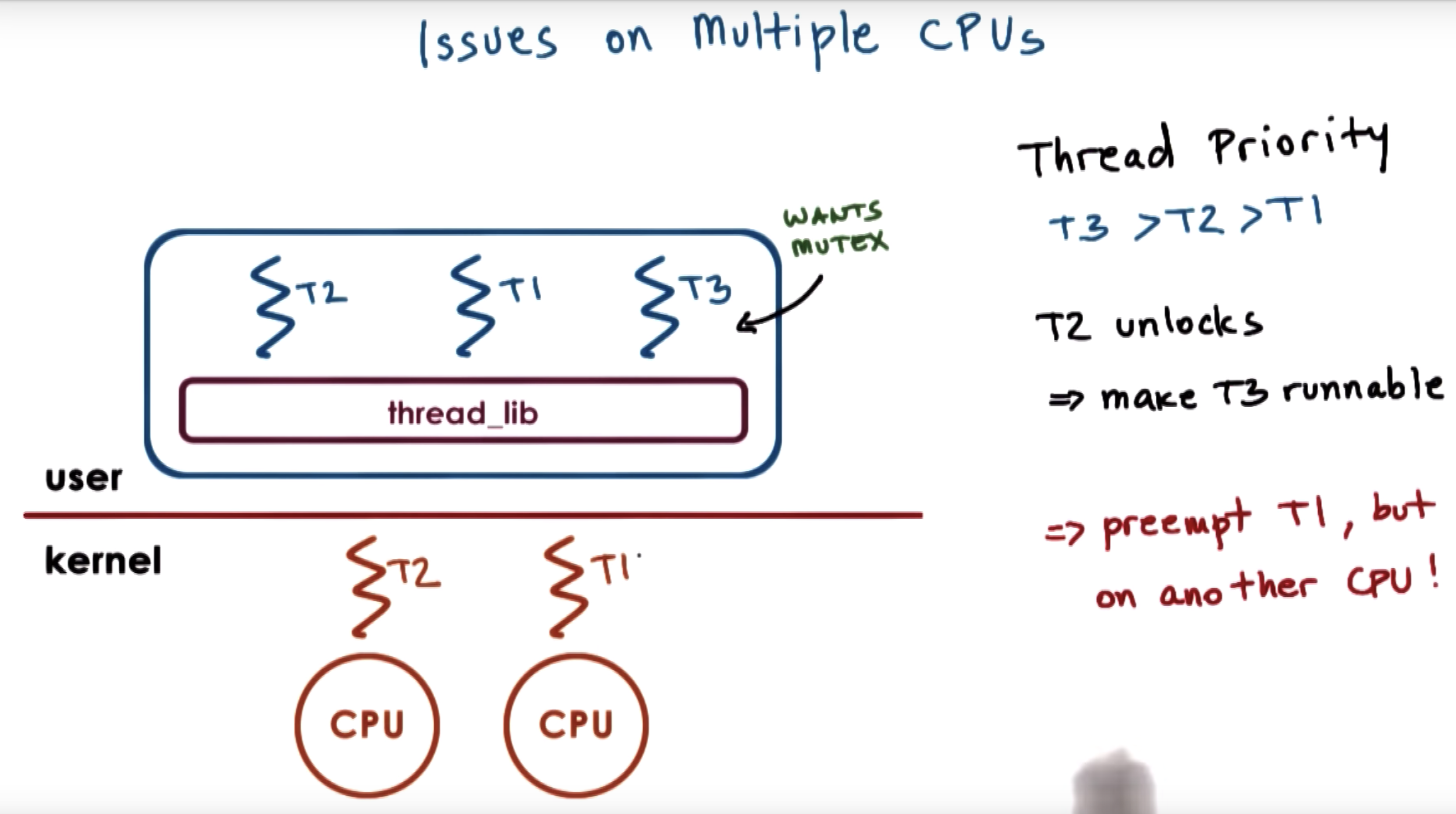
at some point T2 releases that mutex. The user level library is notified.
Now T1 T2 and T3 are runnable.
So we need to make sure that T3 gets to execute.
T1 needs to be preempted, and context switched to T3
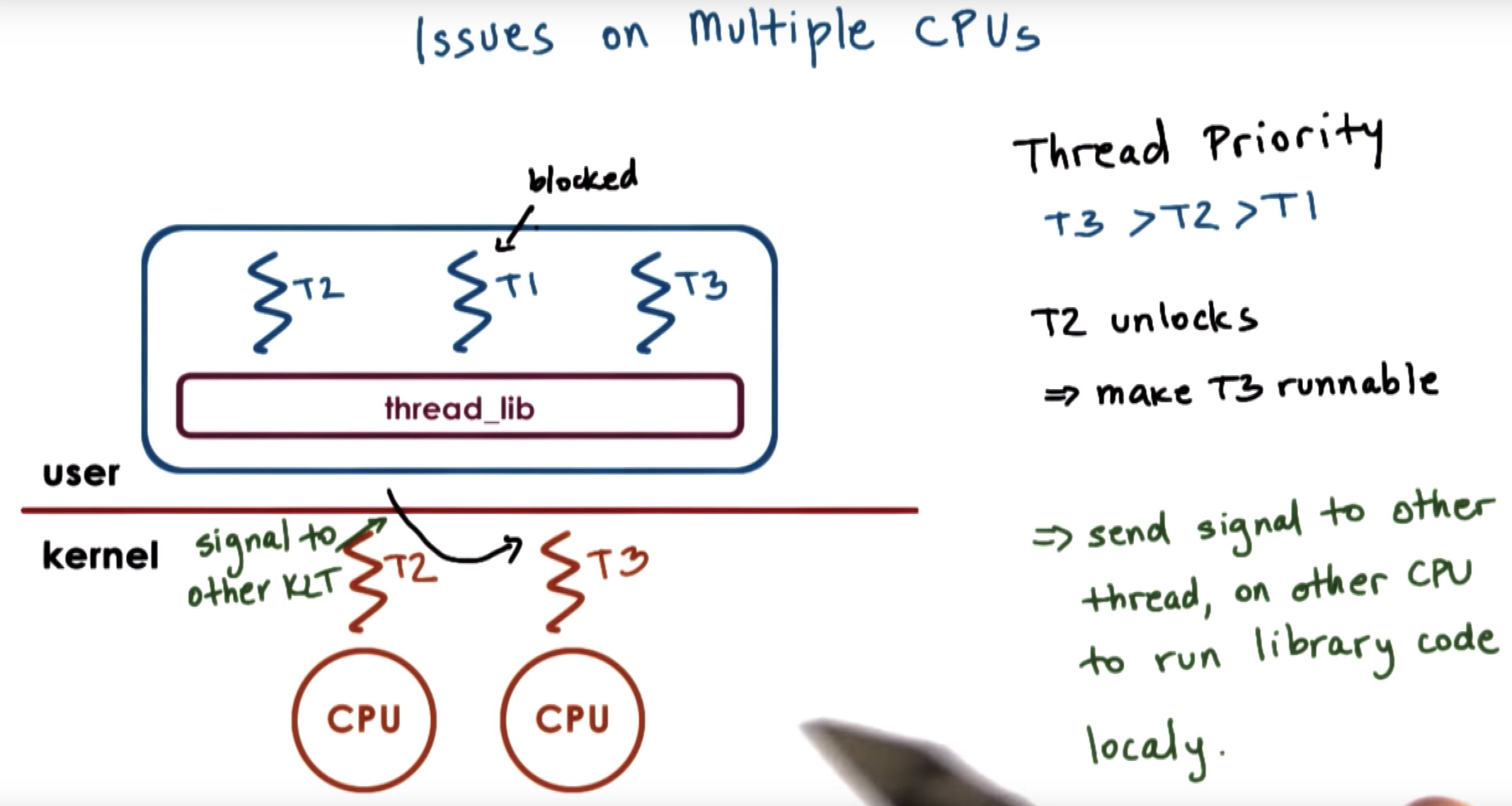
However, T1 is on the other CPU and we need to notify this other CPU to update its registers and program counters.
