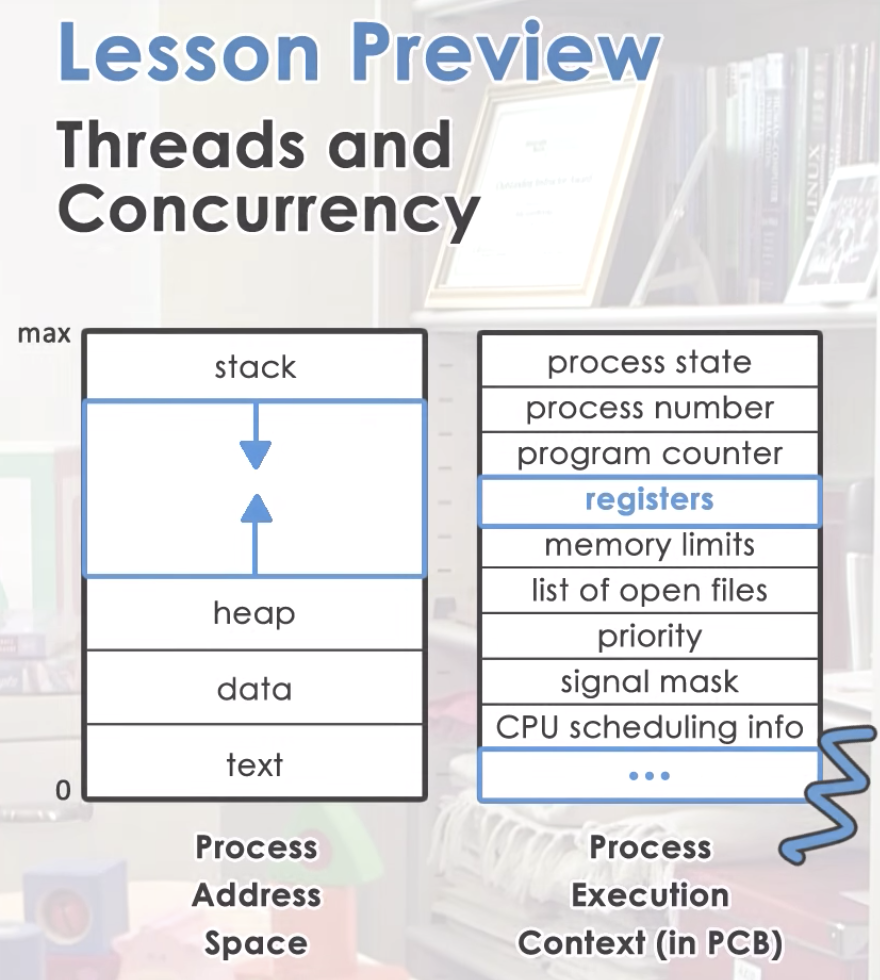
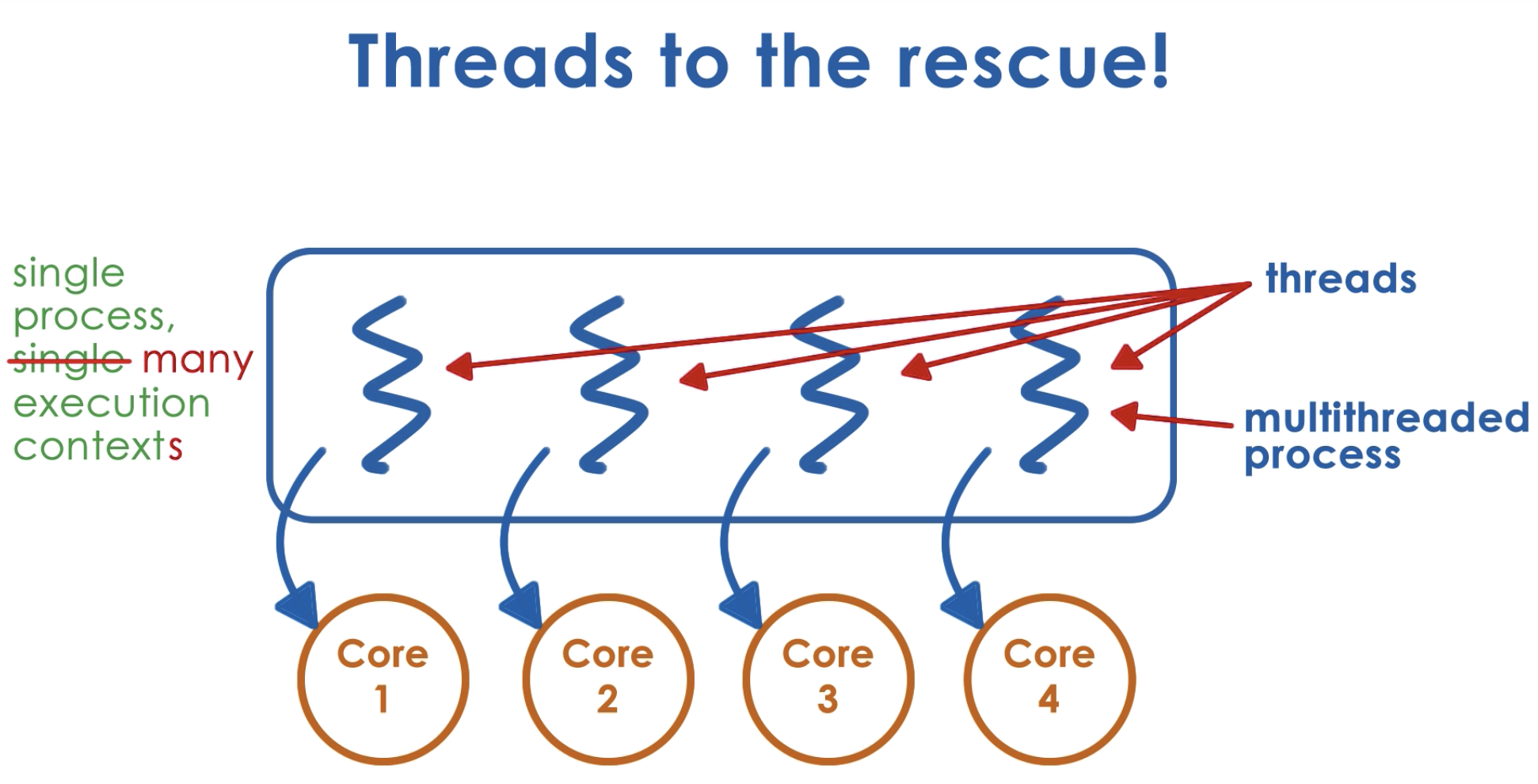
to take the full advantage of the capability of multi-core system, that process has to have multiple execution contexts.
We call such execution context within a single process, threads.


In a later lesson, we'll talk about a concrete multithreading system called Pthreads.
Here's a paper that would be used in this Lecture.
"An Introduction to Programming with Threads" by Birrell

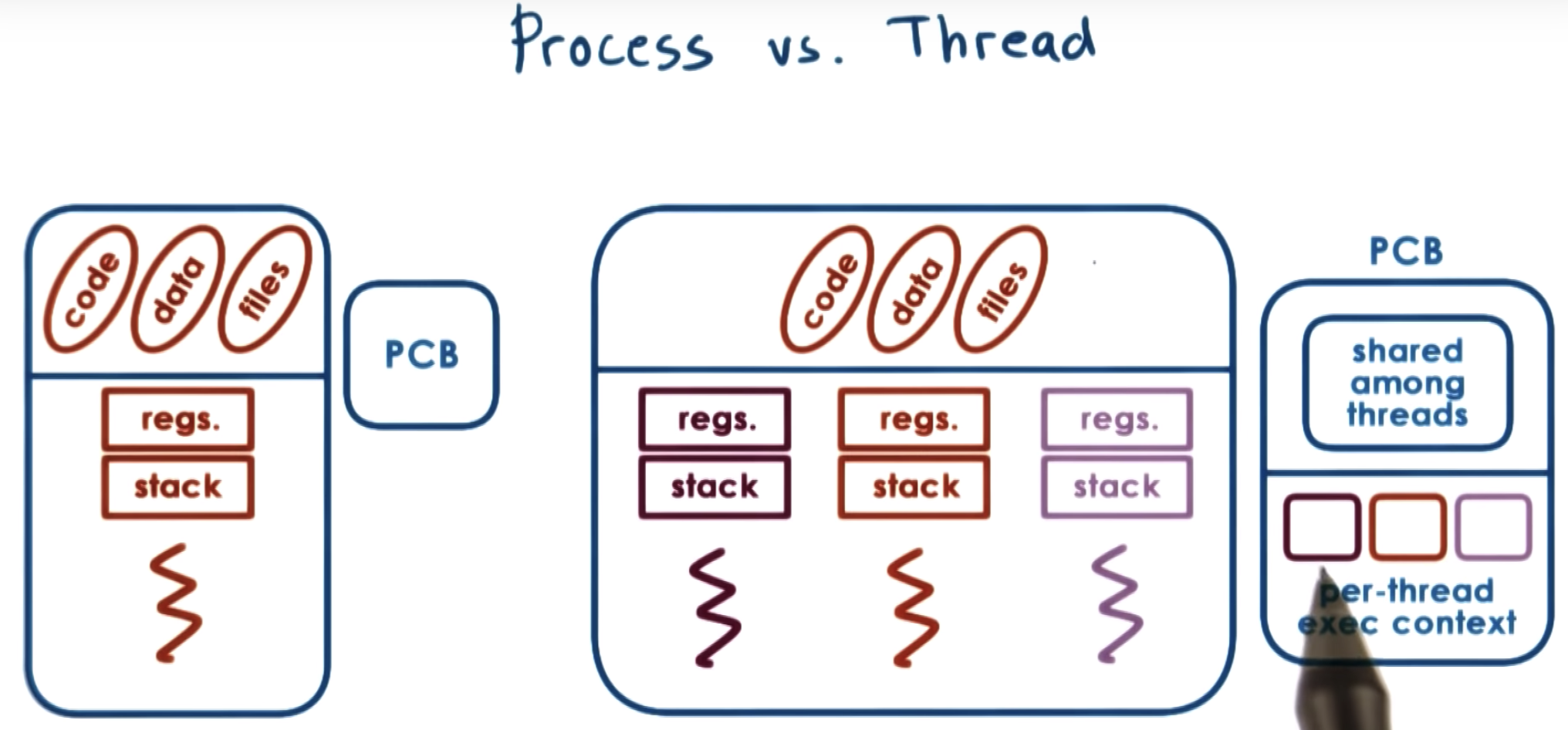
Although the threads execute the exact same code, they're not necessarily executing the exact same instruction at a single point in time.
So every single one of them will still need to have its own private copy of the stack, registers, program counters, et cetera.
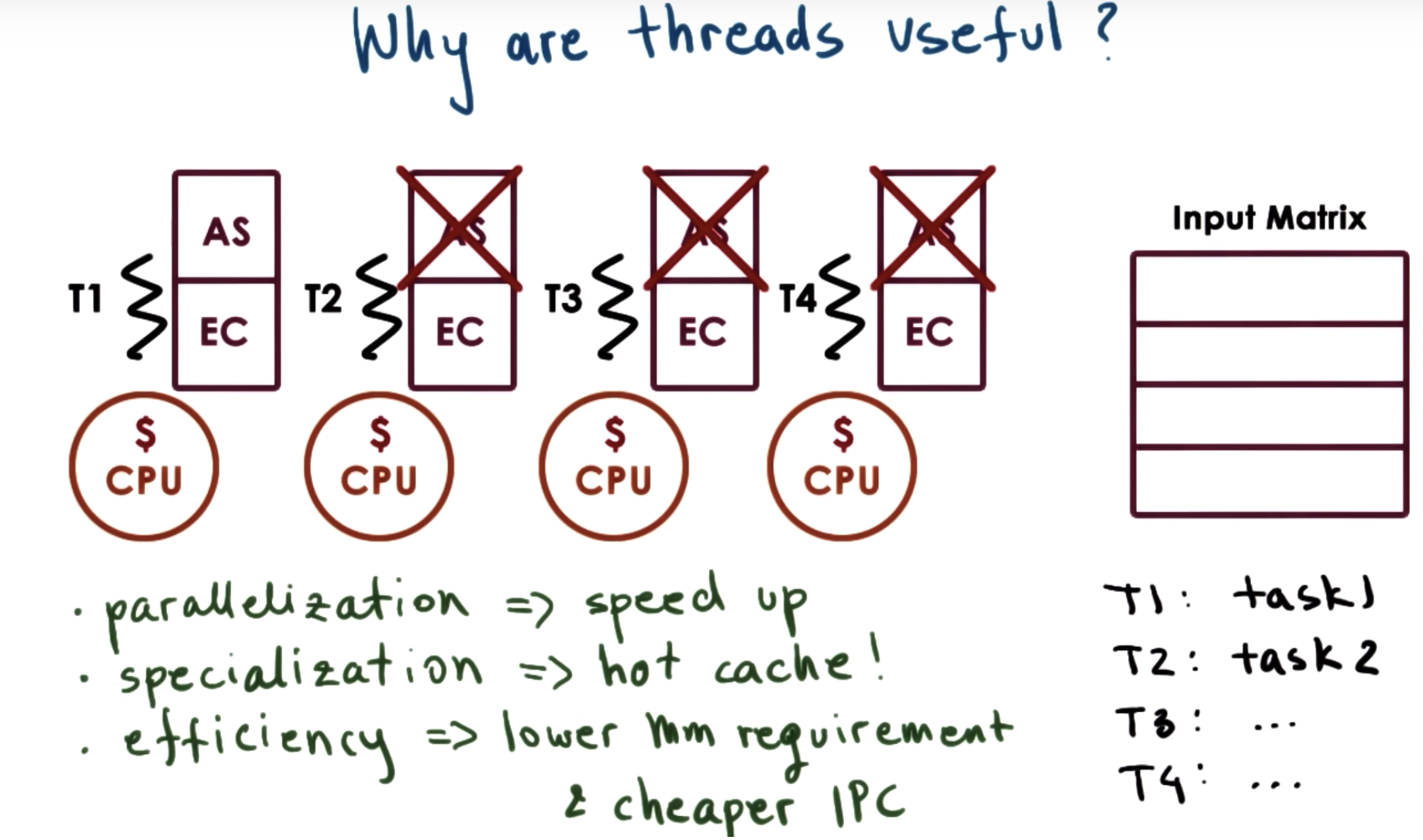
threads may execute completely different portions of the program.
eg. one thread for IO, and another for display rendering
(different threads for different functions)
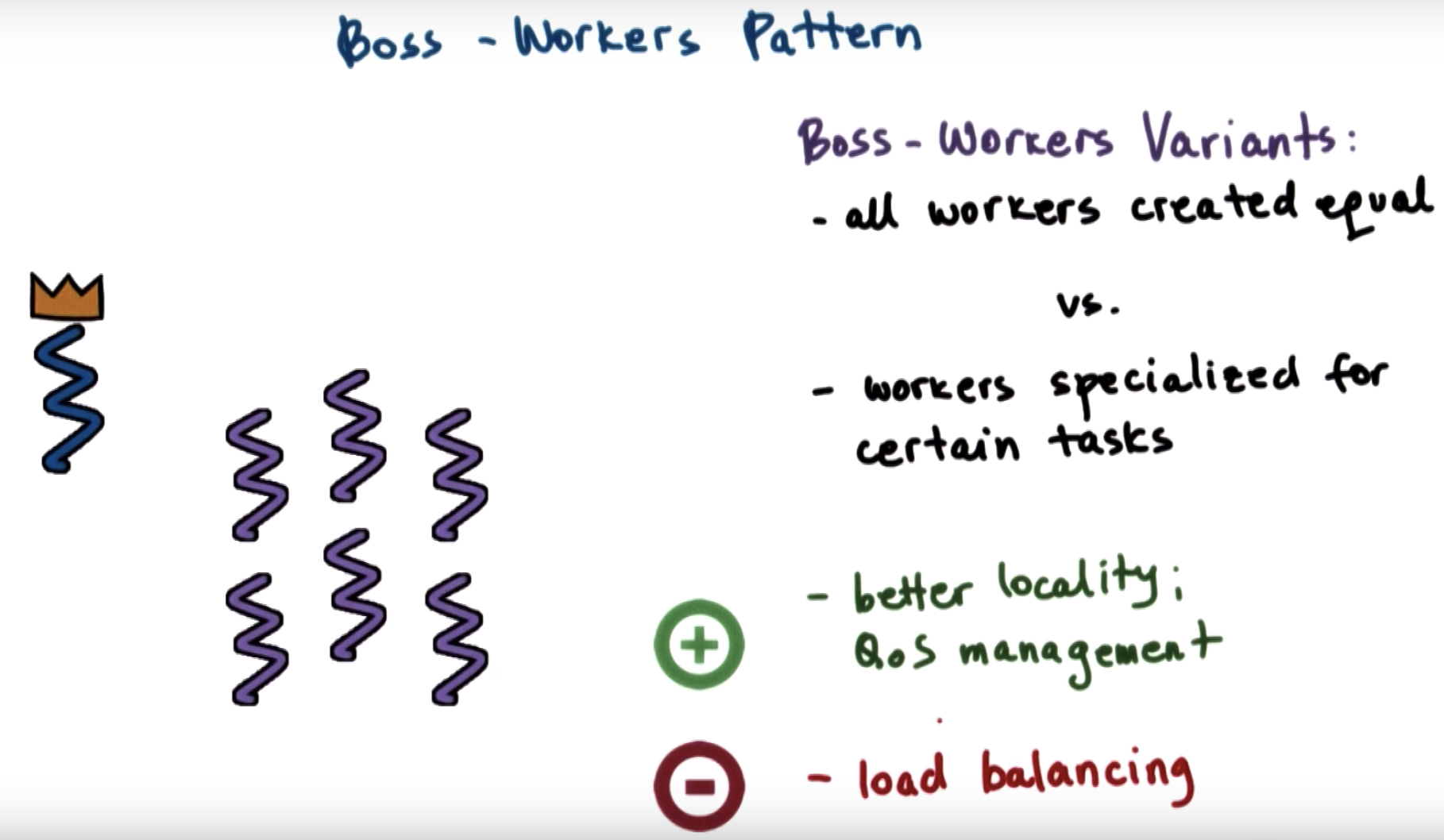
by specilization, we can differentiate how we manage those threads.
eg. give higher priority to more important threads
another benefit is having a hotter cache
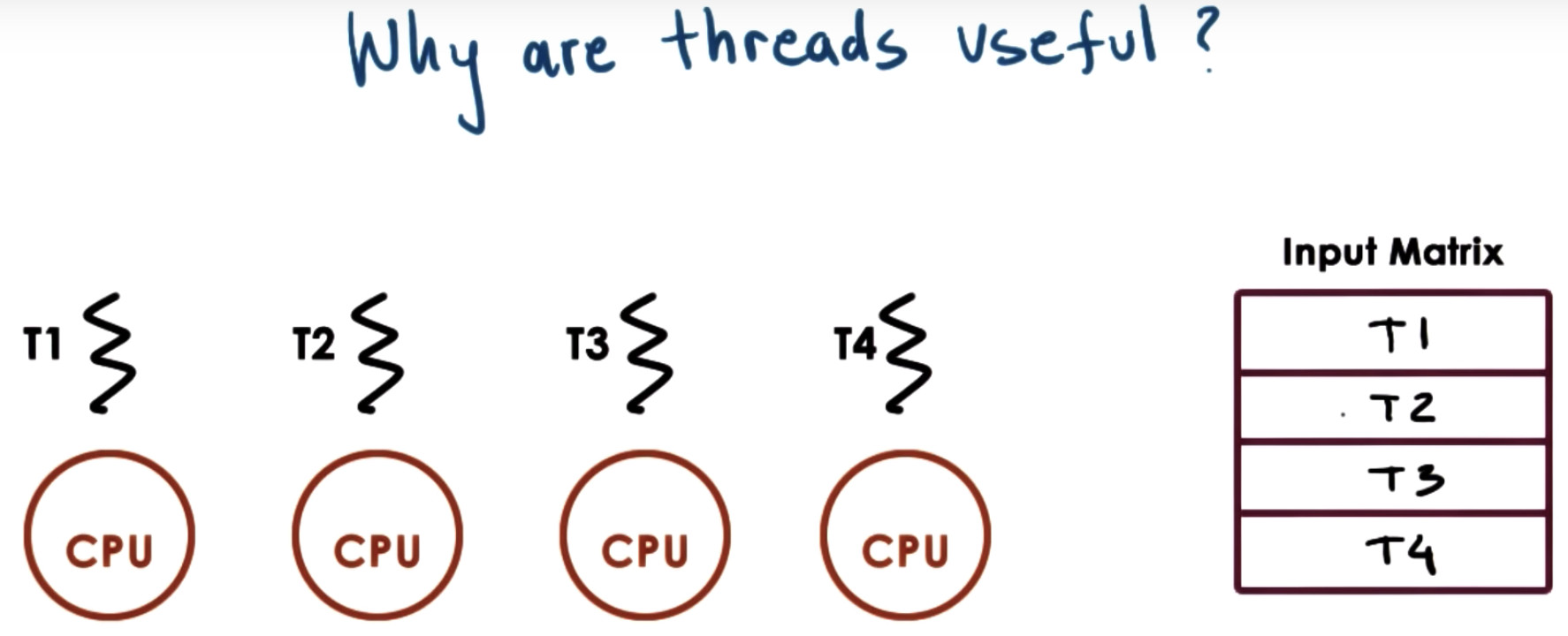
Why not running 4 processes? What's the advangtage of multi-thread versus multi-process?
(1 ) Processes do not share an address space, so we have to allocate 4 address spaces (AS) and execution contexts (EC). Multi-thread is more memory-efficient.
As a result, the multi-thread application is more likely to fit in memory and not required as may swaps from disk.
(2) Another issus is the communicating data. Interprocess commnunication (IPC) and synchronization are more costly.
Interthread commnunication and synchronization are performed via shared variables in that same process address space.

