如果我们想知道当前运行的hadoop集群的状态,可以通过hadoop的客户端和web页面来获得,但是如果我们想知道当前集群的繁忙程度,如读写次数,这些工具就办不到了。幸运的是hadoop提供了一种ganglia的数据采集方式。在这篇文章里,将介绍一下hadoop与ganglia的配置方式。
Hadoop 版本:1.2.1
OS 版本: Centos6.4
Jdk 版本: jdk1.6.0_32
Ganglia 版本:3.1.7
环境配置
|
机器名 |
Ip地址 |
功能 |
|
Hadoop1 |
192.168.124.135 |
namenode, datanode, secondNameNode jobtracker, tasktracer |
|
Hadoop2 |
192.168.124.136 |
Datanode, tasktracker |
|
Hadoop3 |
192.168.124.137 |
Datanode, tasktracker |
|
ganglia |
192.168.124.140 |
Gmetad,gmond ganglia-web |
基本架构
hadoop1, hadoop2, hadoop将数据发送给ganglia节点上的gmond, gmetad定期向gmond获取数据,最后通过httpd显示出来。
安装ganglia
Yum仓库中没有ganglia,需要安装一个epel仓库
rpm -Uvh http://dl.Fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
在ganglia依次运行
Yum install ganglia-gmetad