We can not directly modify registers on one CPU when executing on another CPU
What we need to do instead is to send some signal or interrupt from the context of one thread on one CPU to the other thread ont the other CPU.
Then CPU-2 will schedule T3 to be executed and T1 to be blocked.
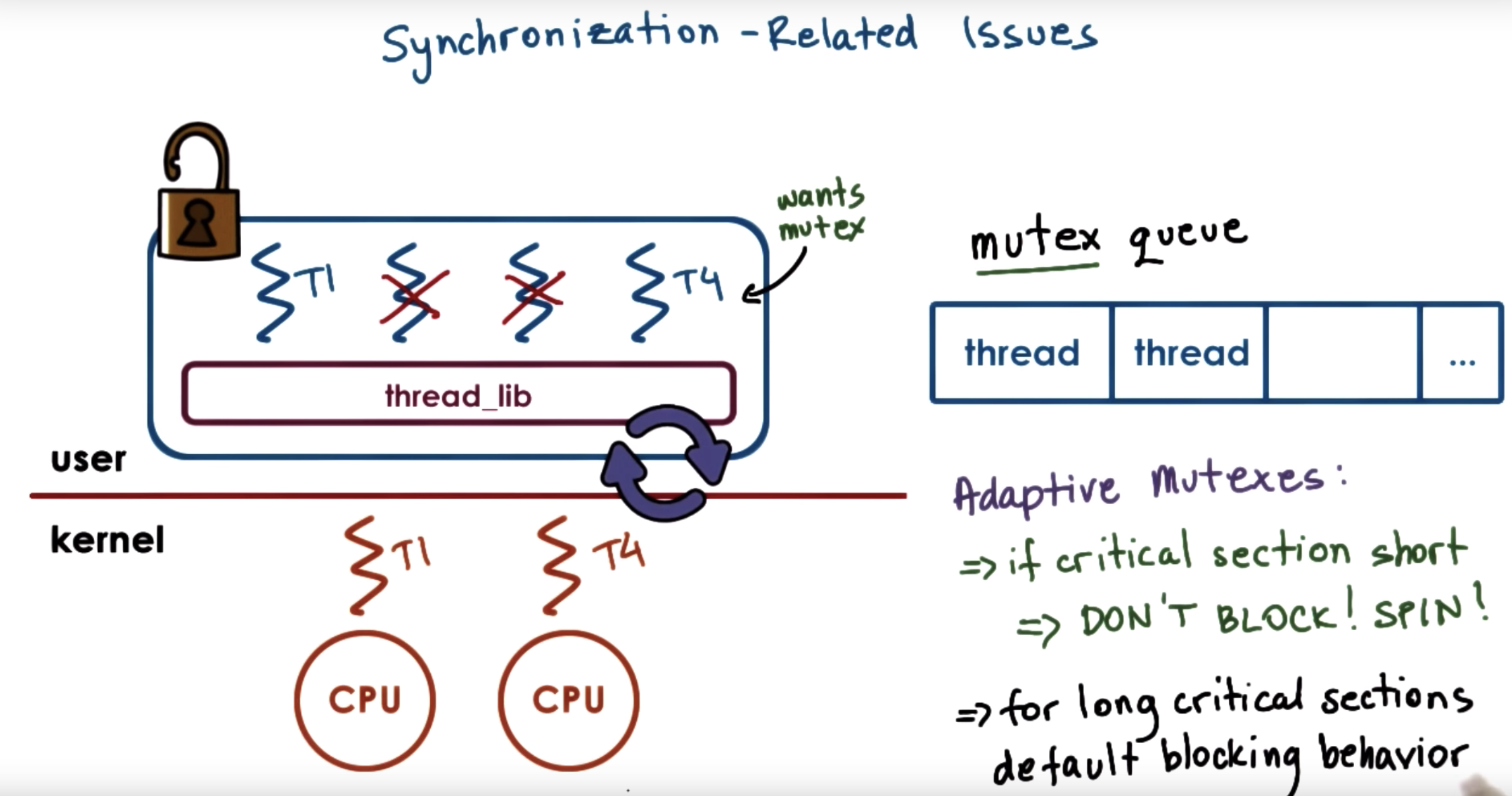
Another interesting case: adaptive mutexes