If an idle time (eg. waiting for the IO response) is sufficiently longer than the time it takes to make a contex switch,
then it starts making sense to context switch from thread one to some other thread T2.
This can apply to both multi-thread and multi-process.
But creating the new virtual to physical address mappings for new processes is the most costly step in context switch.
Multi-thread cases avoid this recreation of mappings. This is useful even in a single CPU.


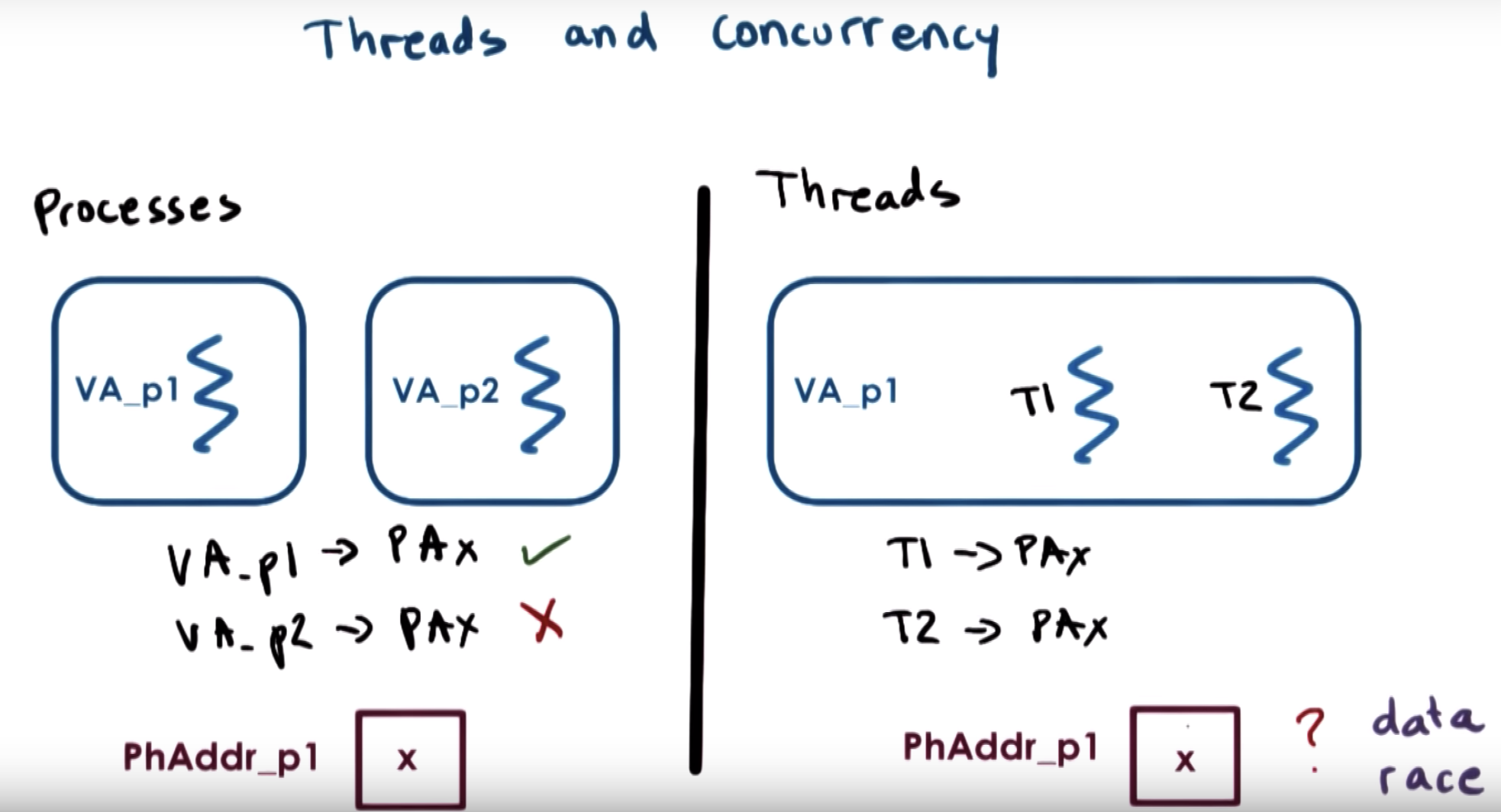
T1 and T2 can both legally perform access to the same physical memory, and using the same virtual address on top of that.
But this introduces some problems, called "data race".
If T1 and T2 are allowed to access the data at the same time and modify it at the same time, then this could end up with some inconsistencies.
Or both threads are trying to update the data at the same time, and their updates sorts of overlap.
=> we need these threads to execute in an exclusive manner, called mutual exclusion.
Ideas from Birrell

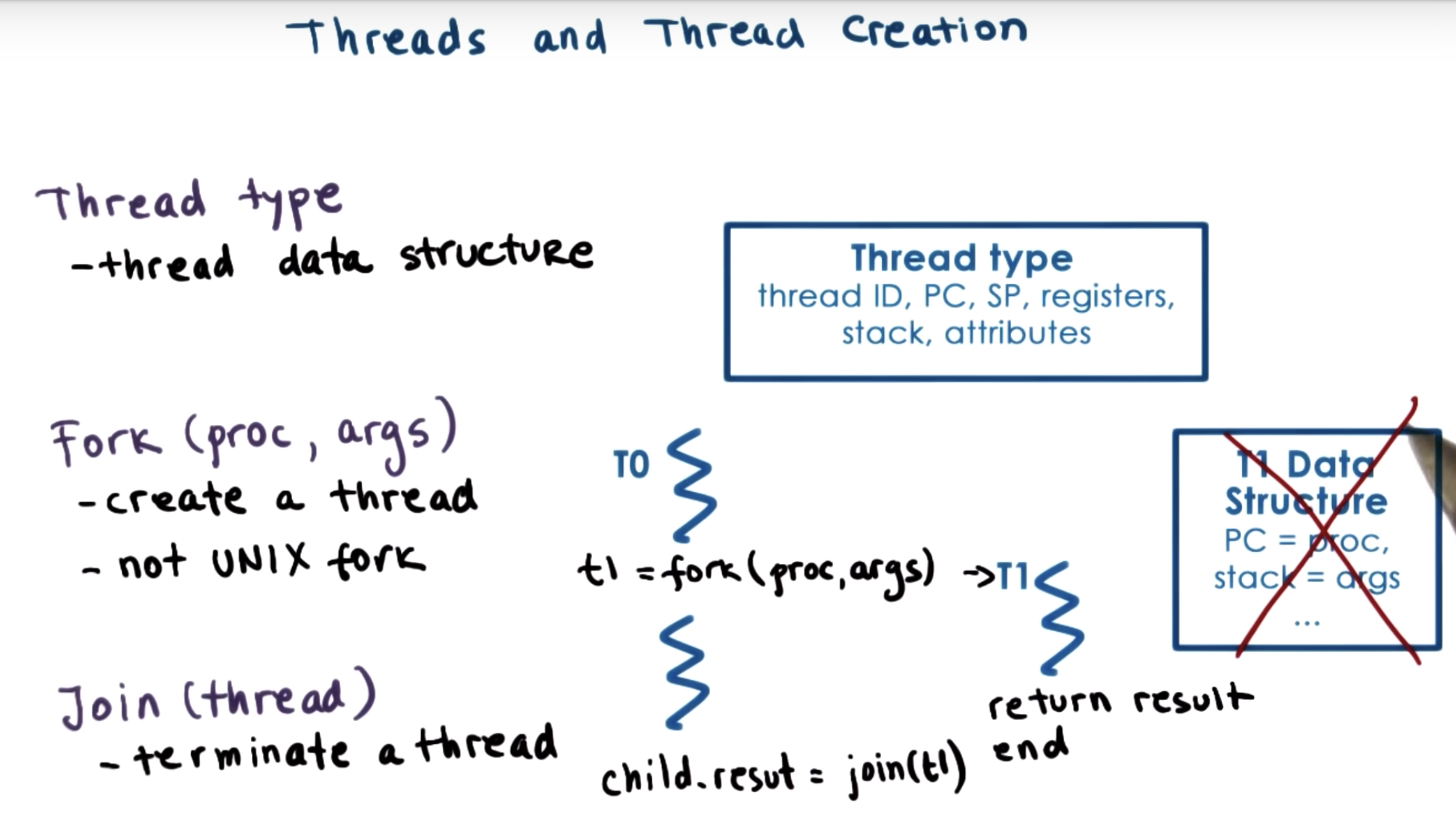
Fork here is not the Unix fork.
Unix fork creates a new process, an exact copy of the calling process.
proc: procedure
Fork here create a new thread that will execute the proc with args
When T1 finishes, it may return some computed results or some status of the computation like success or error.
These results should be stored in some well-defined location in the address space that's accessible to all the threads.
And they have some mechanism to notify either the parent or some other thread that the result is now available.
More generally, we need some mechanism to determine that a thread is done, and to retrieve its result, or at least determine the status of the computation.