Yum install ganglia-gmond
Yum install ganglia-web
运行完这三条命令后,整个ganglia环境就准备好了,包括httpd,php
配置ganglia
vi /etc/ganglia/gmetad.conf 修改data_source
data_source "my_cluster" ganglia
vi /etc/ganglia/gmond.conf
单播模式
cluster {
name = "my_cluster"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
#mcast_join = 239.2.11.71
host = 192.168.124.140
port = 8649
ttl = 1
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
#mcast_join = 239.2.11.71
port = 8649
#bind = 239.2.11.71
}
vi conf/hadoop-metrics2.properties
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
*.sink.ganglia.supportsparse=true
*.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both
*.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40
namenode.sink.ganglia.servers=192.168.124.140:8649
datanode.sink.ganglia.servers=192.168.124.140:8649
jobtracker.sink.ganglia.servers=192.168.124.140:8649
tasktracker.sink.ganglia.servers=192.168.124.140:8649
maptask.sink.ganglia.servers=192.168.124.140:8649
reducetask.sink.ganglia.servers=192.168.124.140:8649
启动
先关闭防火墙: service iptables stop
启动httpd: service httpd start
启动gmetad: service gmetad start
启动gmond: service gmond start
启动 hadoop集群:bin/start-all.sh
结果
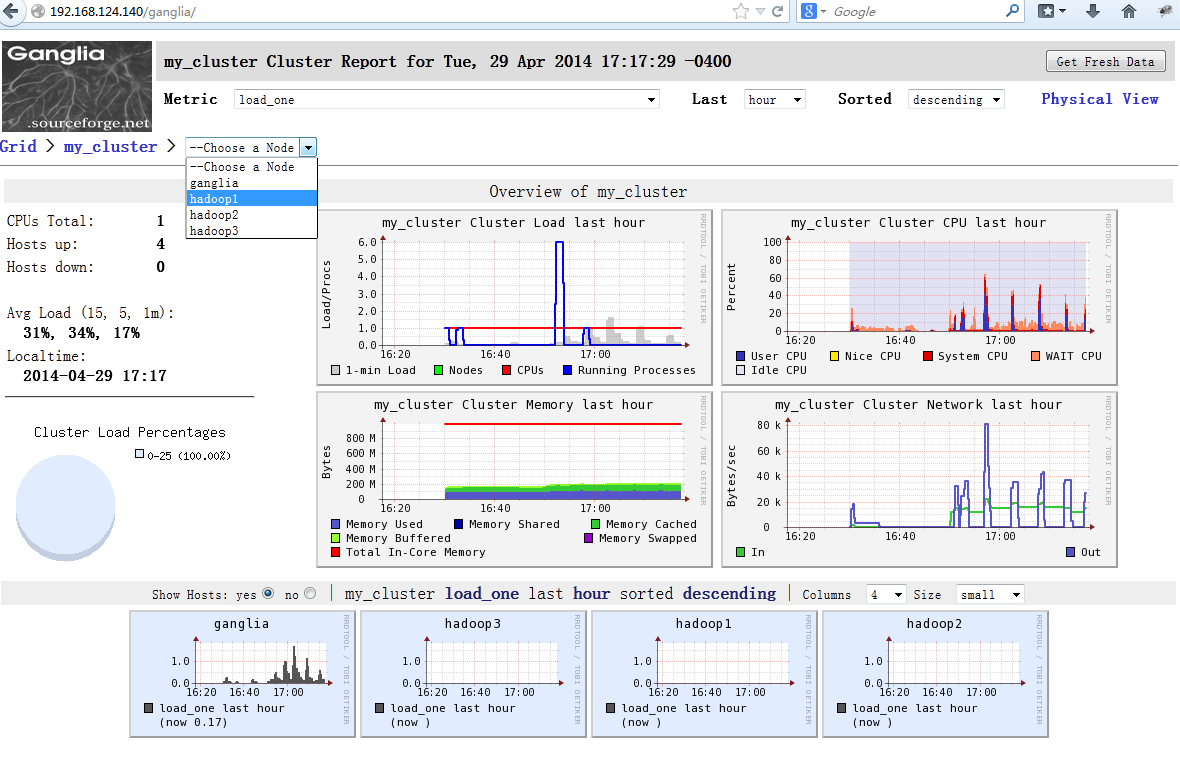
从图上可以看出,我们已经成功的显出ganglia, hadoop1, hadoop2, hadoop3的信息

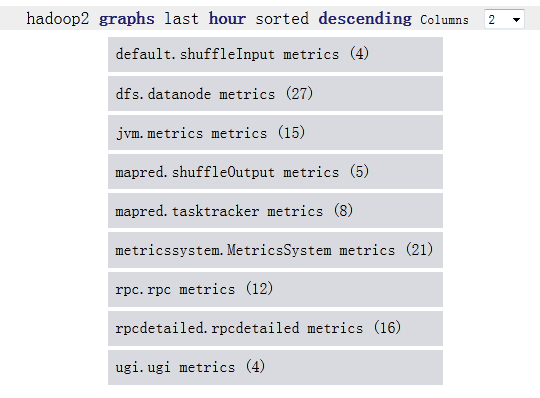
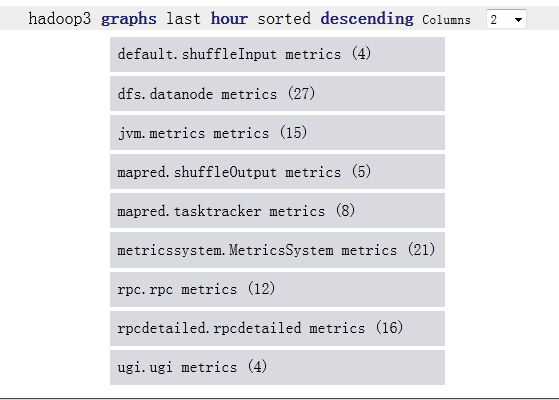
Hadoop2和hadoop3都监控datanode,tasktracker,他们显示的metric是一样的
Hadoop1比hadoop2,hadoop3多运行三个组件:namenode, secondnamenode, jobtracker,所以会多出dfs.FSNameSystem