here the information of certain mutex is pretty useful and we have stored it in the data structure.


Links
- Free Electrons Linux Cross Reference
- Use the Identifier Search and find the source files in which structures are defined
- Interactive Linux Kernel Map
interrupts vs signals


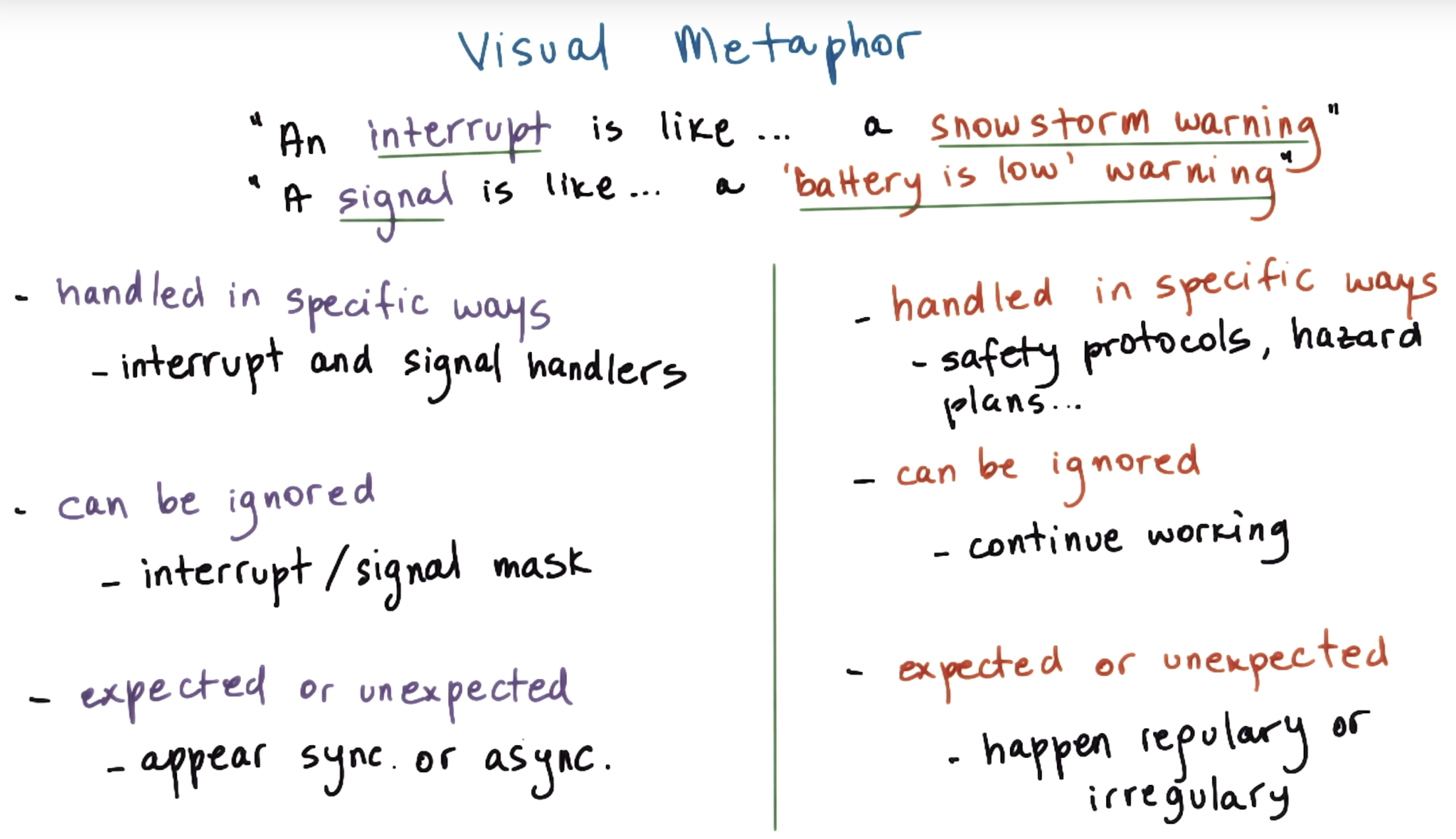

interrupt
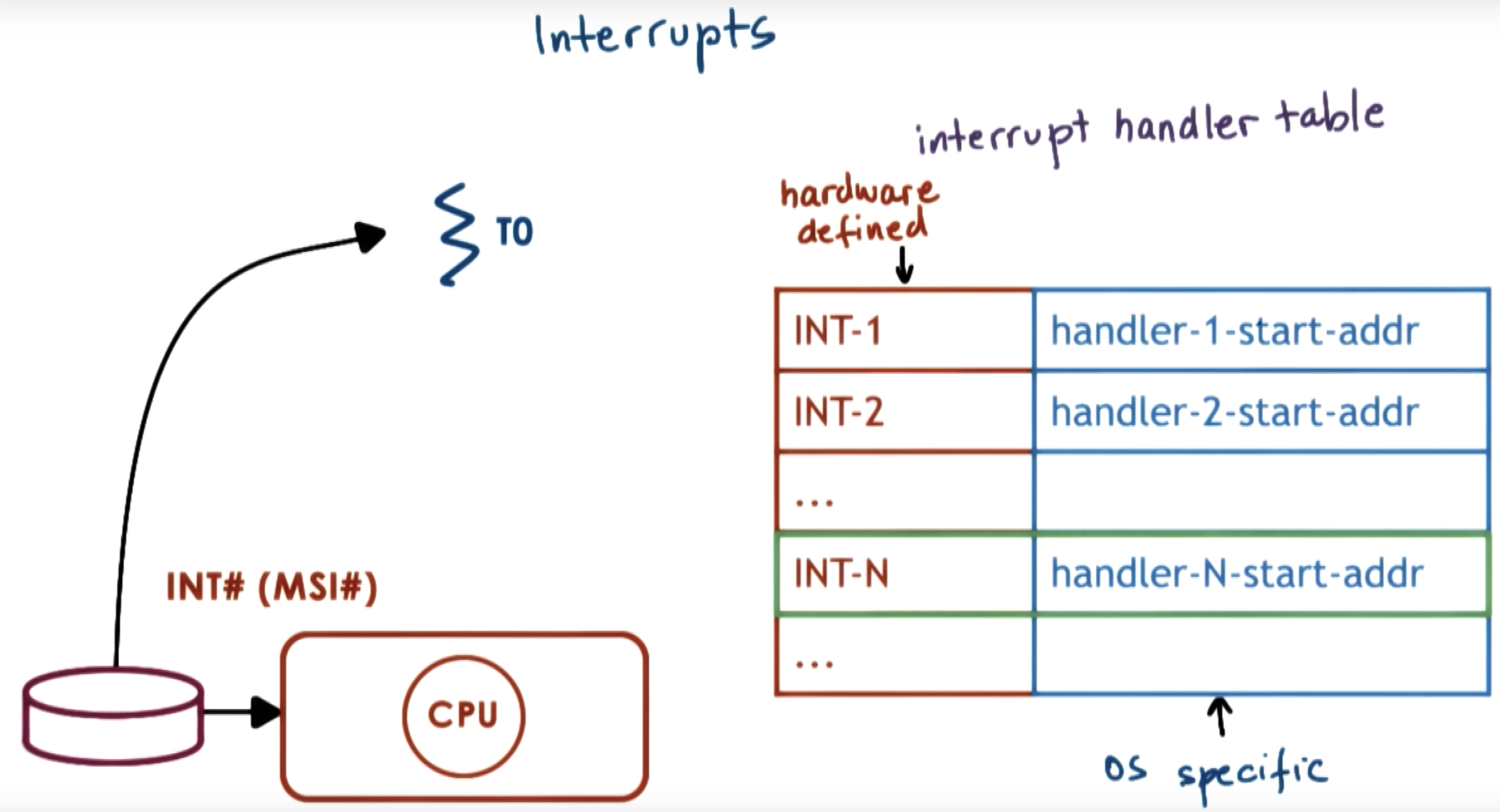
MSI: message signal interrupter
signals