if in the last line, the child thread hasn't completed the task, the parent thread will have to wait.
Also, in this case, the results of child processing are available through this shared list. So really the join isn't a necessary part of the code.
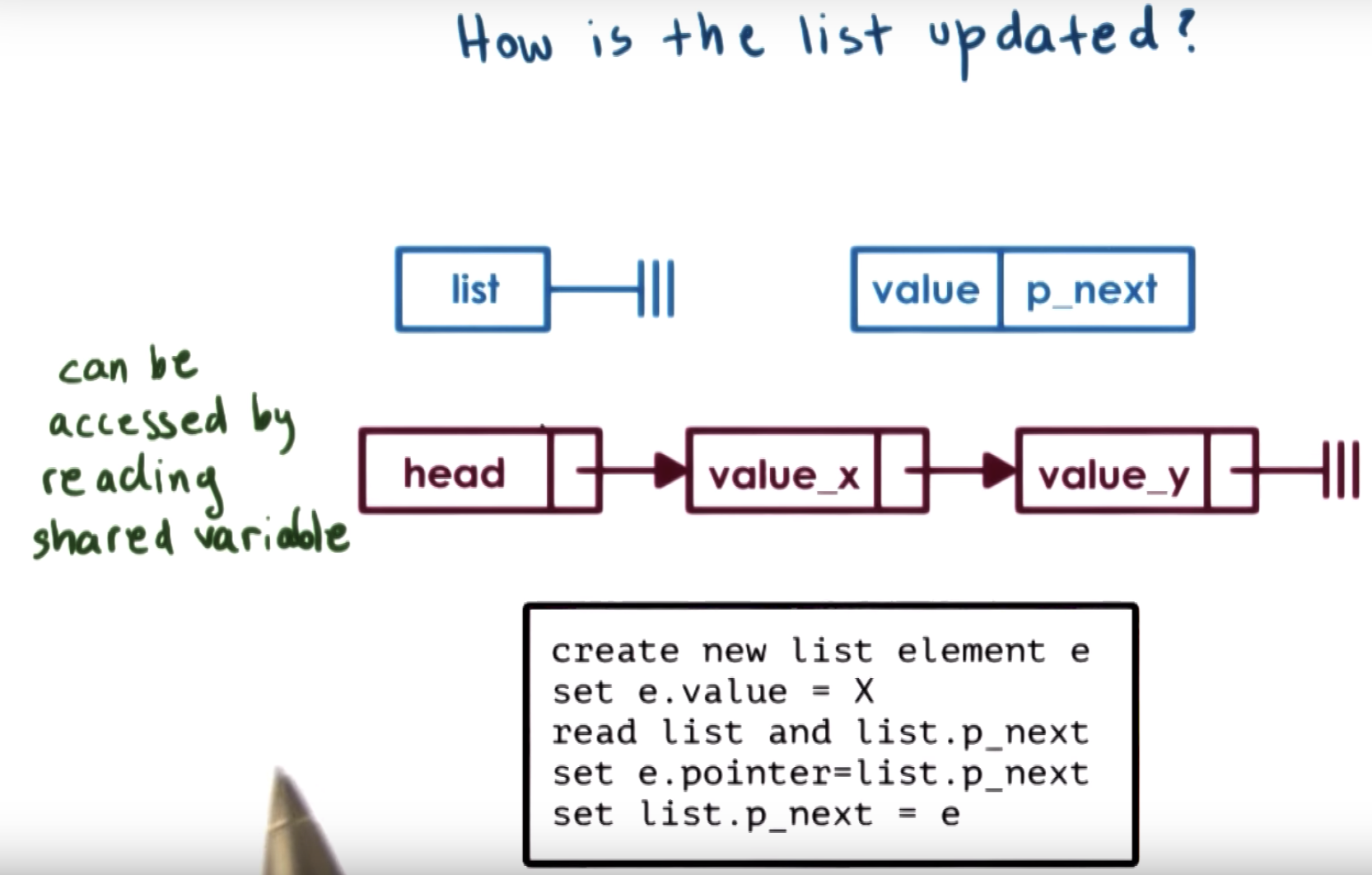
each list element has two fields: value and p_next
I think the correct or the unambiguous version of the code snippet is :
ListElement* e = new ListElement(); e->value = X; e->p_next = list.begin()->p_next; list.begin().begin->p_next = e;
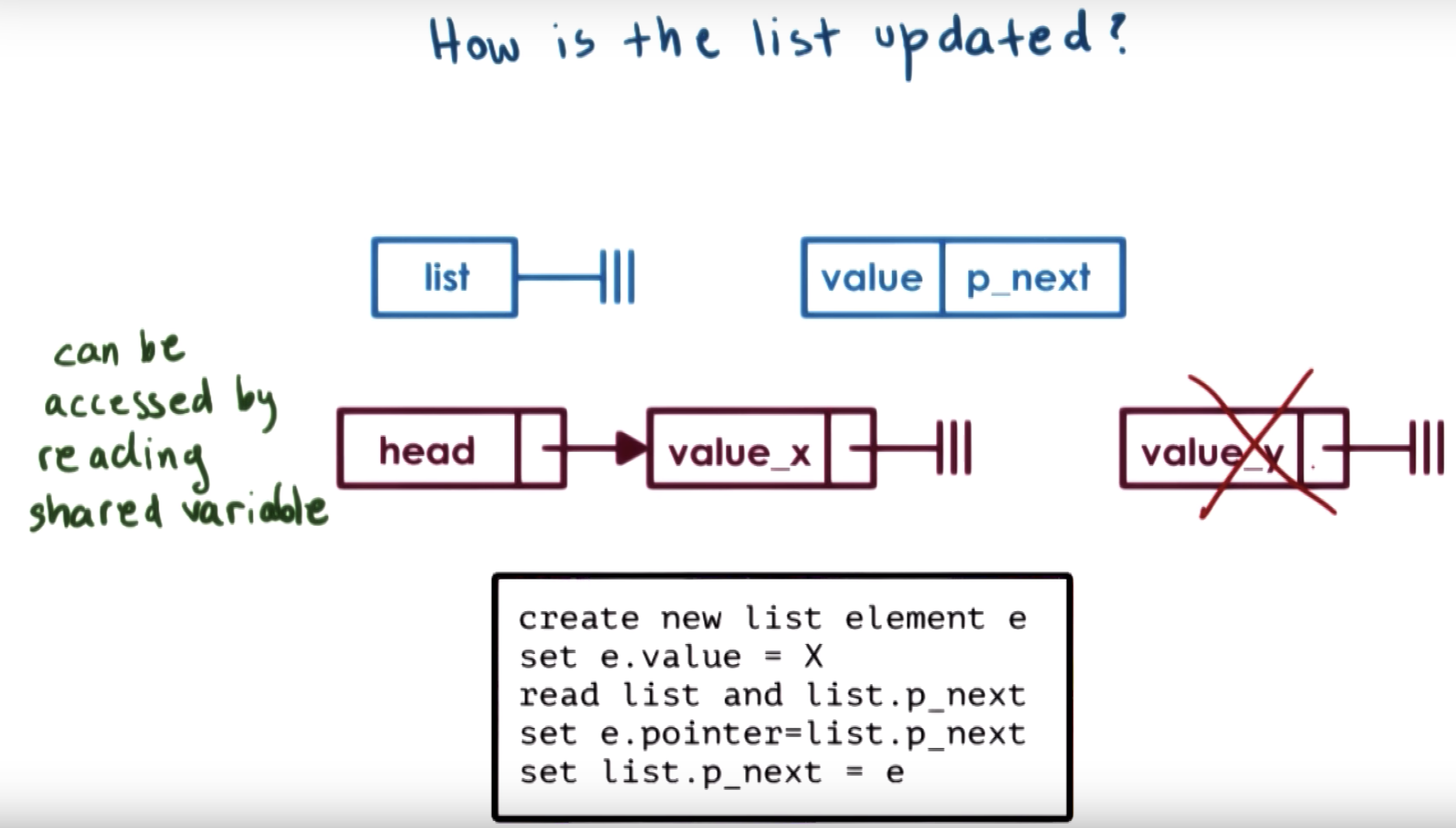
when inconcurrency problems occur, only one new ListElement will be linked to head, whereas the other one will simply be lost.
As a result, there's a need for mutal exclusion mechanism in multi thread concurrency.
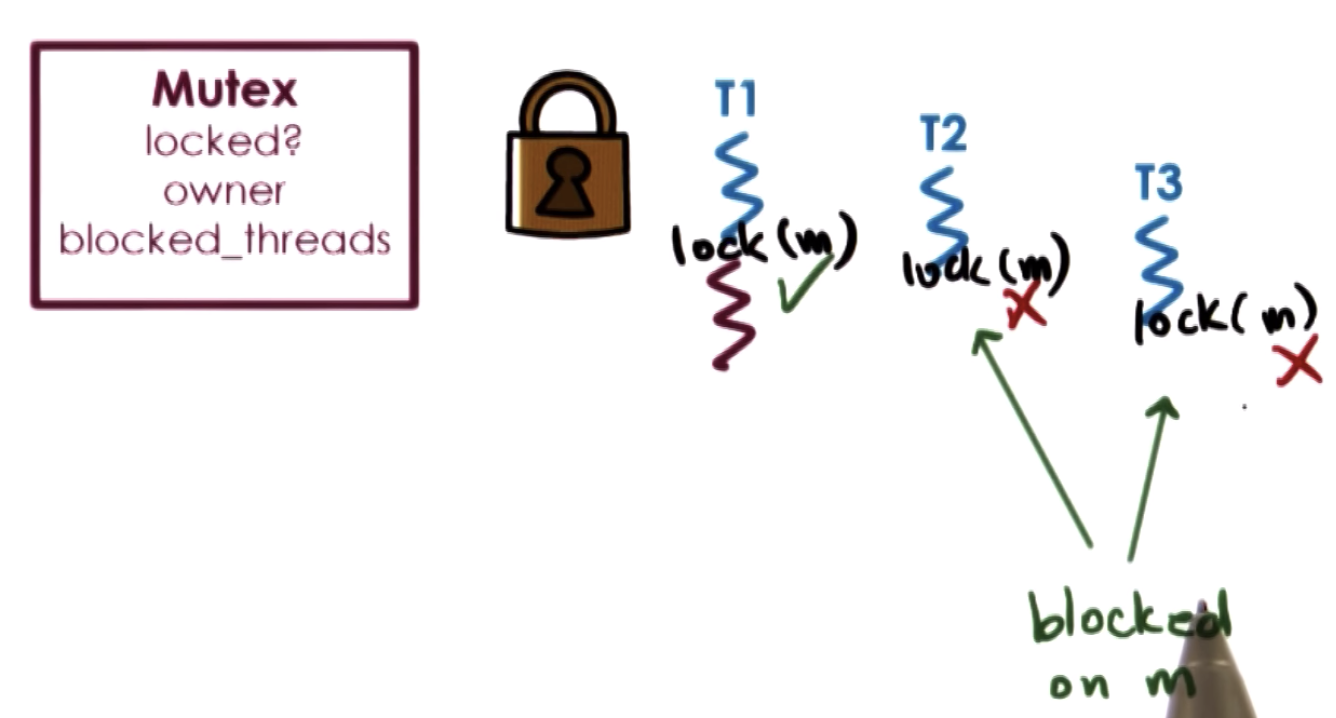
three parts in Mutex:
(1) status: locked or not
(2) owner: who owns the lock
(3) a list of threads waiting for the lock to be released. (may not need to be ordered)