metrics,dfs.namenode metrics,mapred.Queue metrics,mapred.jobtracker metrics
下面我们将列出hadoop1节点上所有metric的图,有兴趣的可以看一看。
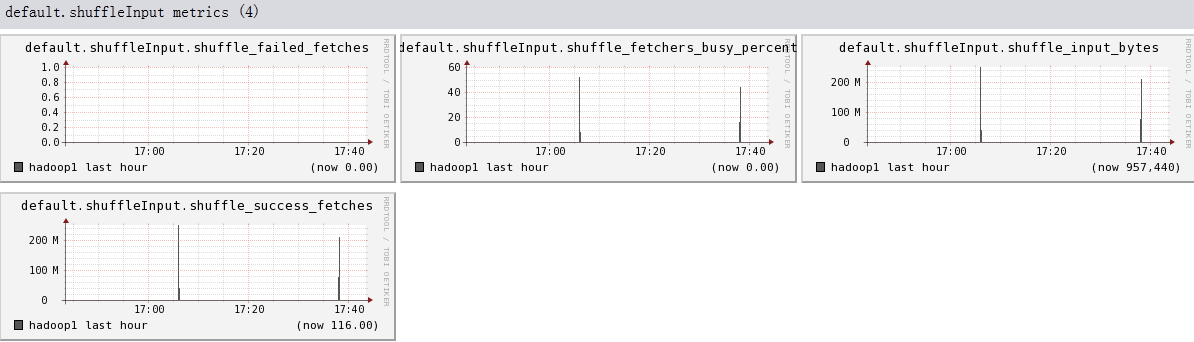
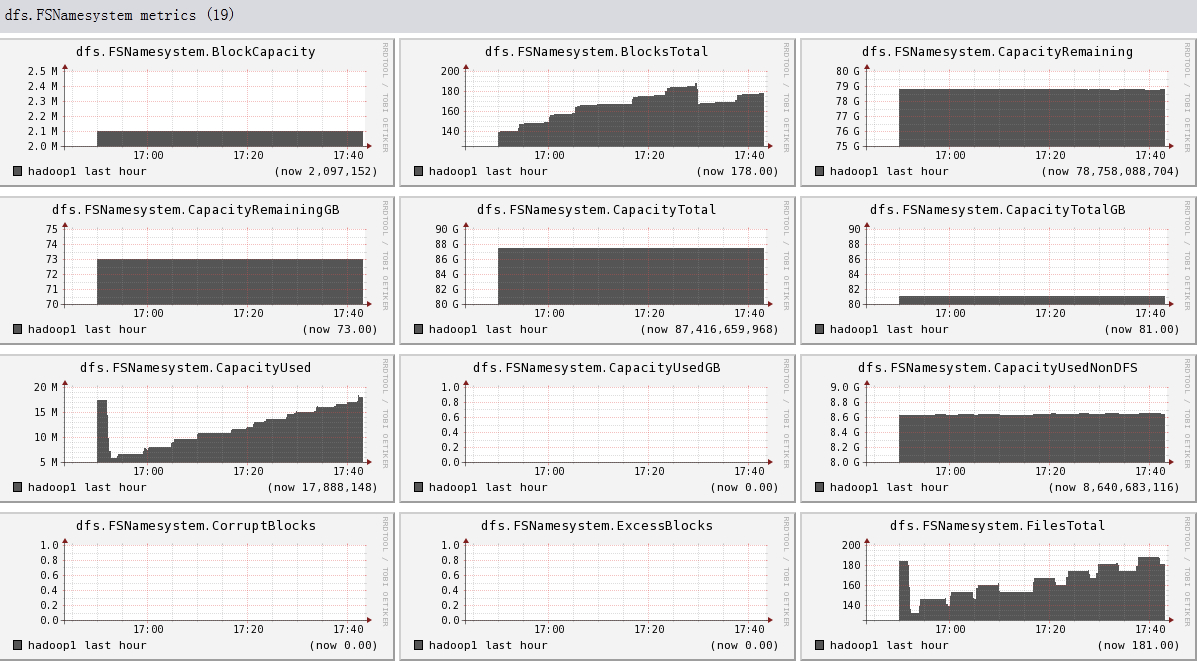
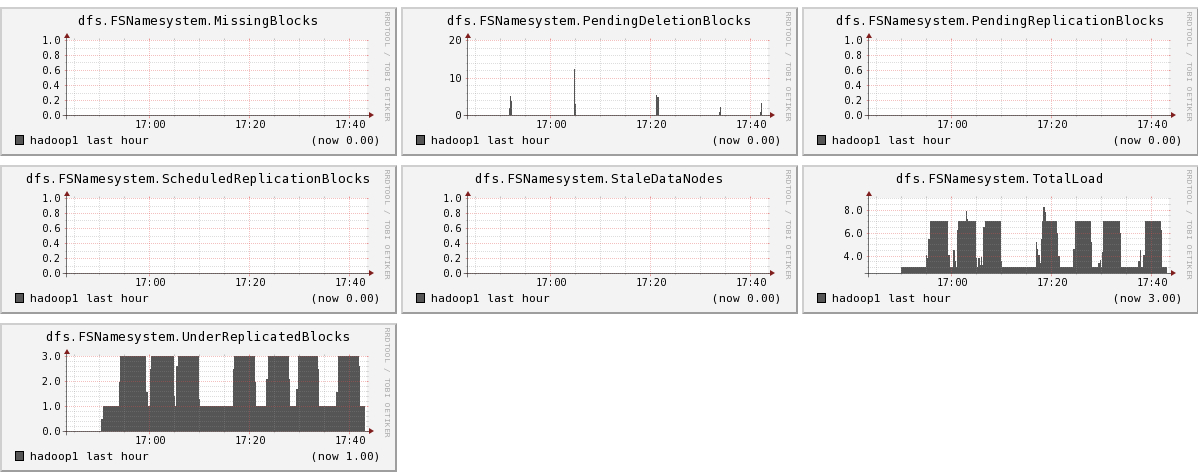
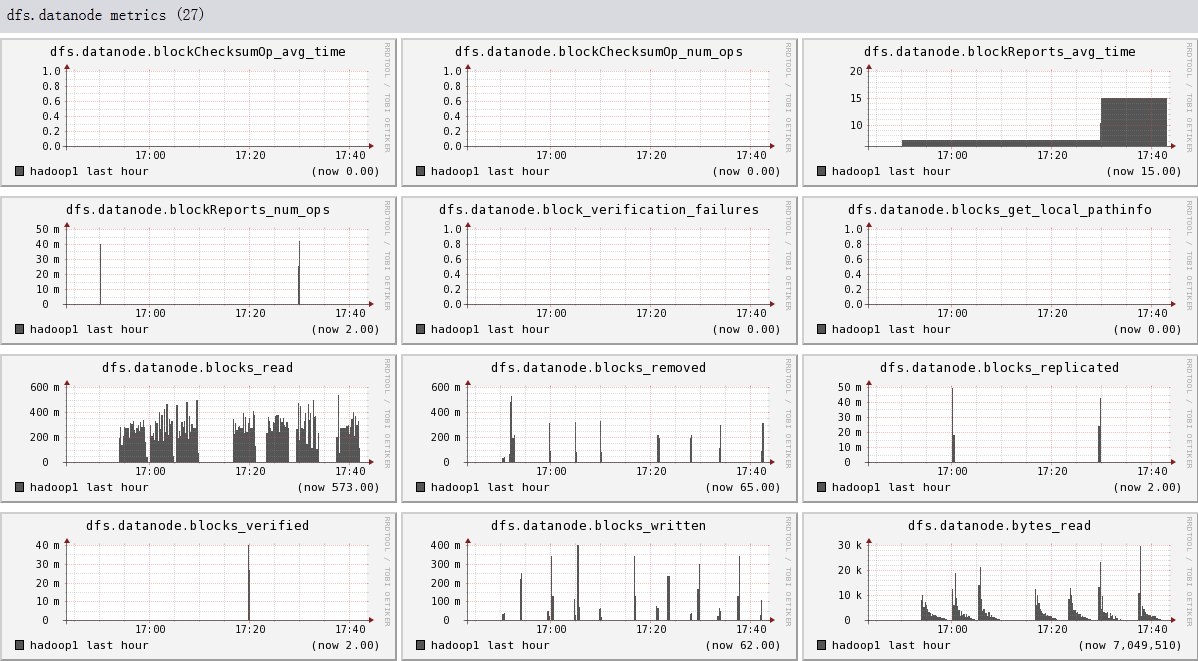
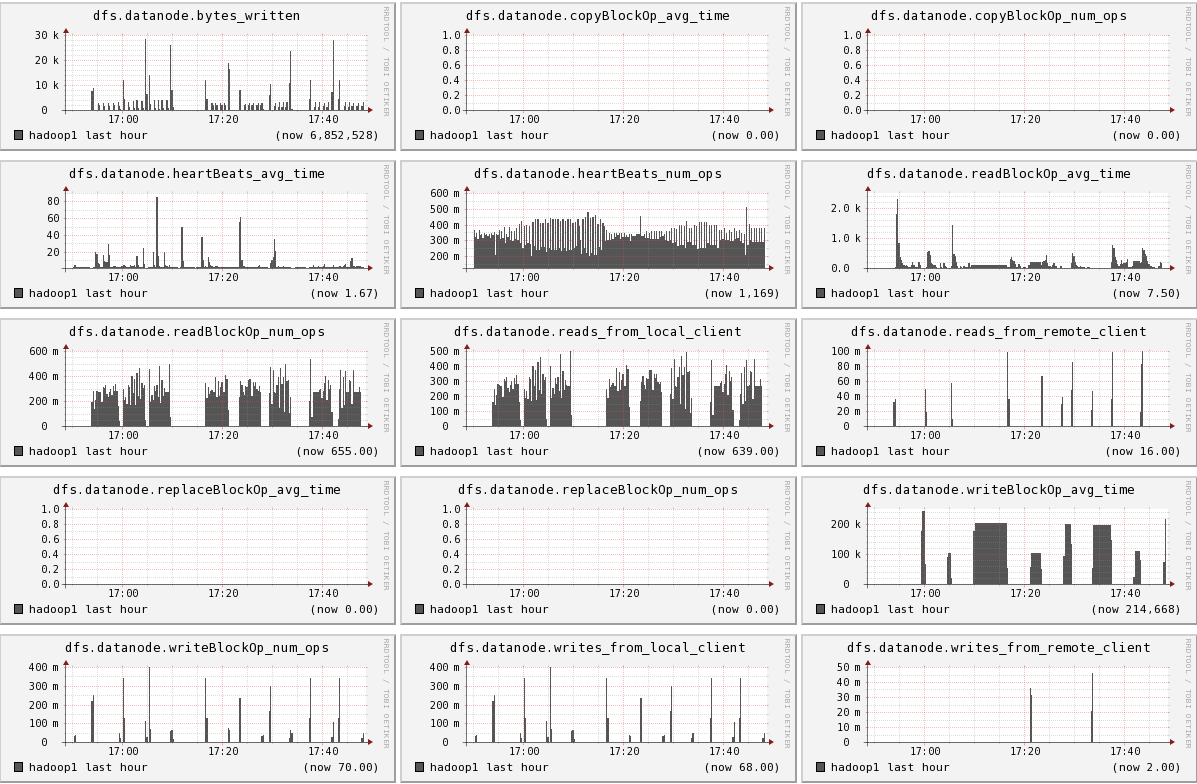
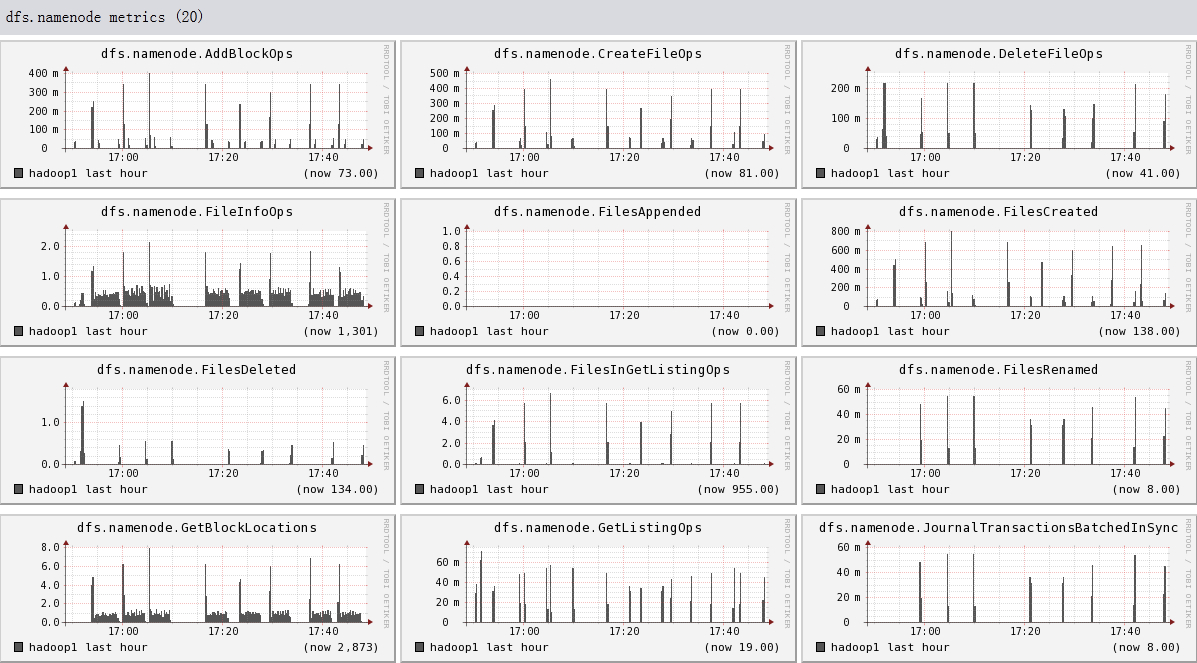