illegal memory requirement => signal being generated => called SiGSEGV

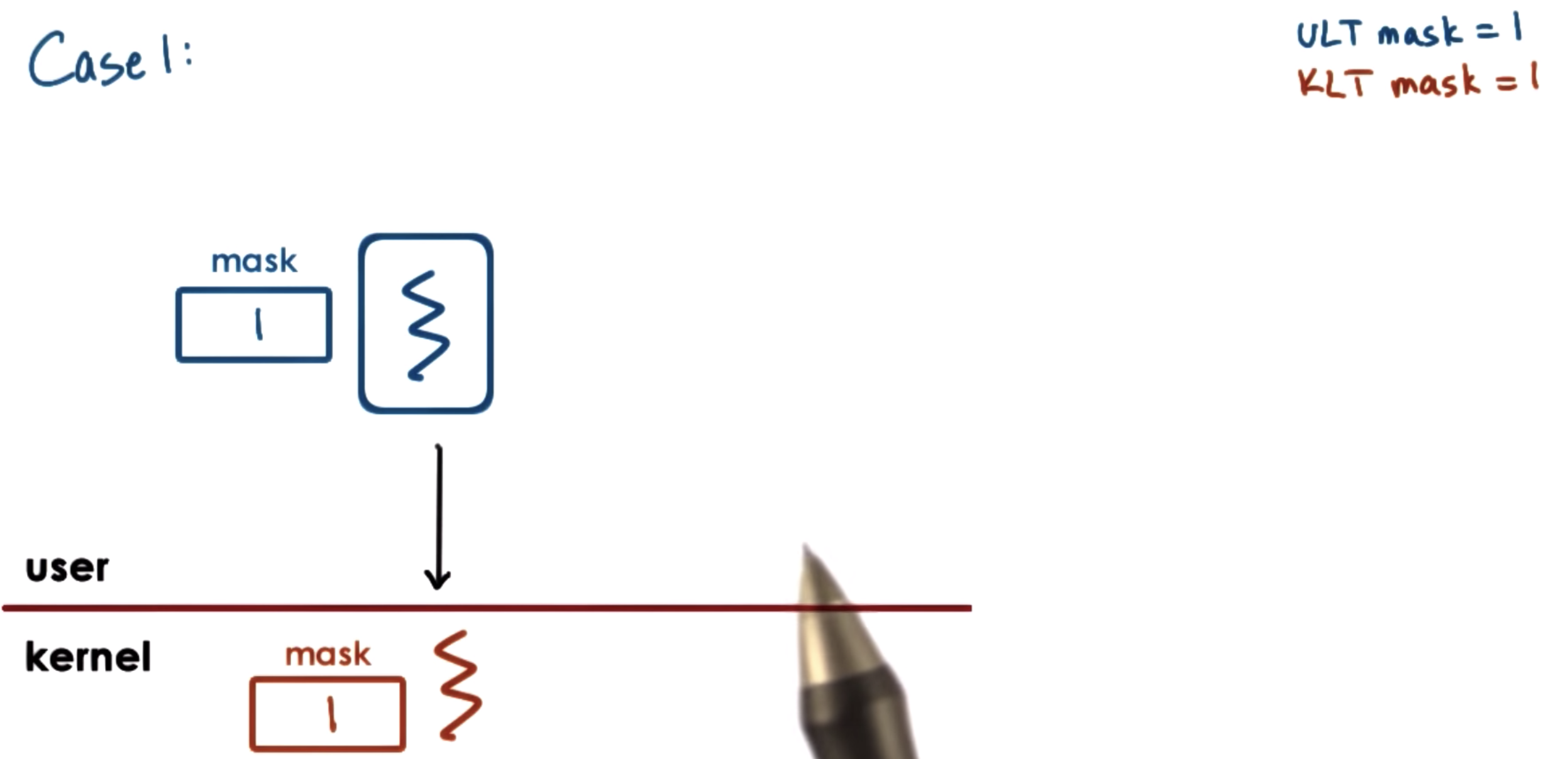
disable interrupts and signals
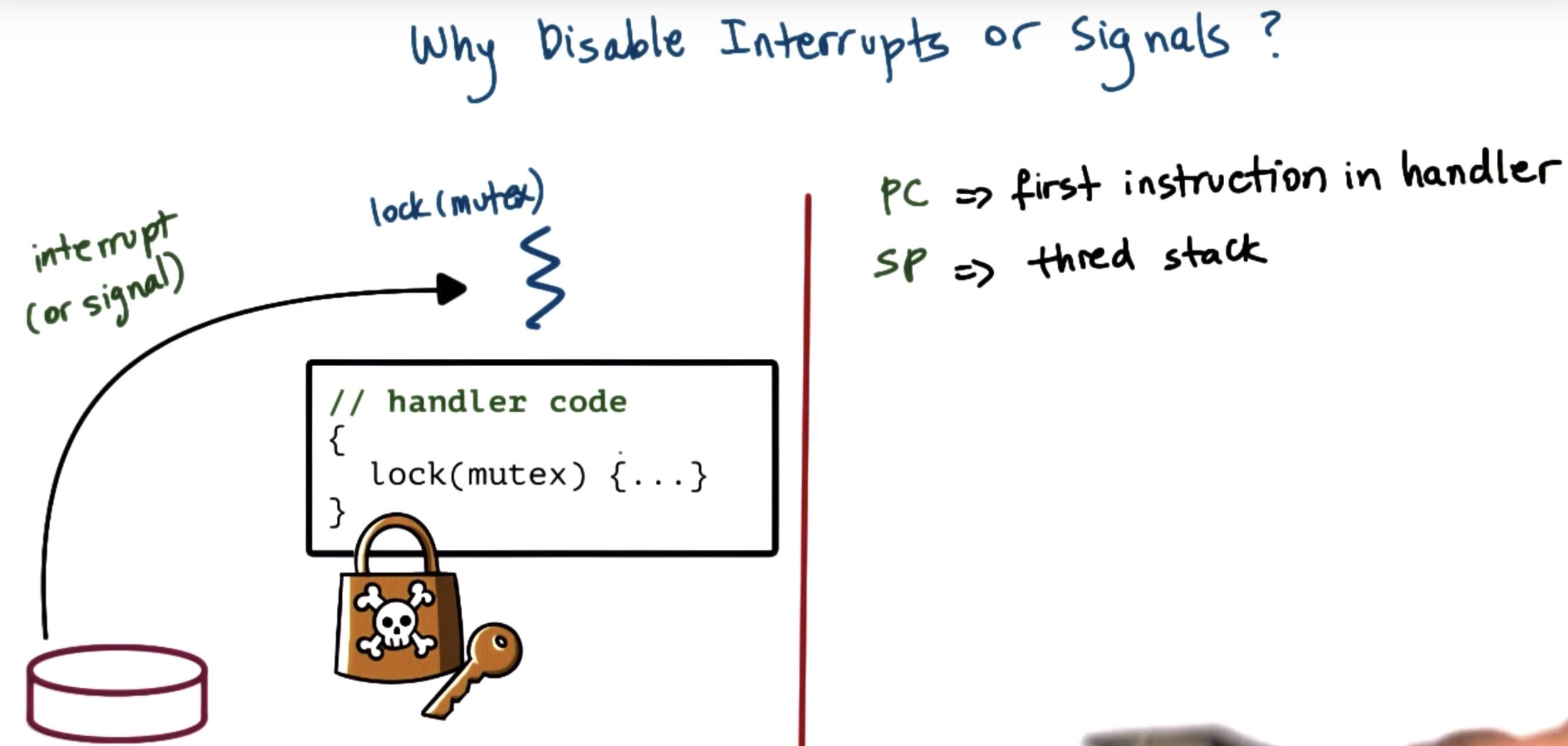
PC => some instruction in thread
if the handler code needs some state that other threads in the system may be accessing, then we have to use mutexes.
howeve, if that thread to be interrupted have already had that mutex, then we have a deadlock. (WHY???)