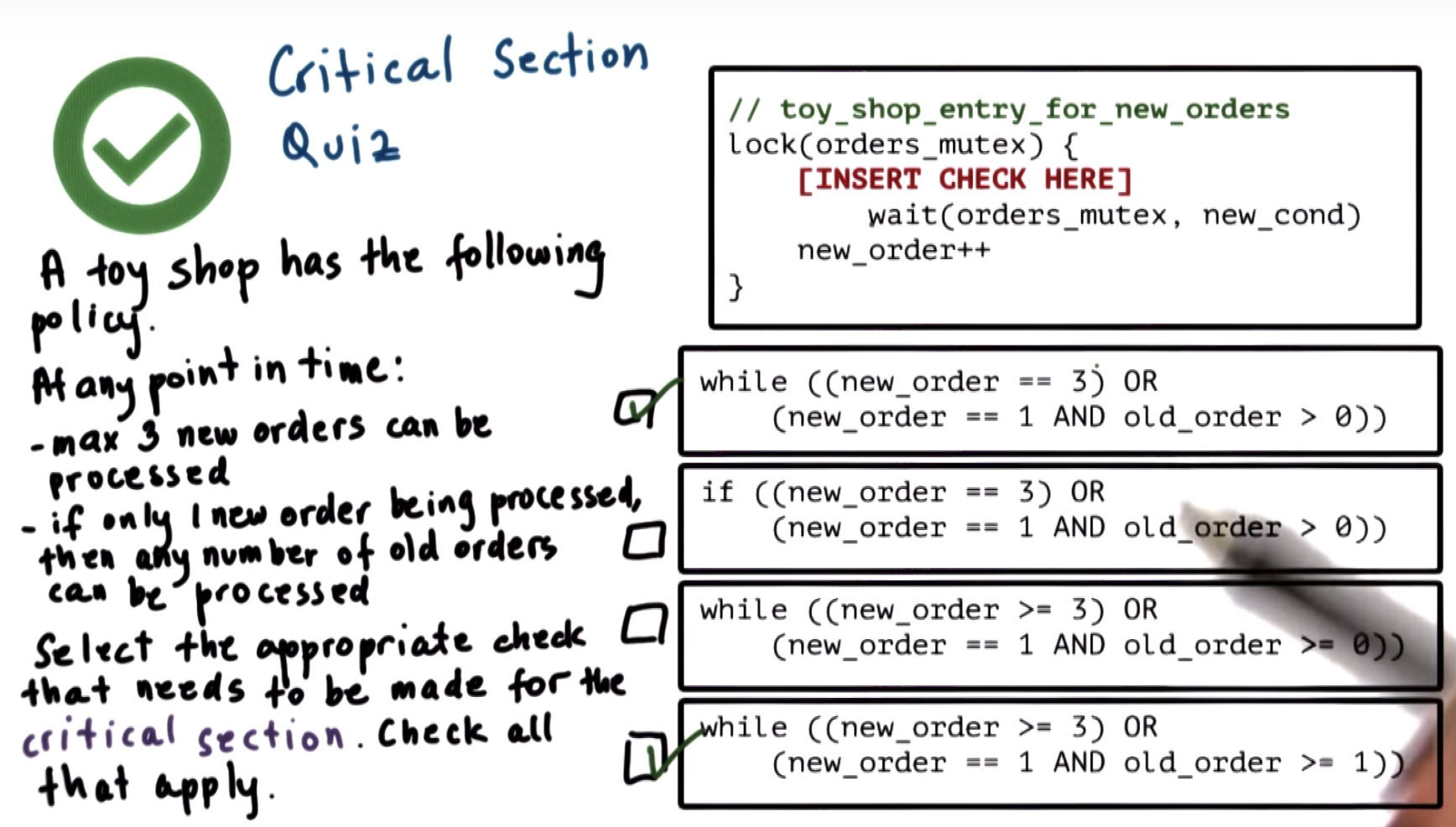
the portion of code be protected by the lock is called the critical section.
eg. update a shared variable, or increment a counter.
any type of operation reuqires mutal execution between threads.
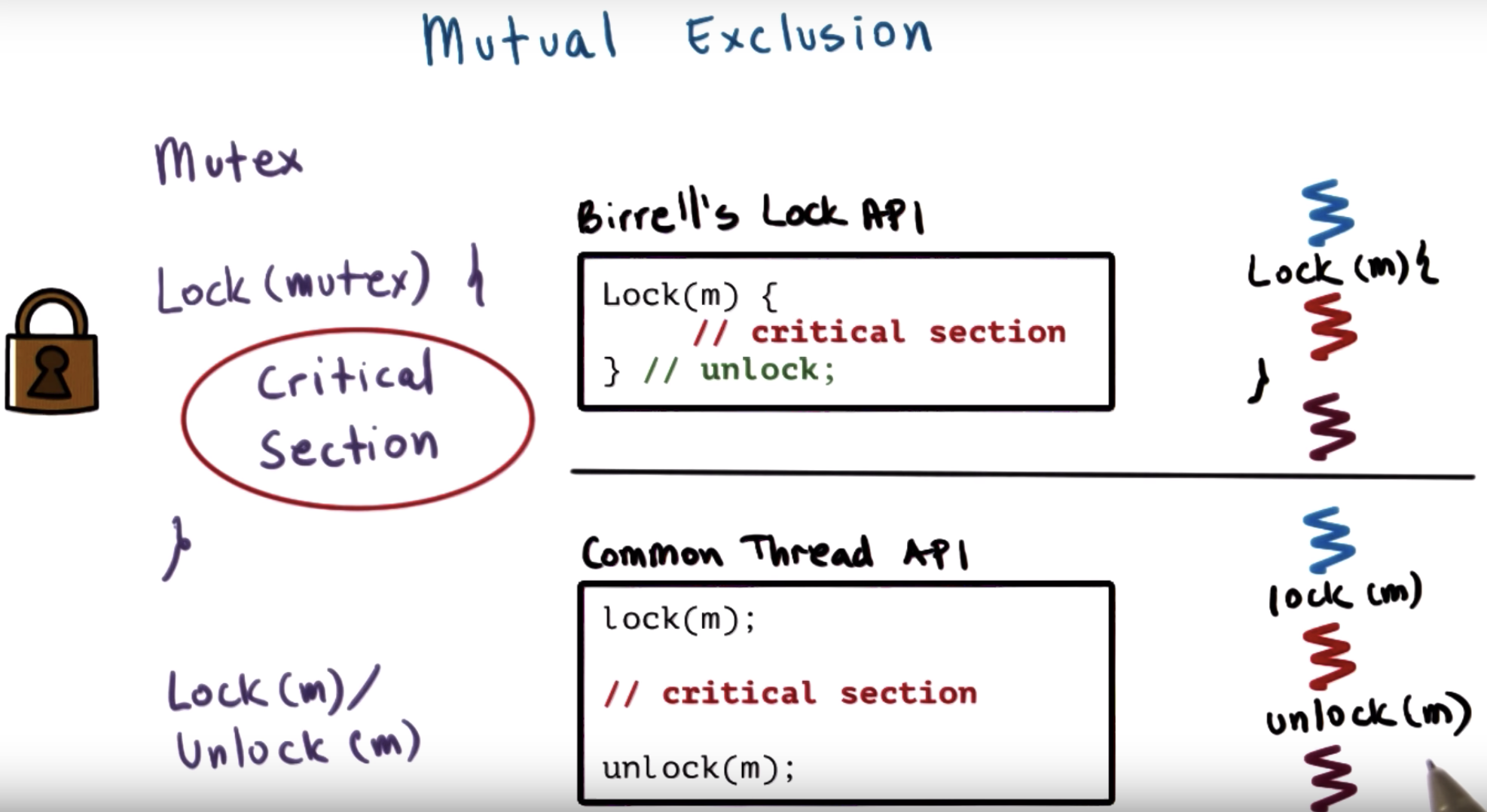
Birrell's lock API automatically unlock after the second curl bracket.
In other common thread API, unlock function should be explicitly written.
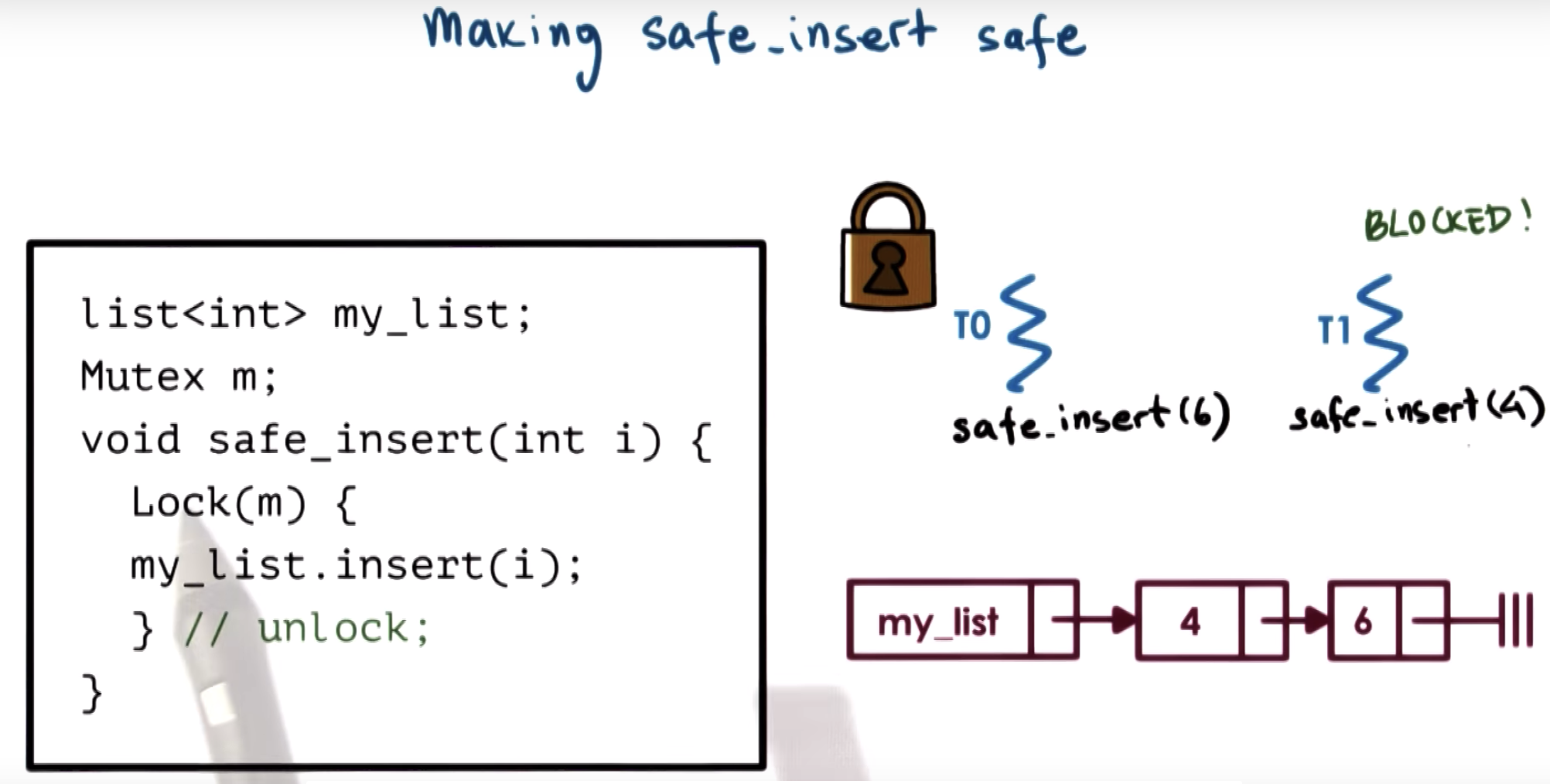

final ordering is {4,6}
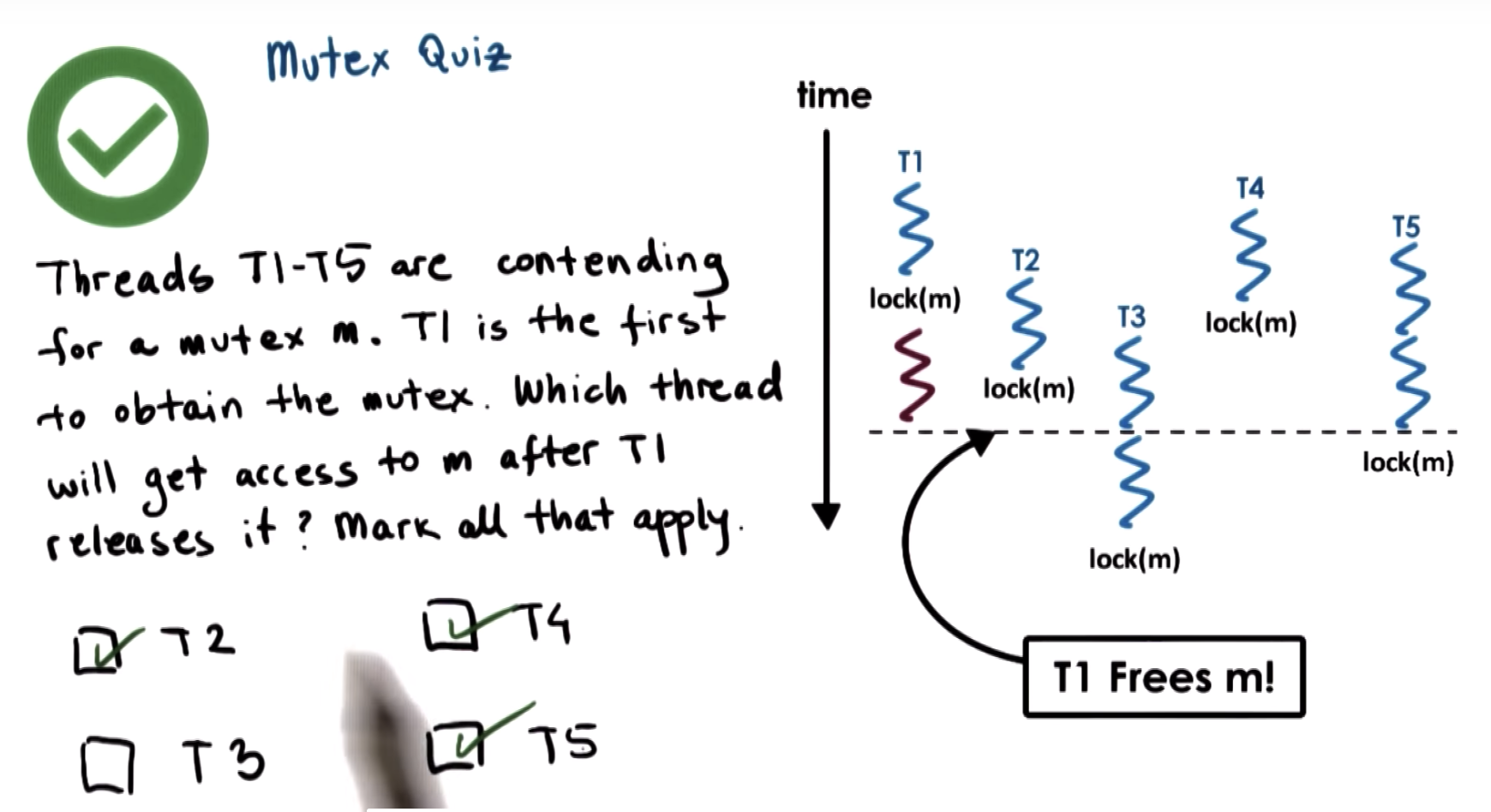
The specification of mutex doesn't make any guarantees regarding the ordering of lock operations.
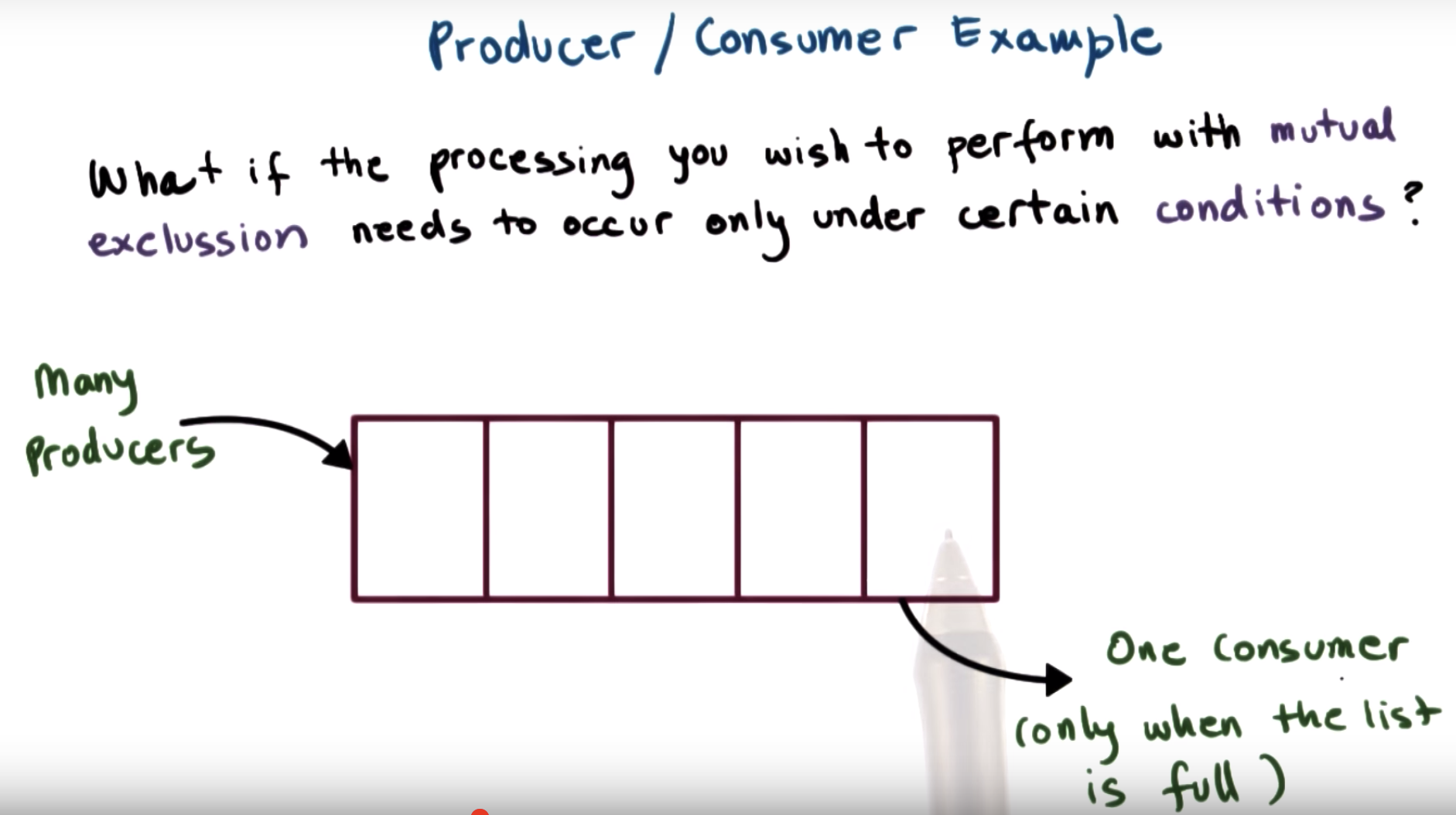
finished the concurrency, what about the conditional variable.
for example: the special consumer
@0:30 "mutual exclussion" should be mutual exclusion