one possible solution is to keep handler code simple to avoid the deadlock
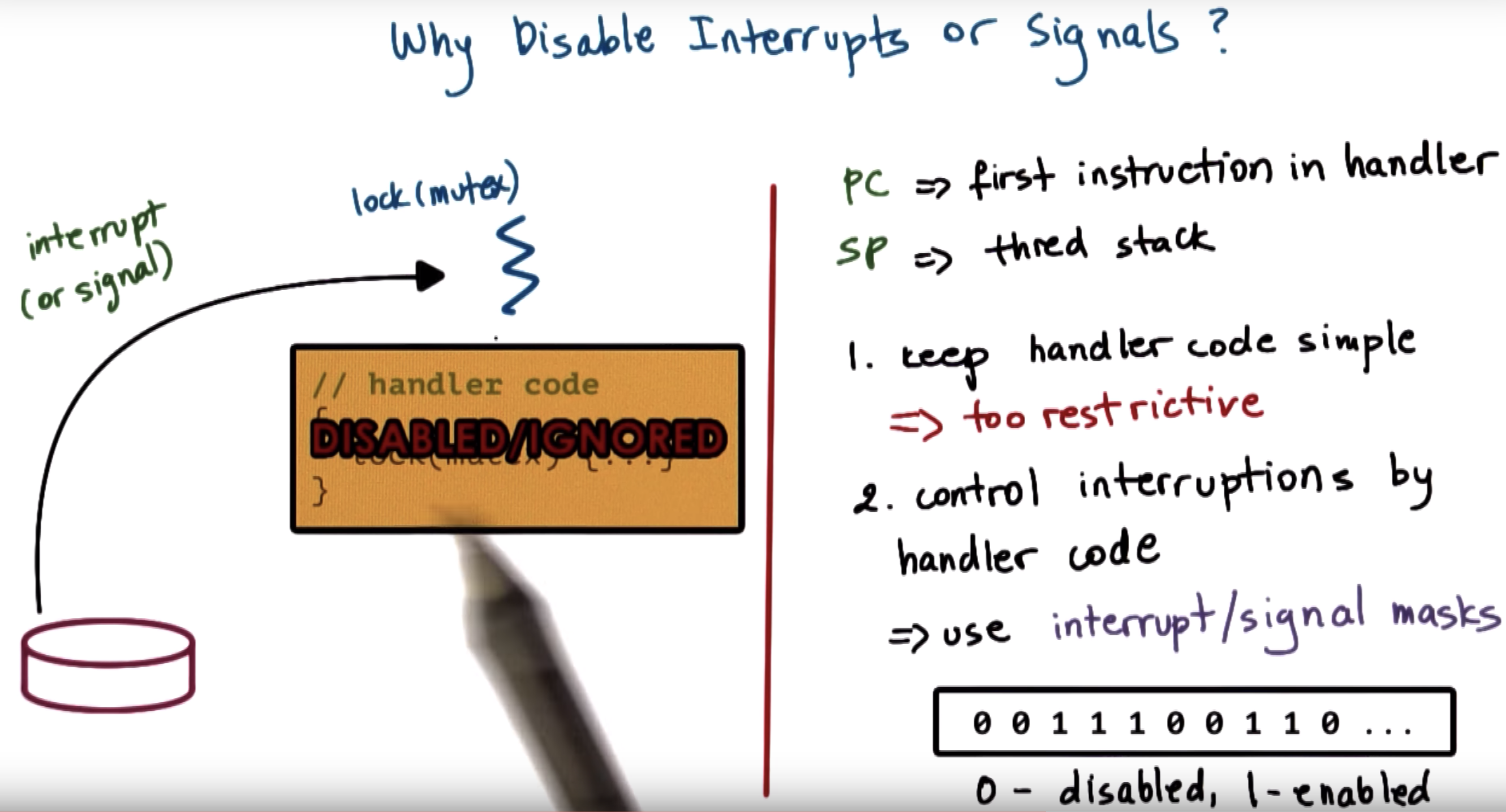
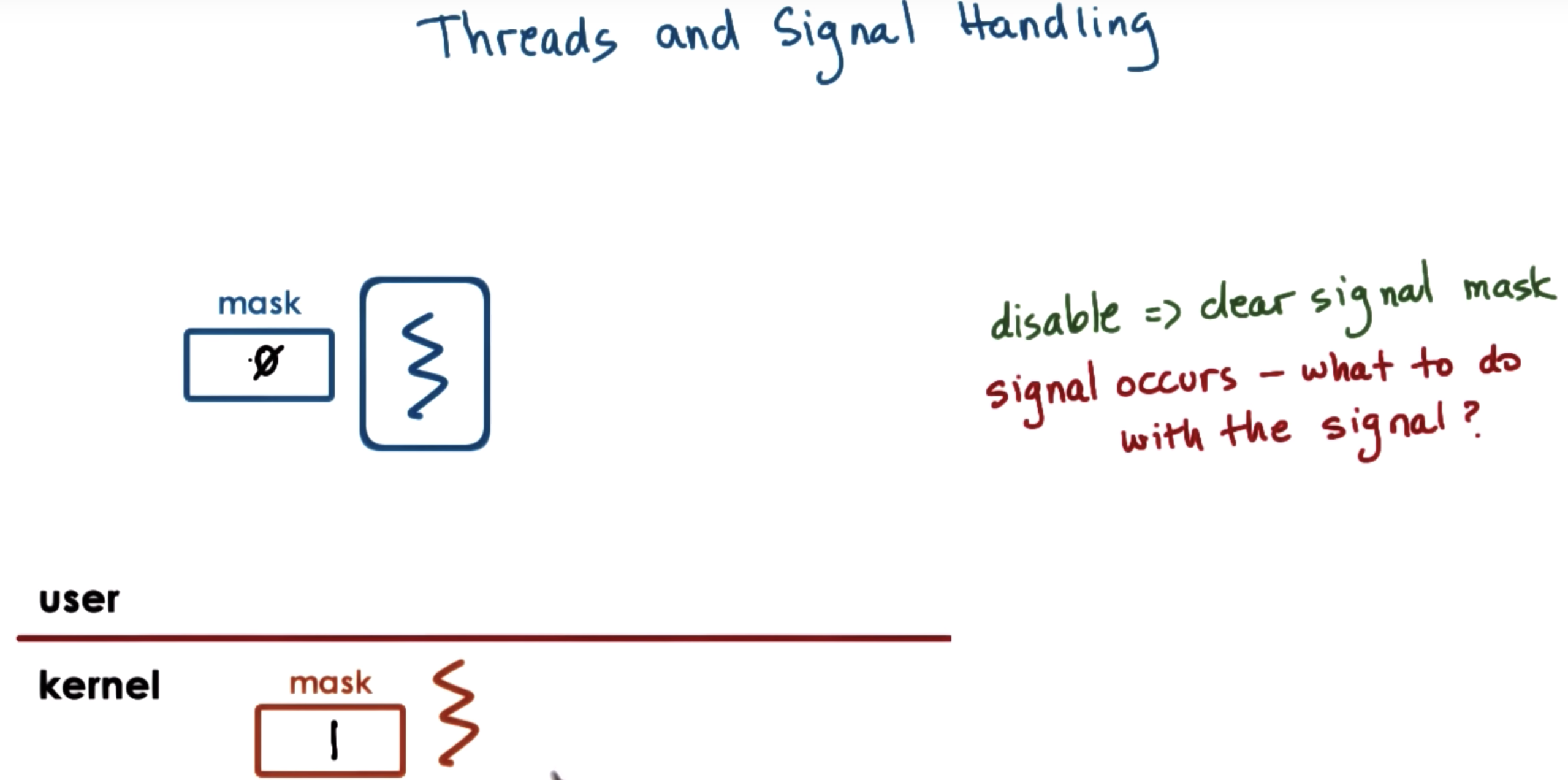
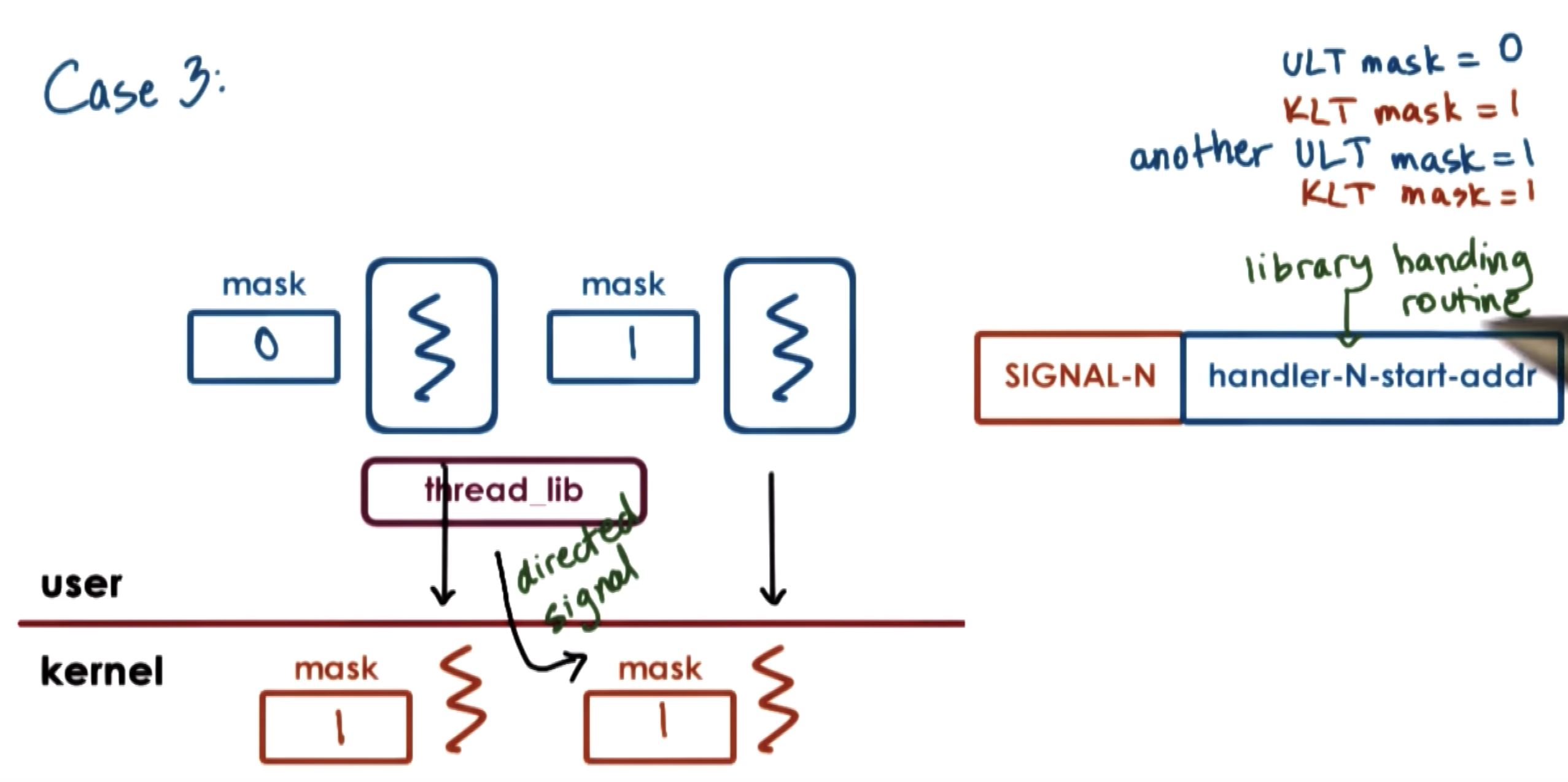
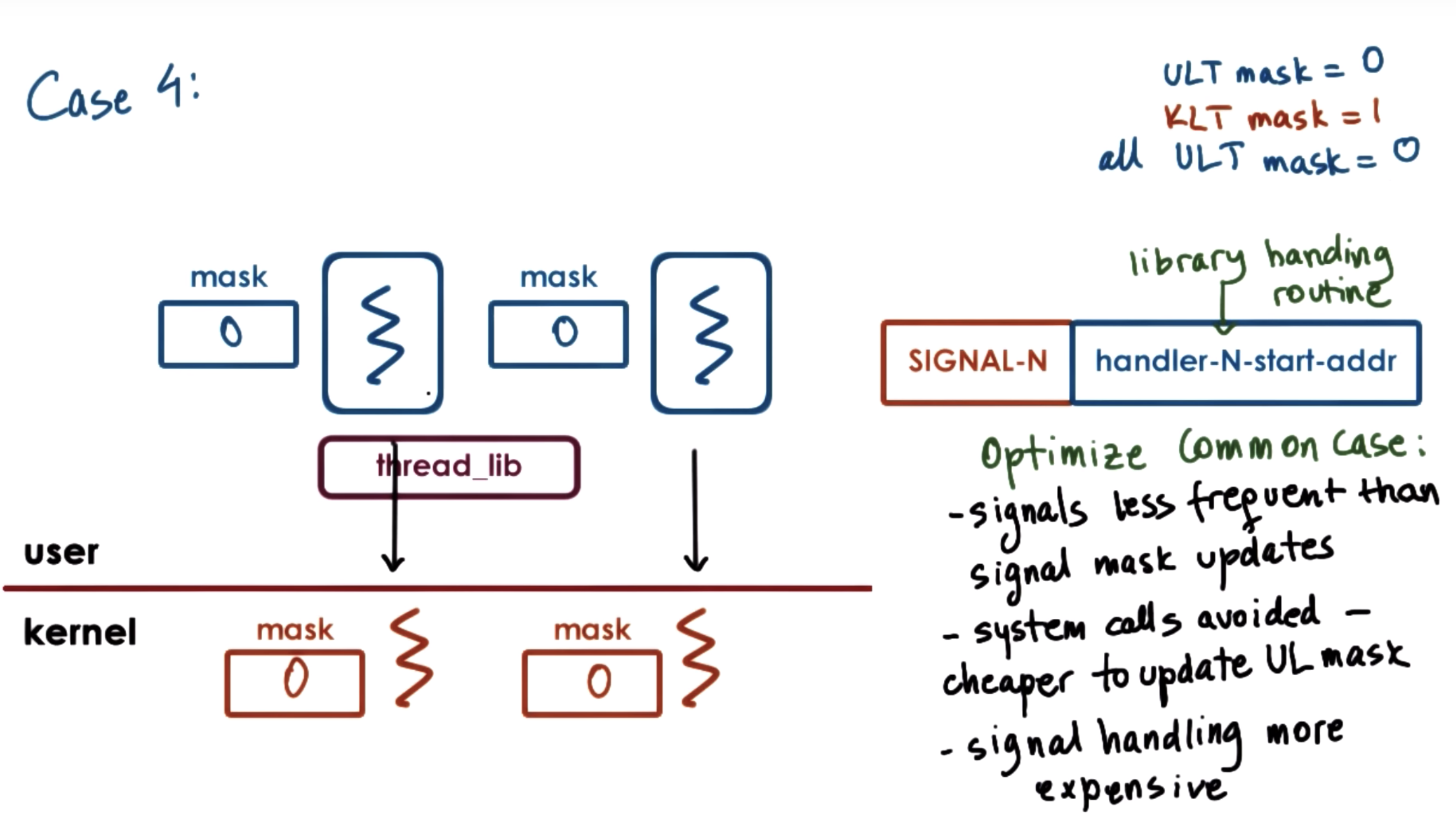
masks allow us to enable and disable the interrupt or signal dynamically.
so the masks should be checked first.
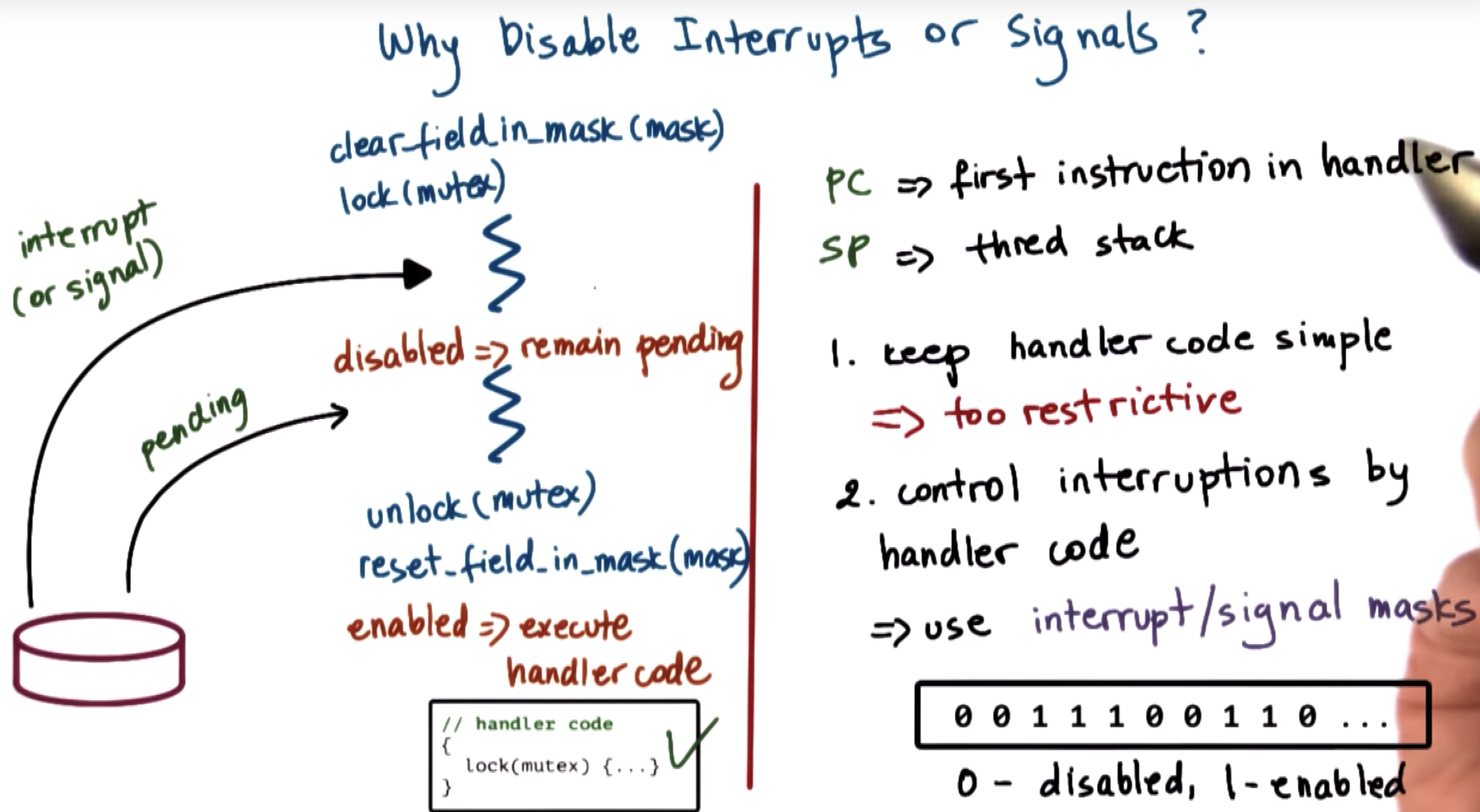

inturrupts on multicore systems
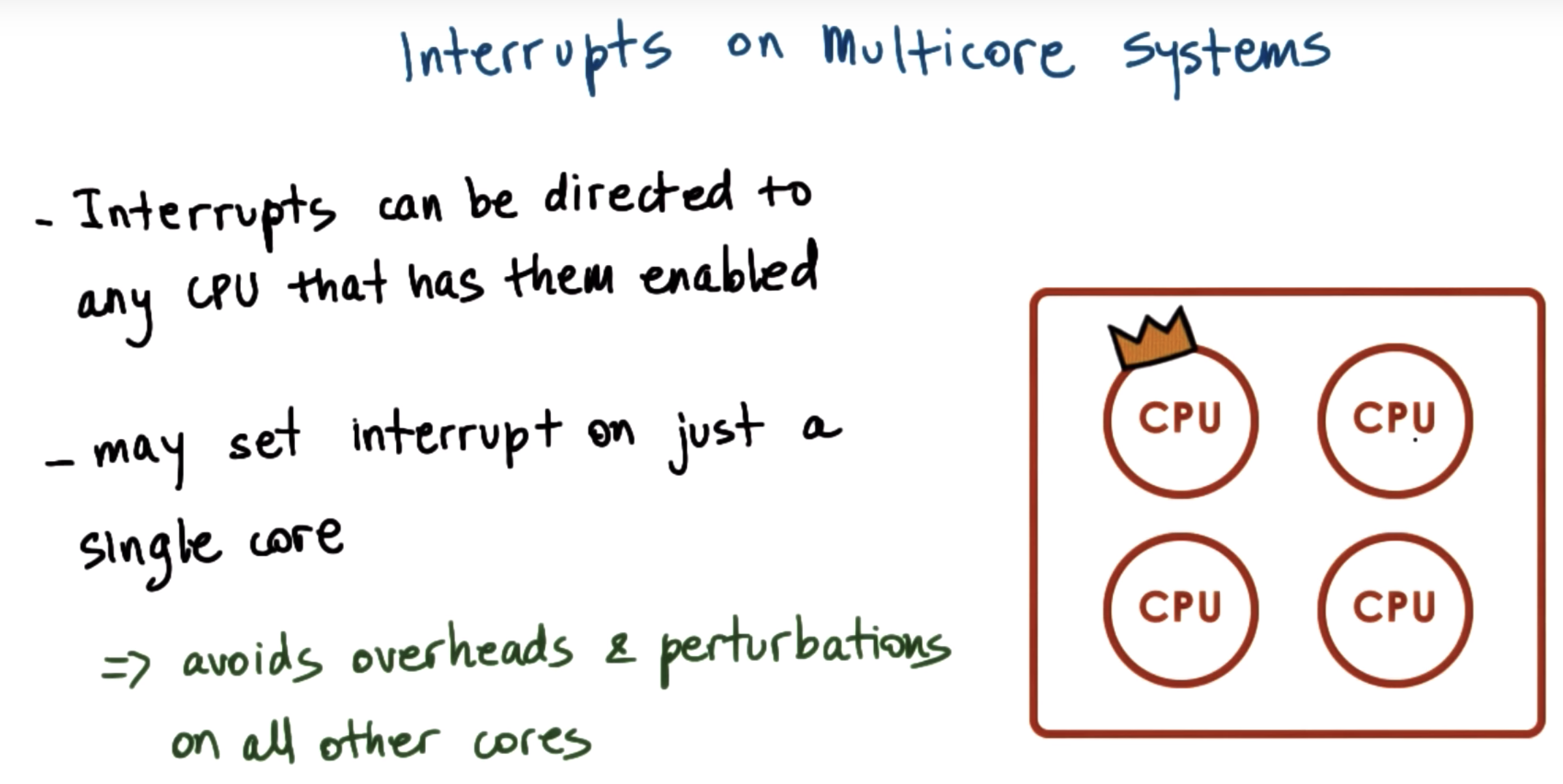


Link
http://pubs.opengroup.org/onlinepubs/9699919799/
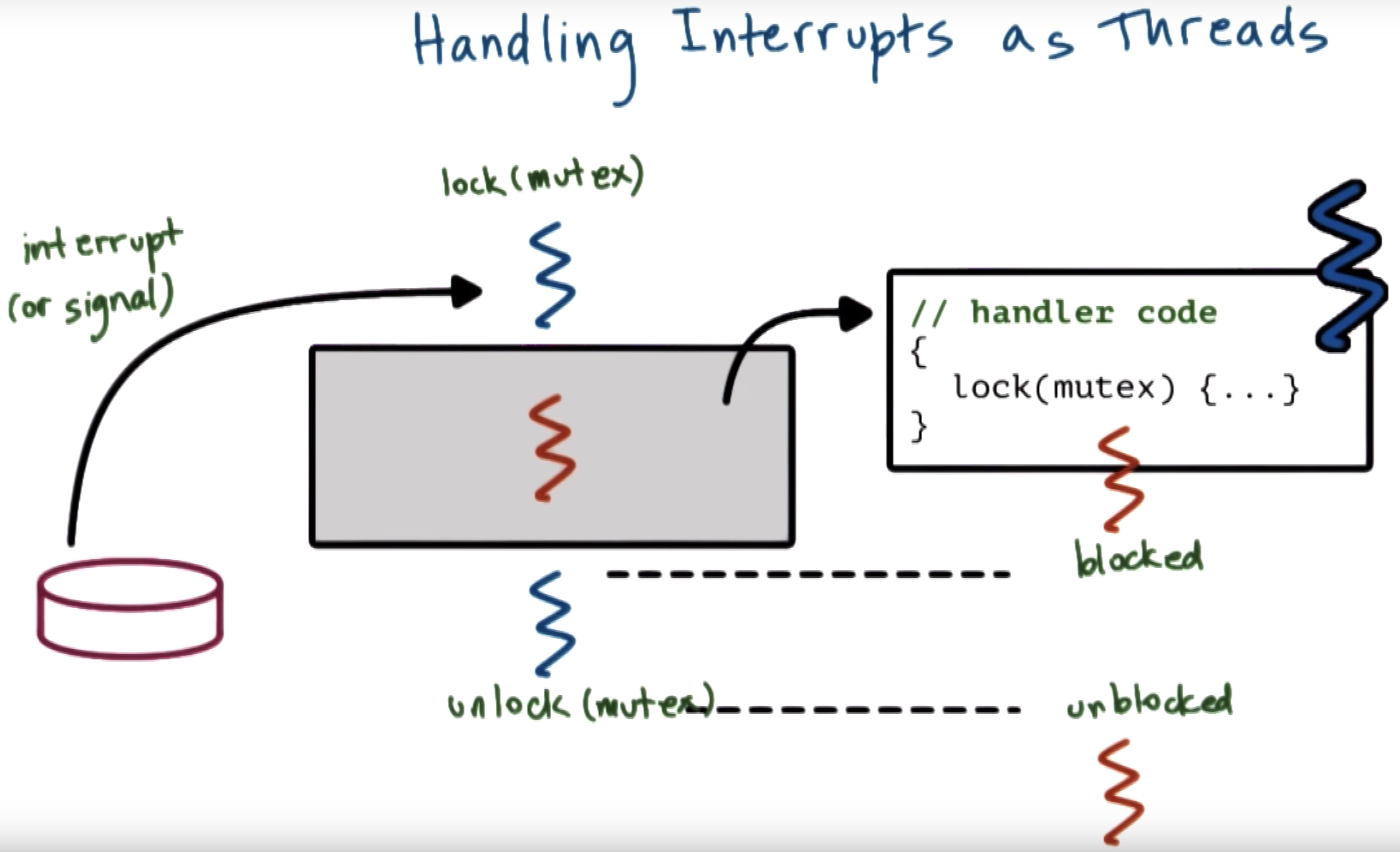
in sunOS, the interrupts become full fledged threads

but there're some concerns
Interrupts: Top vs. Bottom Half
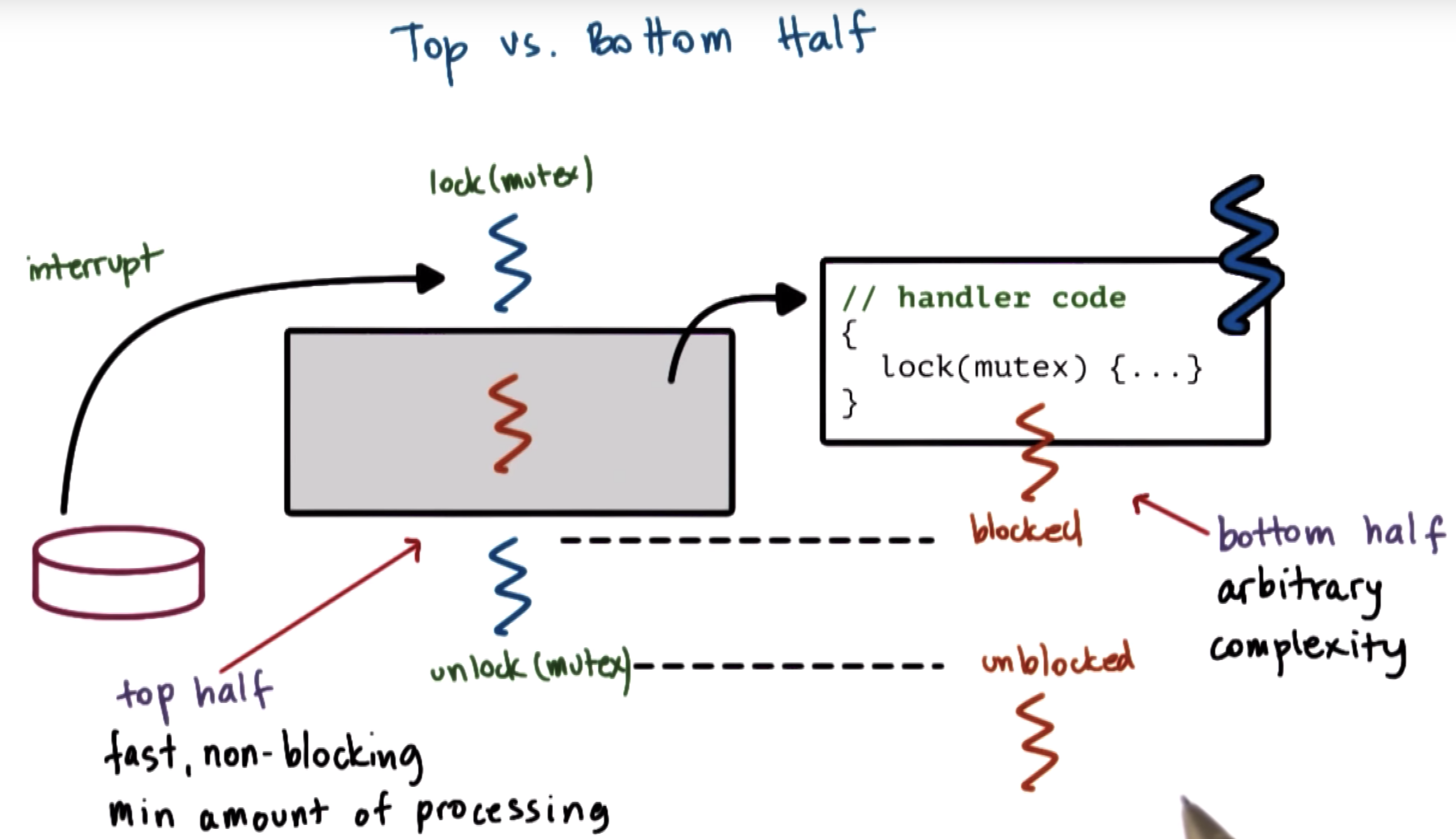
this allows the interrupts to be arbitrarily complex and not to be worried about deadlocks.