here the condition variable is "list_full"



we need the "while" in order to deal with situations where there are multiple of these consumer threads, waiting on the same condition.
my understanding:

the waiting queue corresponds to the condition variable.
小结:
mutex保证每个block执行独立,保护并发不冲突。
wait的目的是实现异步通信(经过全局变量的控制之后),同步通信效率可能反复循环浪费资源。
wait的结束用signal和broadcast来实现,但同时用全局变量来加速
signal和broadcast是用于异步通信的触发
conditional variables是signal和wait之间通信的变量
全局变量记录通过wait gate的情况(因此保护并发不出现错误)。
here we produce a proxy resource, a helper variable or a helper expression.
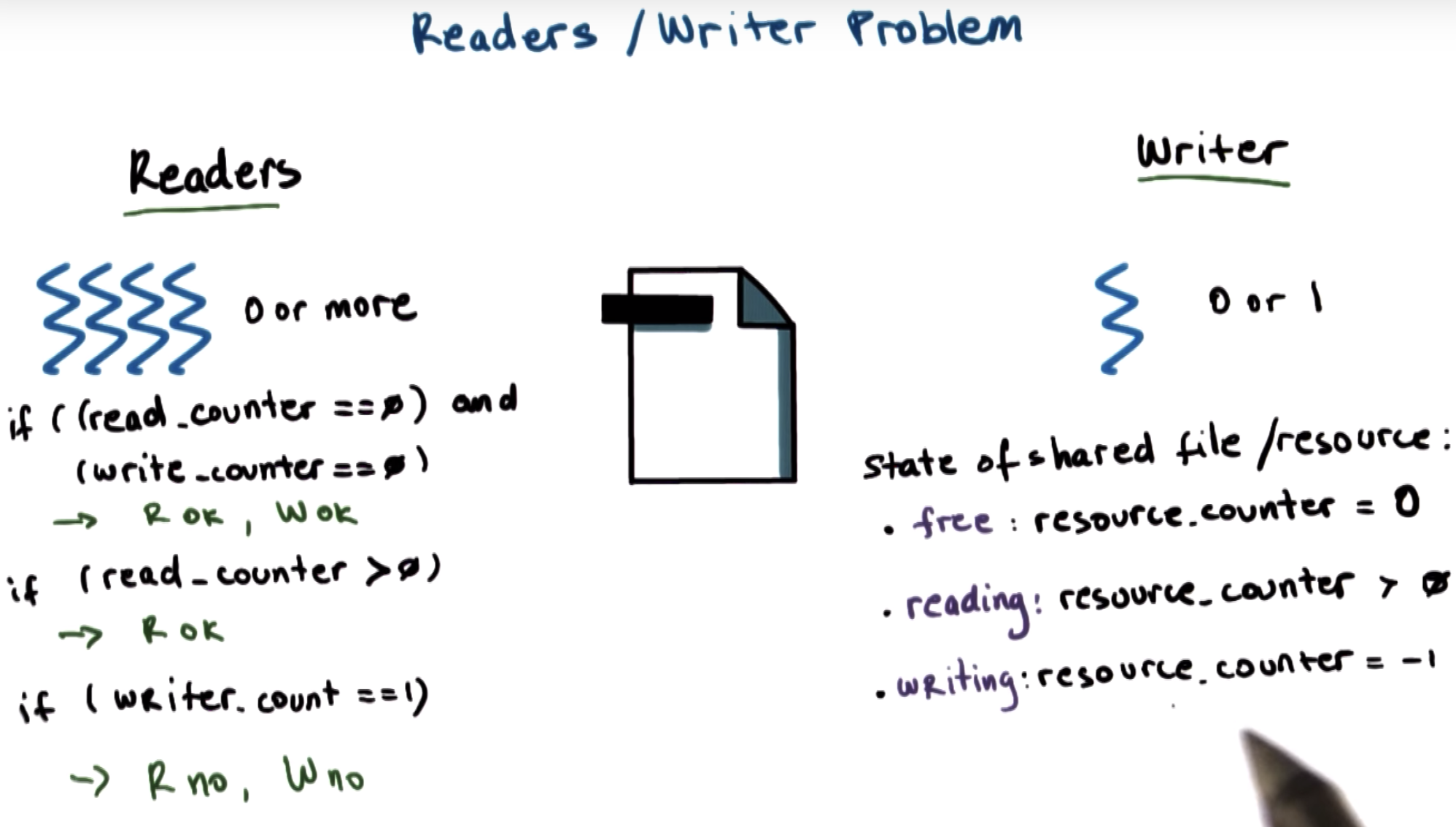



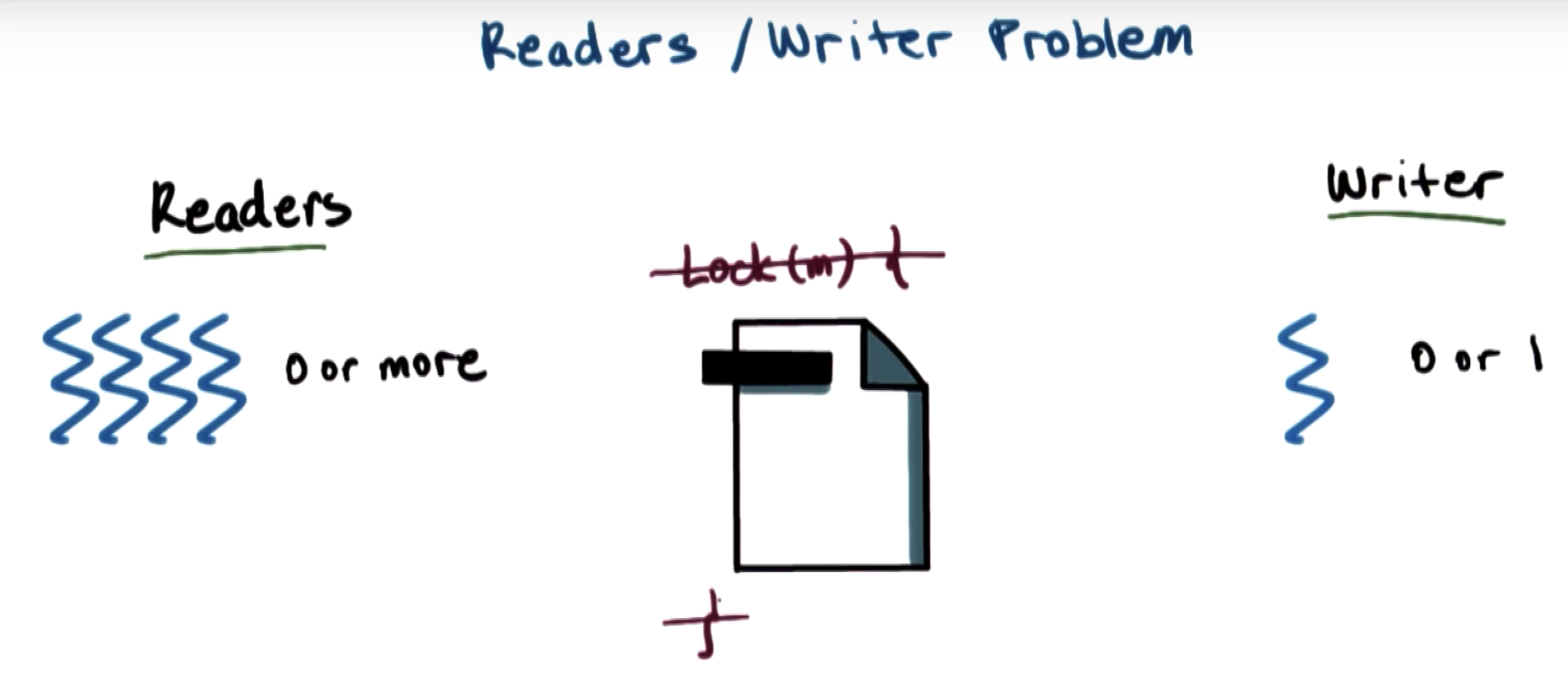
for the reader and writer example, we have these common building blocks.



???threads waiting in queue may wait for an extremely long time, which is a dead lock???
??

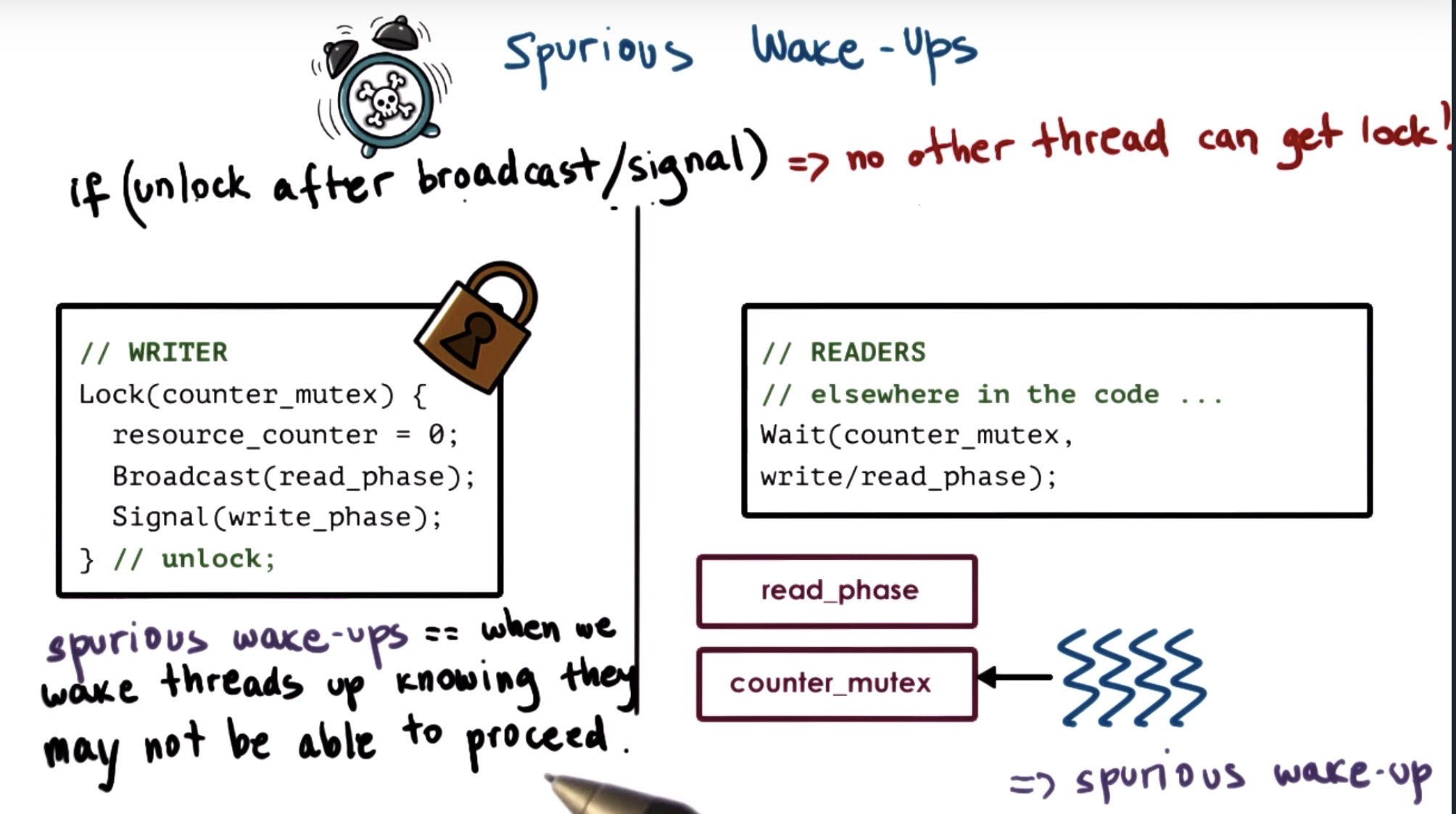
broadcast read_phase to readers, but the readers need to wait for counter_mutex to be unlocked. (second last line of "wait")
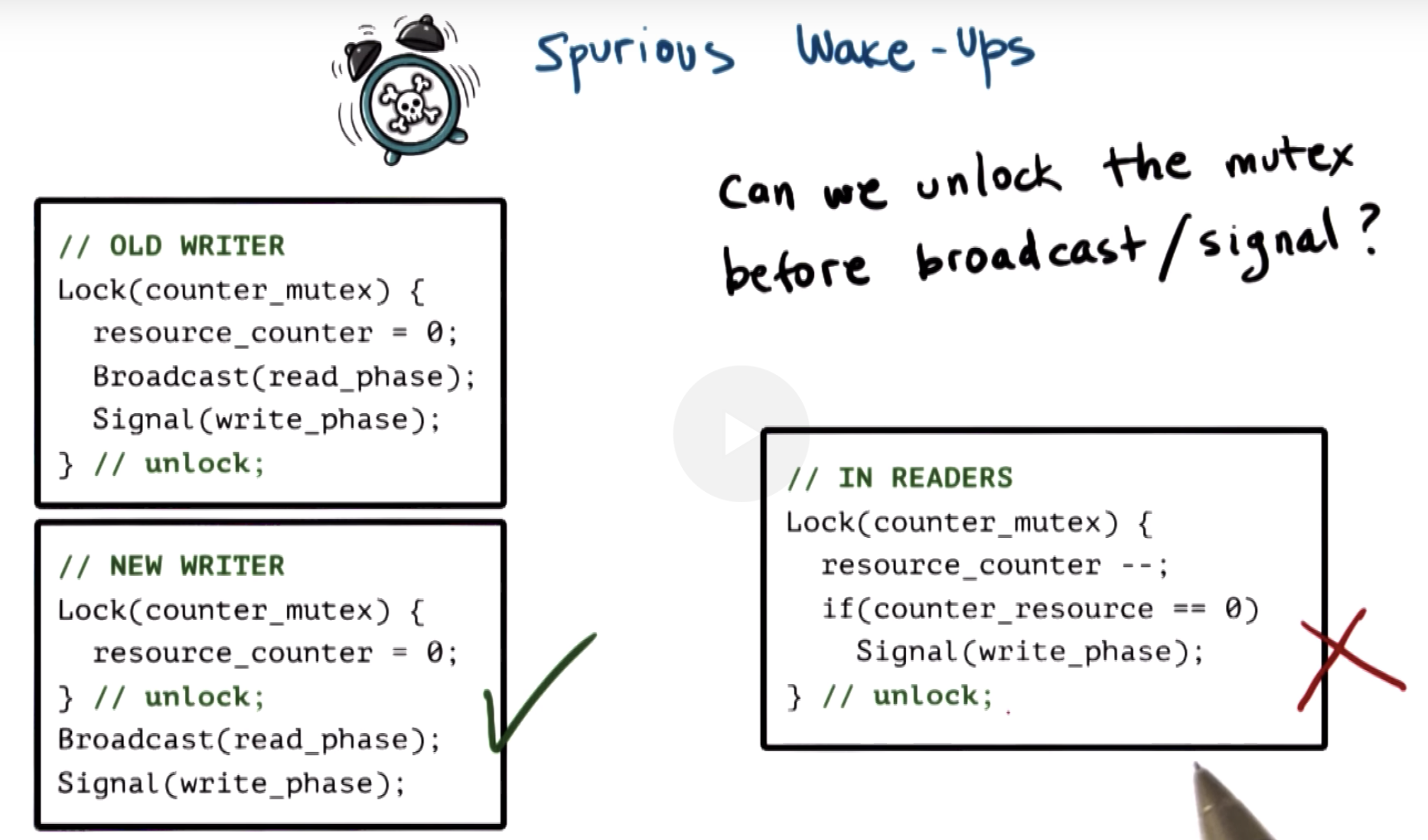
counter_resource is a variable protected by counter_mutex,
in this case, it's wrong to apply similar technique like the writer.