top half: executes immediately when an interrupt occurs
bottom half,: like any other thread, can be scheduled for a later time if blocked
Performance of Threads as Interrupts

Threads and Signal Handling
Sun/Solaris Papers
- "Beyond Multiprocessing: Multithreading the Sun OS Kernel" by Eykholt et. al.
- "Implementing Lightweight Threads" by Stein and Shah
Sun/Solaris Figures
Threads and Signal Handling: Case 1
Threads and Signal Handling: Case 2

Threads and Signal Handling: Case 3
Threads and Signal Handling: Case 4

Tasks in Linux
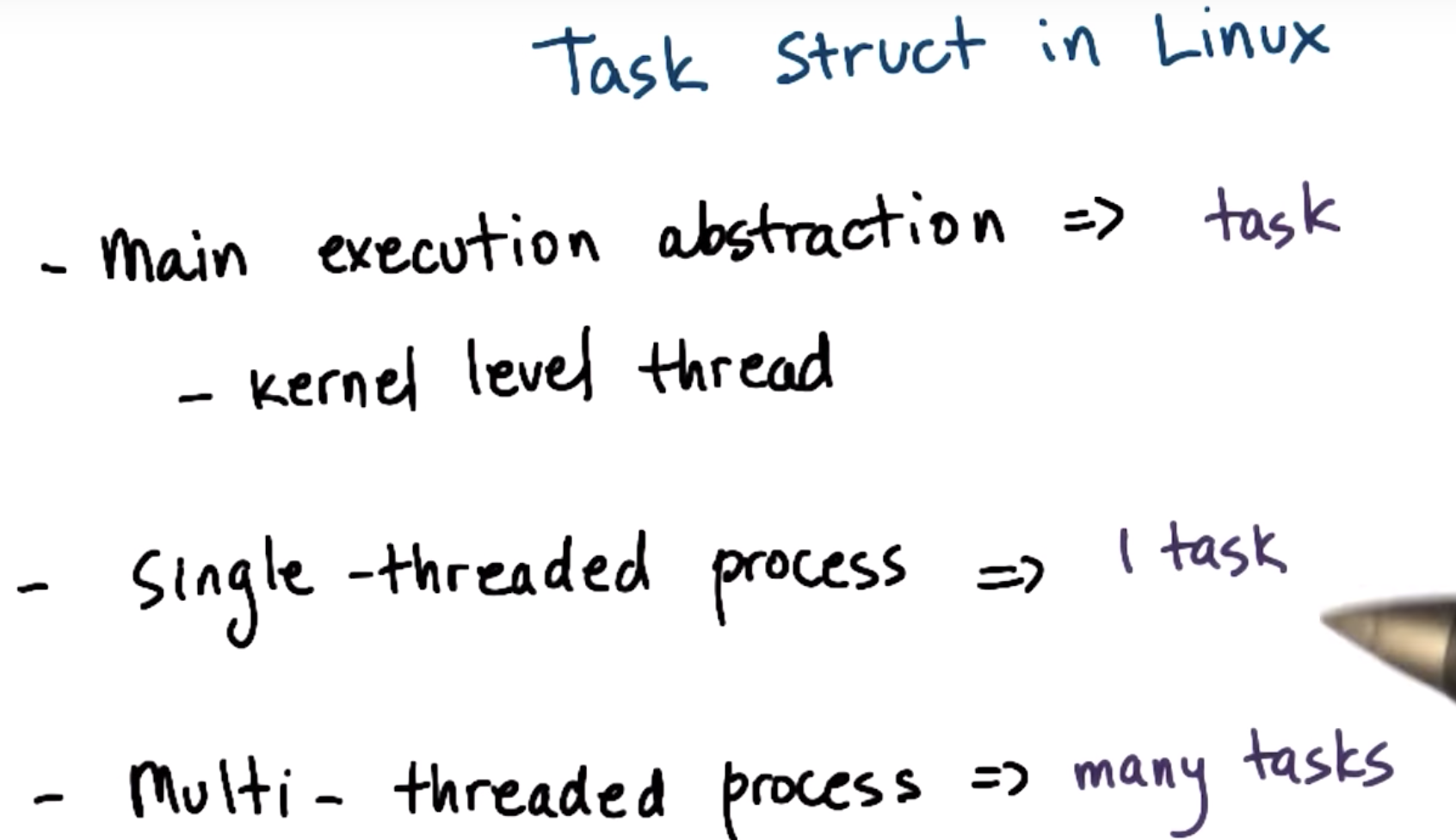

pid is not process id (name is misleading)
pid => task identifier
tgid => task group id


https://stackoverflow.com/questions/3042717/what-is-the-difference-between-a-thread-process-task