Both A and B wants to use tool1 and tool2, and sometimes each one of them gets one tool...
three kinds of solutions for the dead lock:
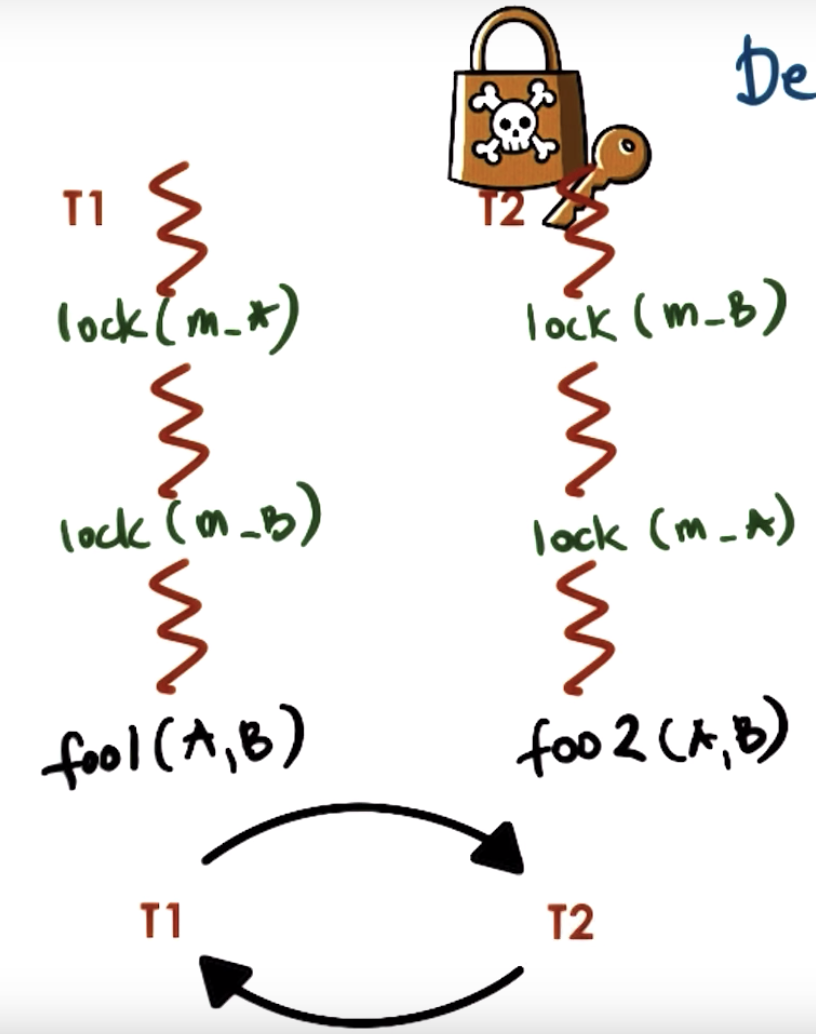




Deadlock prevention is to pre-detect if there's any cycle in the lock graph.
it really hard to guarantee that codes from different sources put mutex in the right order.
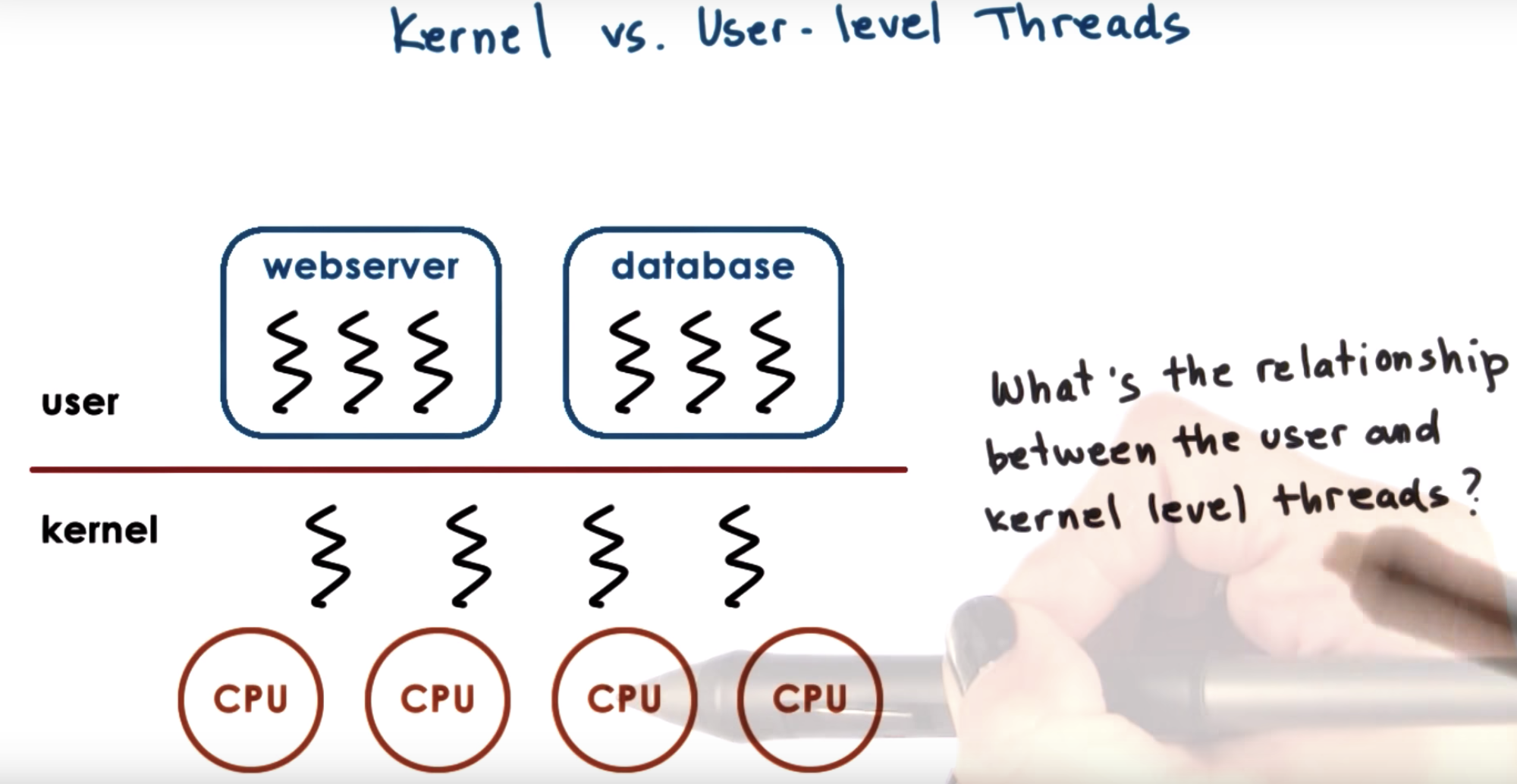
for a user-level thread to actually execute,
(1) it must be associateed with a kernel level thread.
(2) And then, the OS level scheduler must schedule that kernel level thread onto a CPU.
There're several relationships between user-level thread and kernel-level thread:
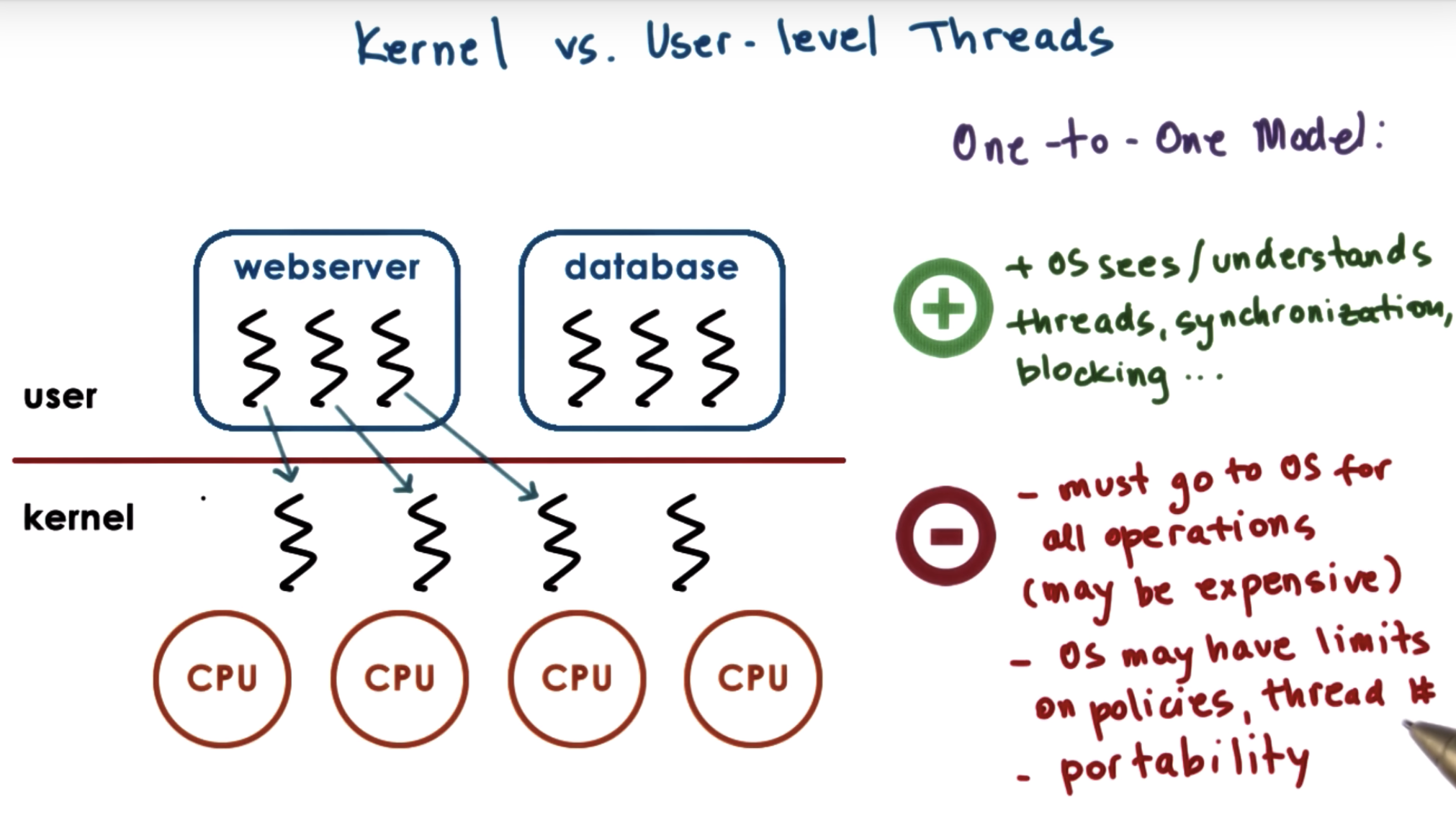
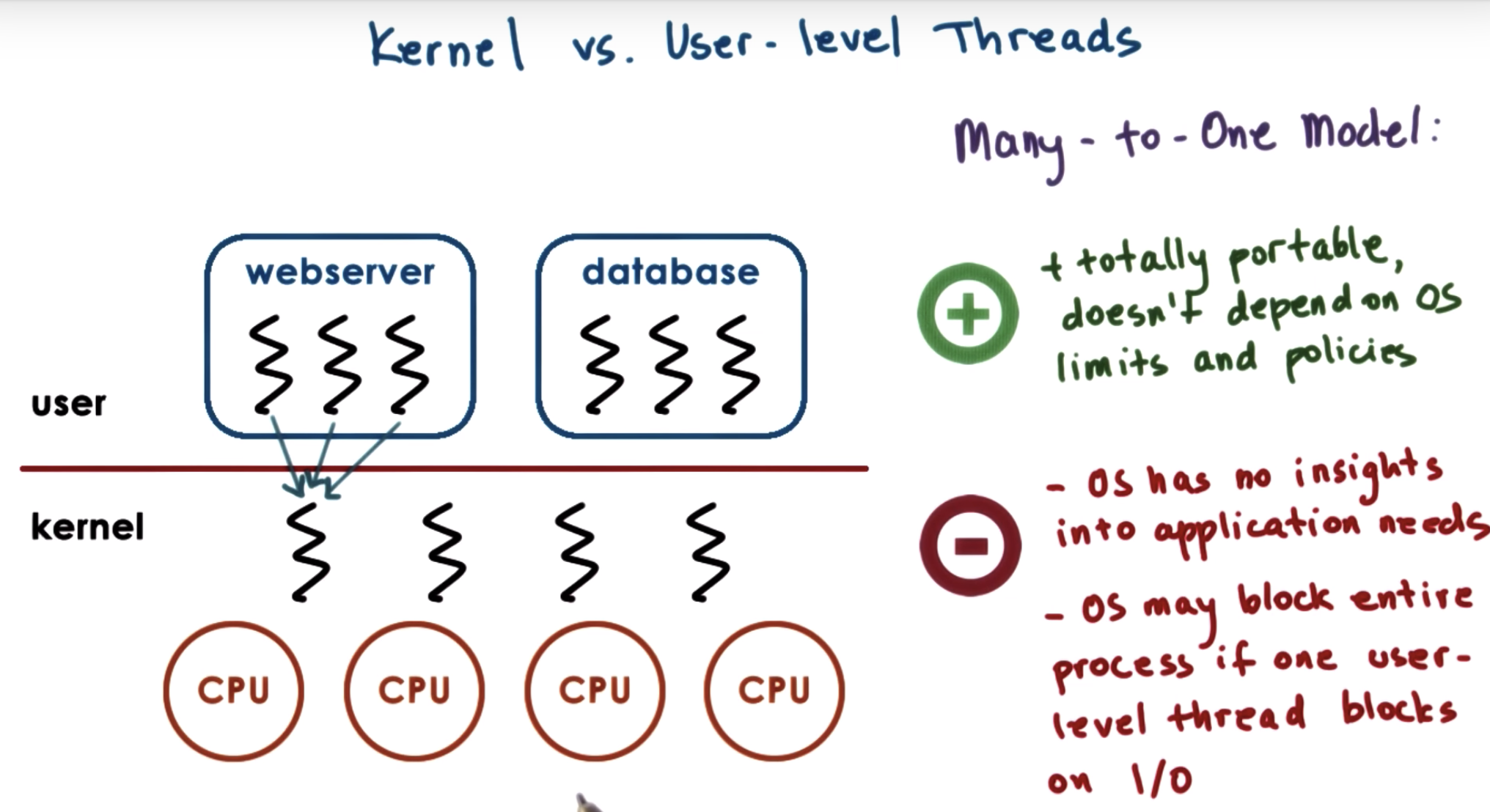
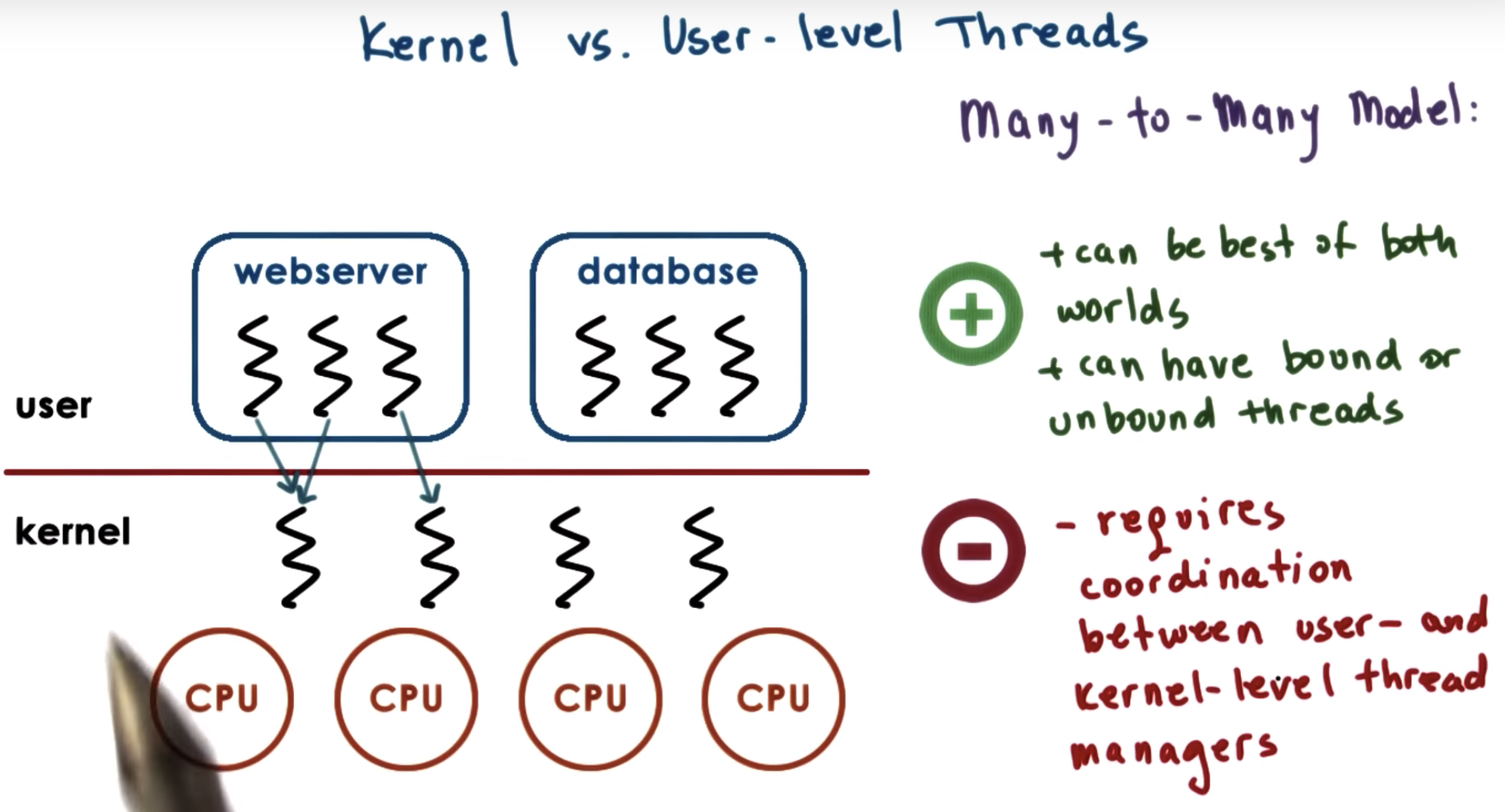
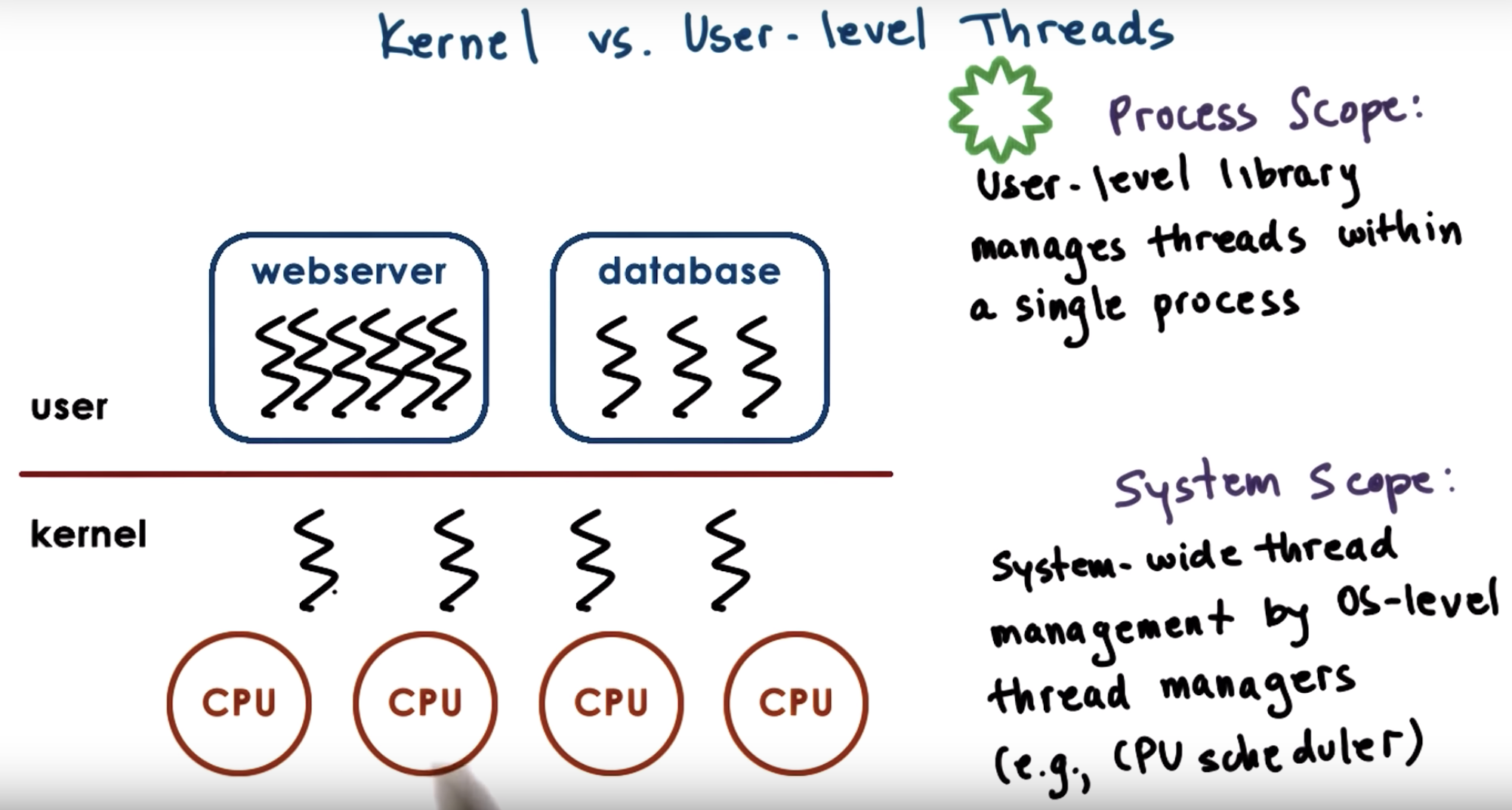
at kernel level, we have system-wide thread management that's supported by the operating system-level thread managers.
That means that the operating system thread managers will look at the entire platform making decision, as to how to allocate resources to the threads.
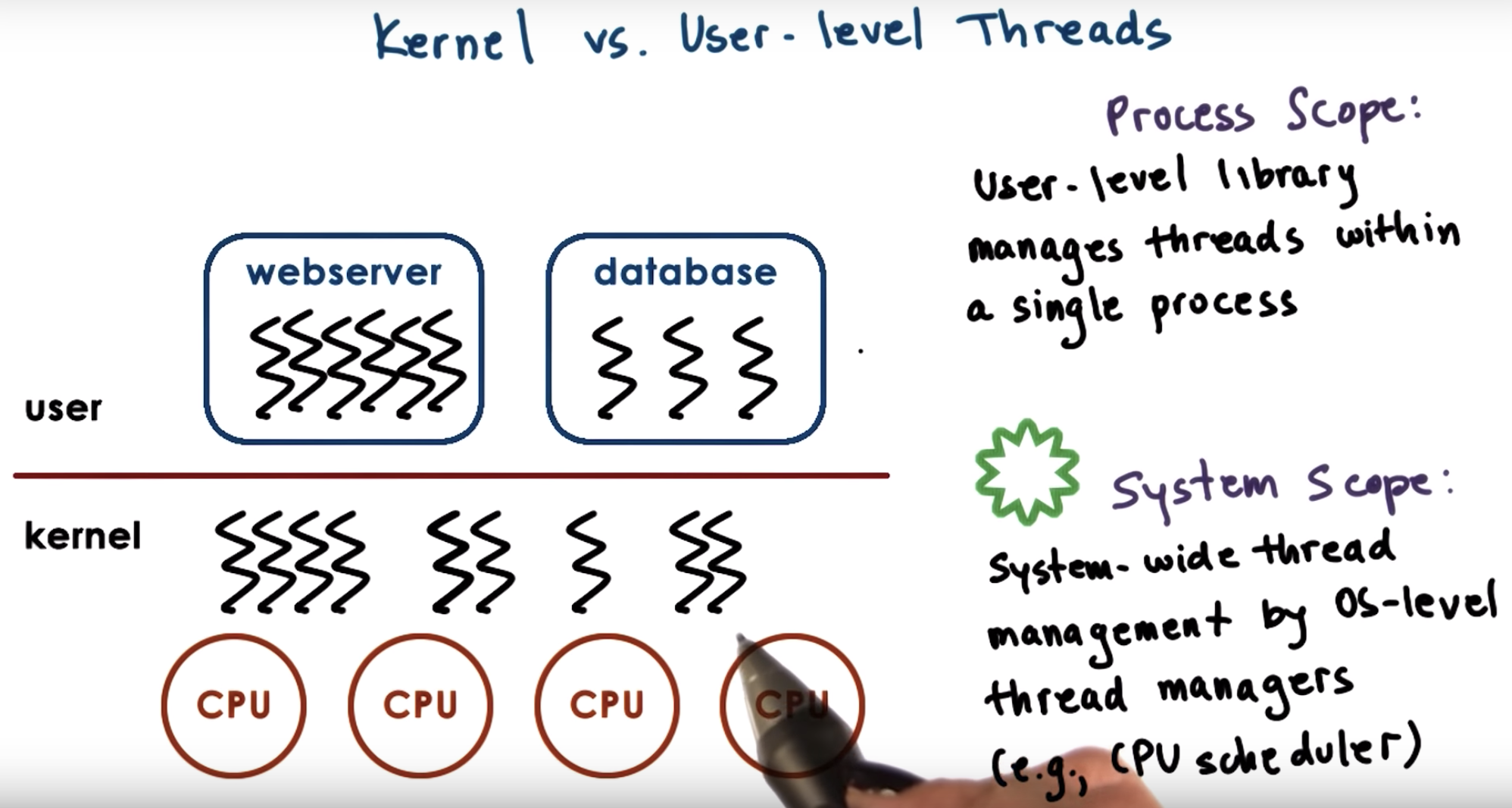
system scope manager will know the thread number in each process, while process scope manager will allocate resource equally to different processes.


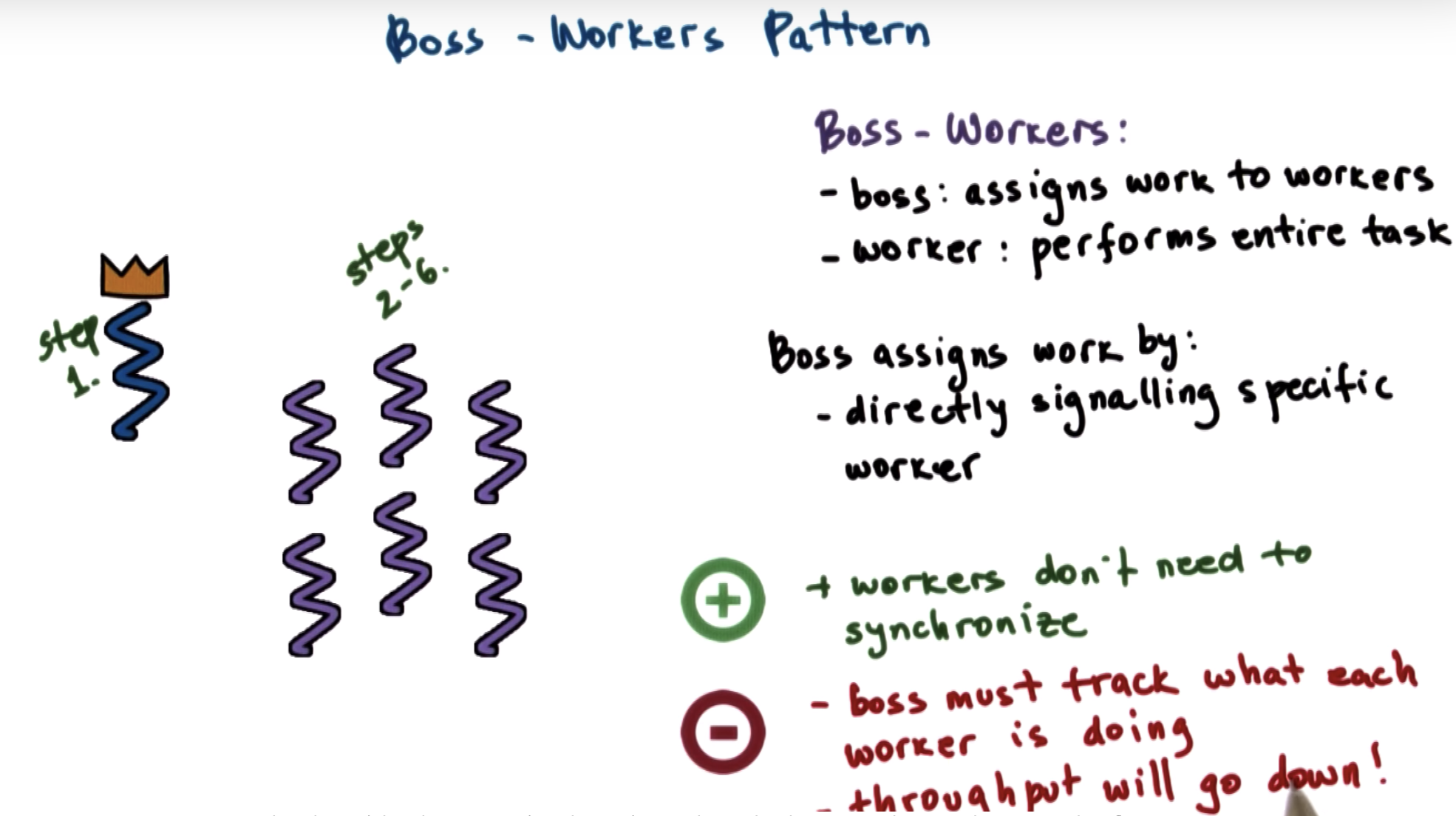


there's some probability that some worker may be more efficient at performing that exact same task in the future.
But the boss isnt paying attention to what the workers are doing, it has no way of making that kind of optimization.
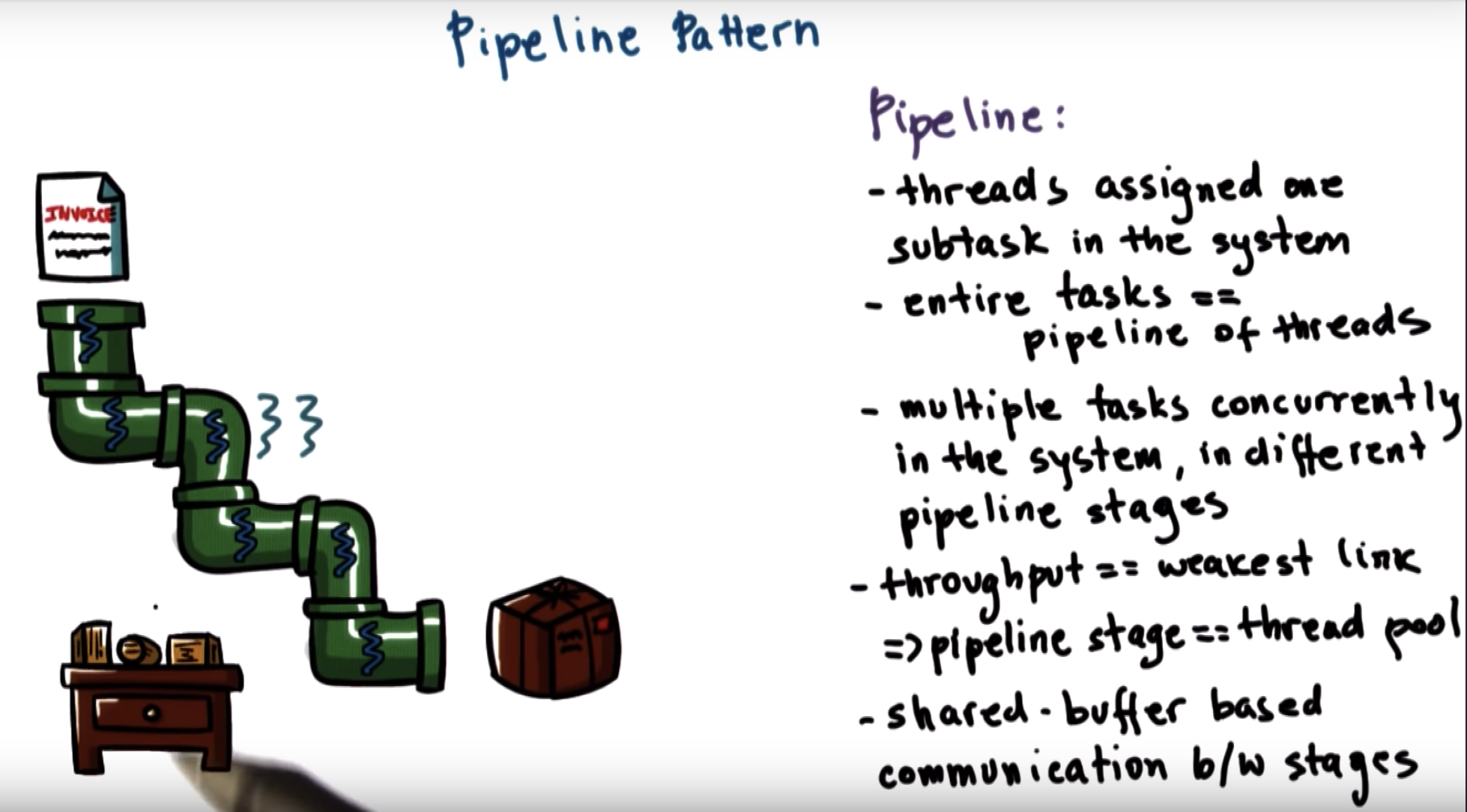
tasks are divided into subtasks and each thread is in charge of one subtask.
the entire complex task is executed as a pipeline of threads.
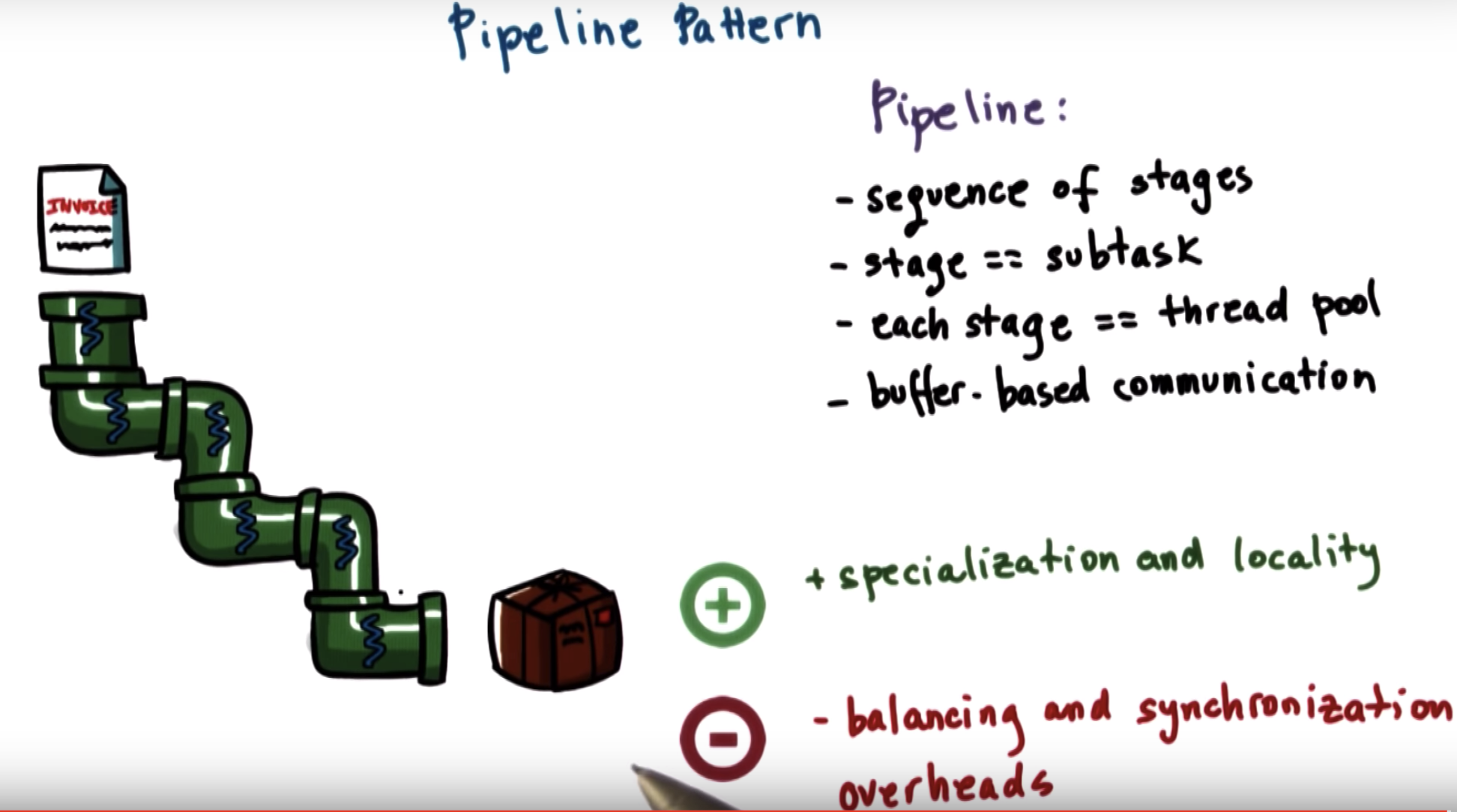
Ideally, we would love it if every single stage of the pipeline takes approximately the same amount of time
So the way to deal with this is using the same thread pull technique that we saw before.
If one of the pipeline stages takes more amount of time, then we can assign multiple threads to this particular stage.
=> a stage is a dynamic thread pool
communication between threads:
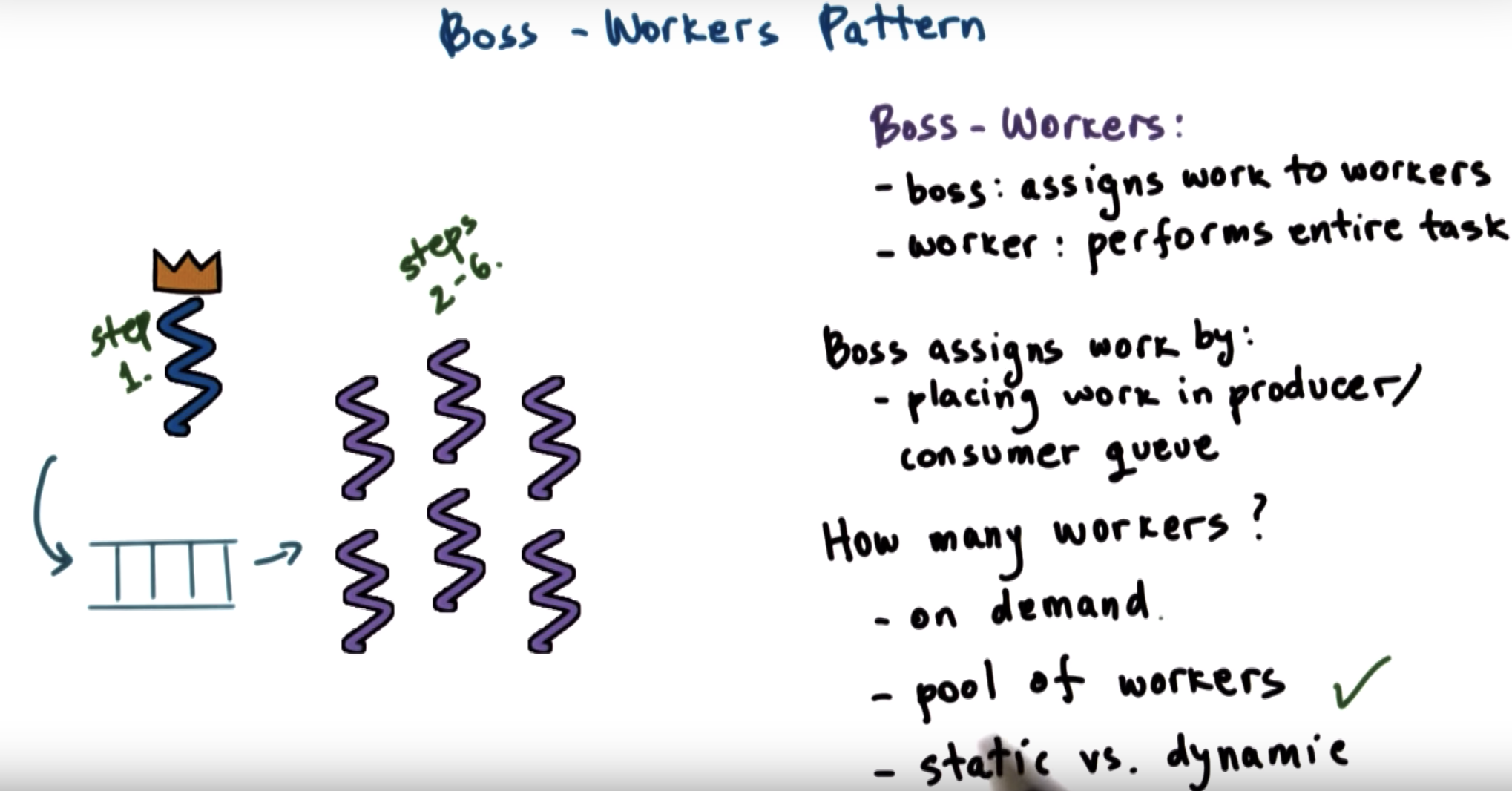
(1) directly: it would require workers directly to hand off the output of their processing
(2) shared-buffer: a worker leaves the output of its processing onto a "table", for the the next worker to pick up, whennever the second one is ready.

in boss-workers solution, one thread has to be the boss, and other 5 becomes workers.