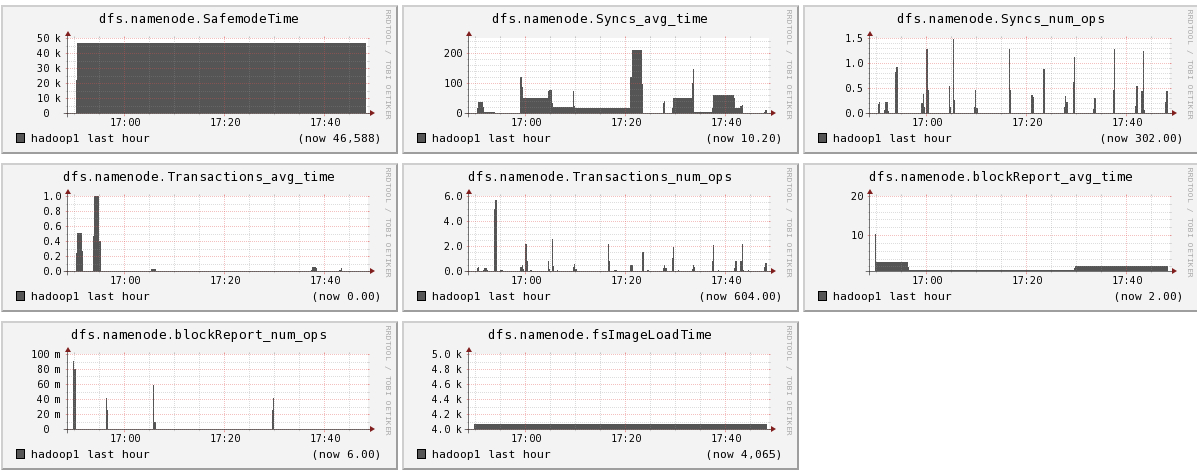
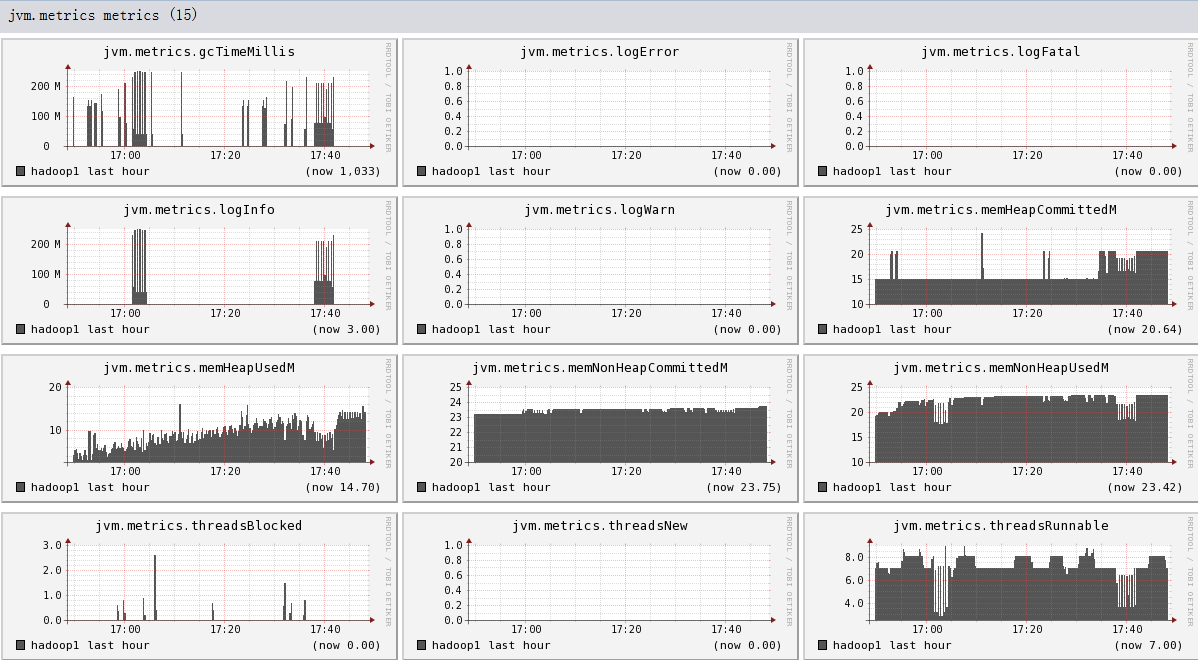

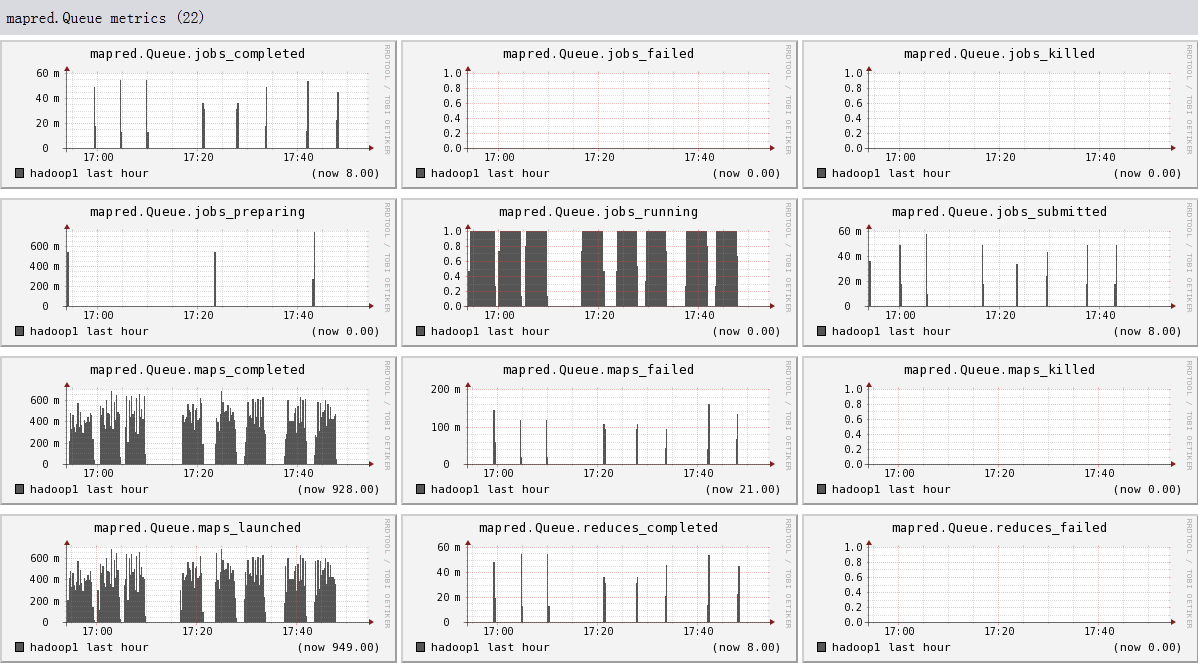
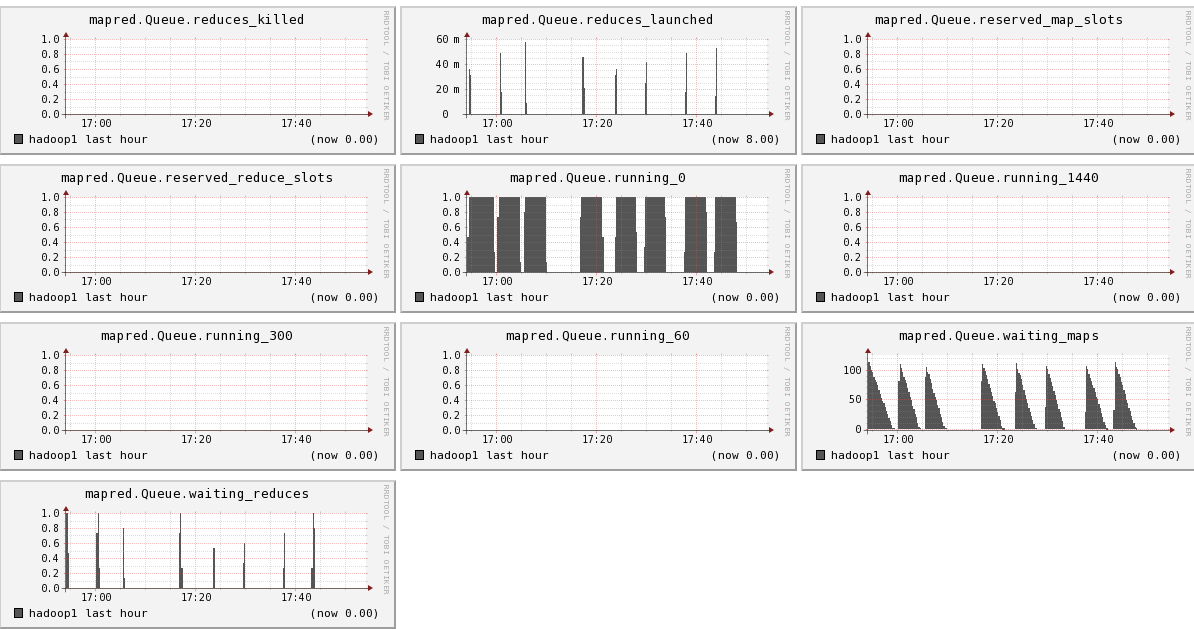
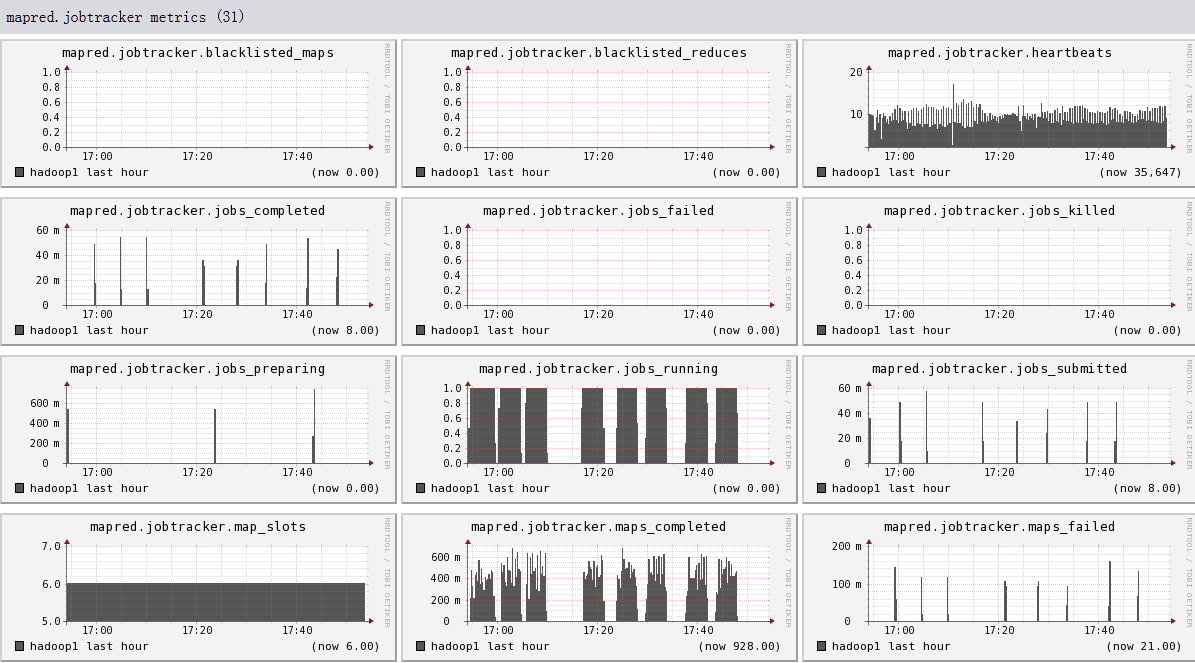
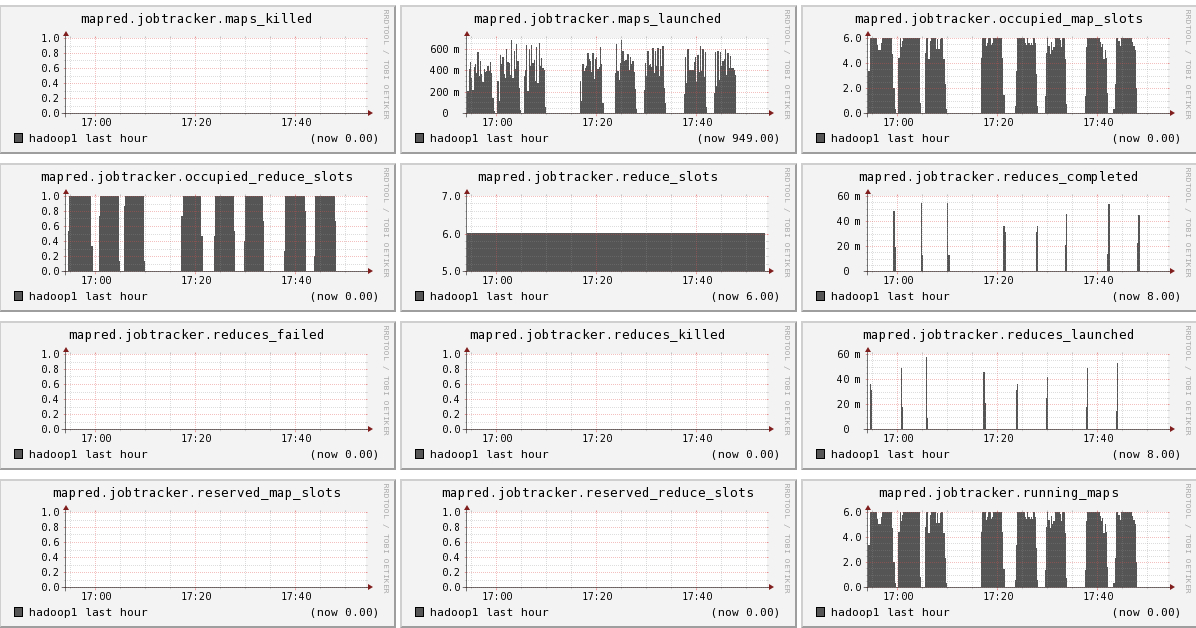
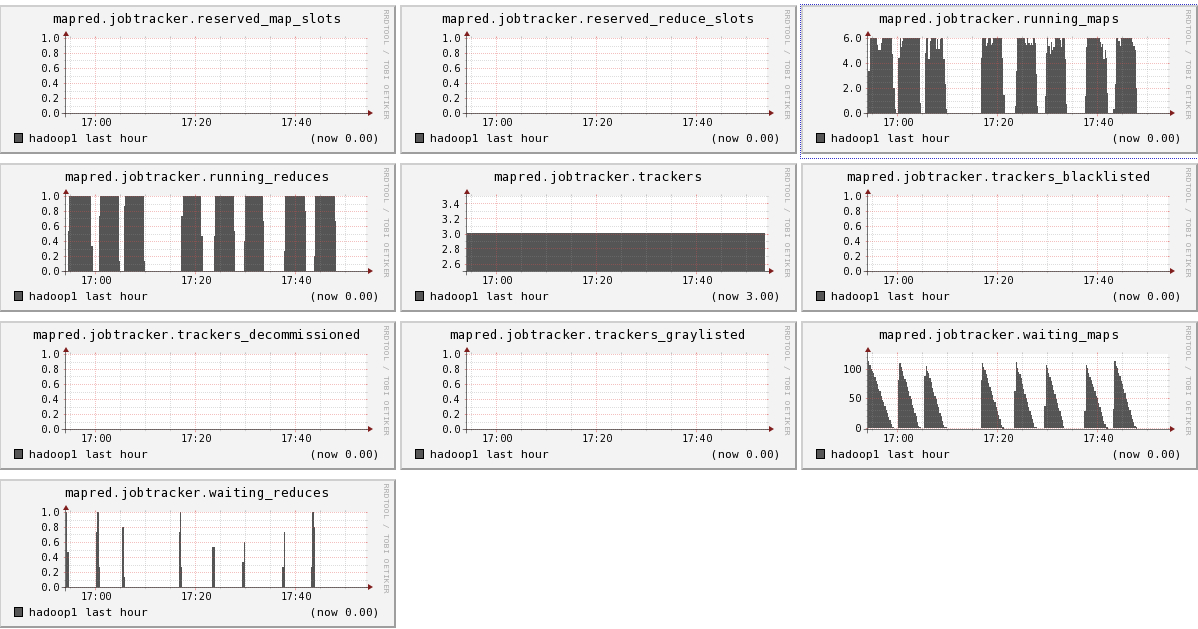
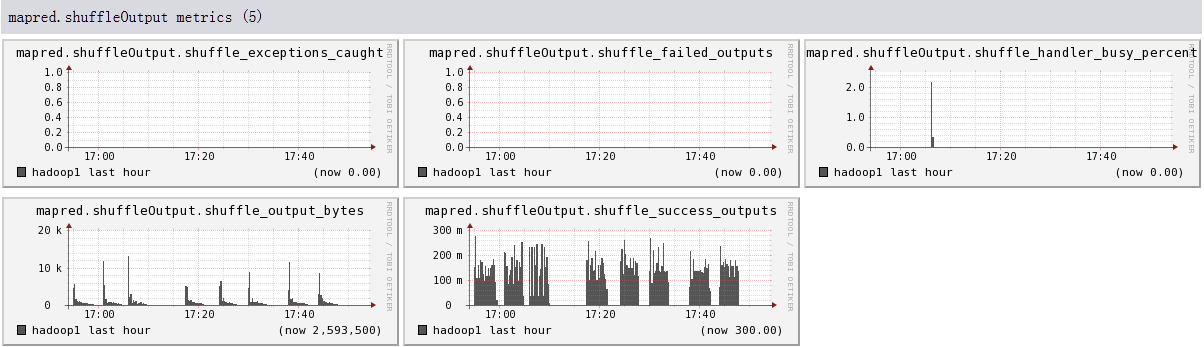
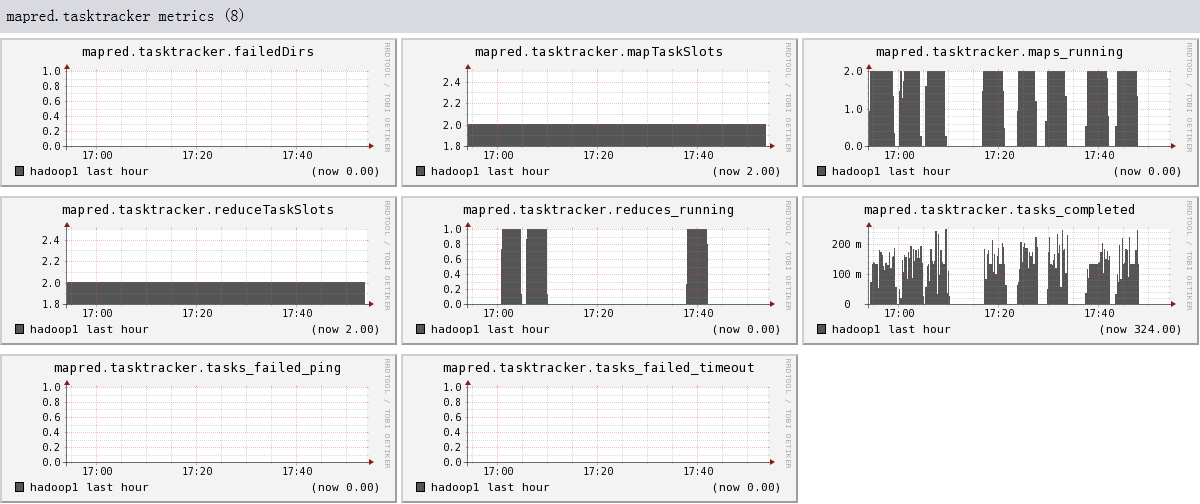
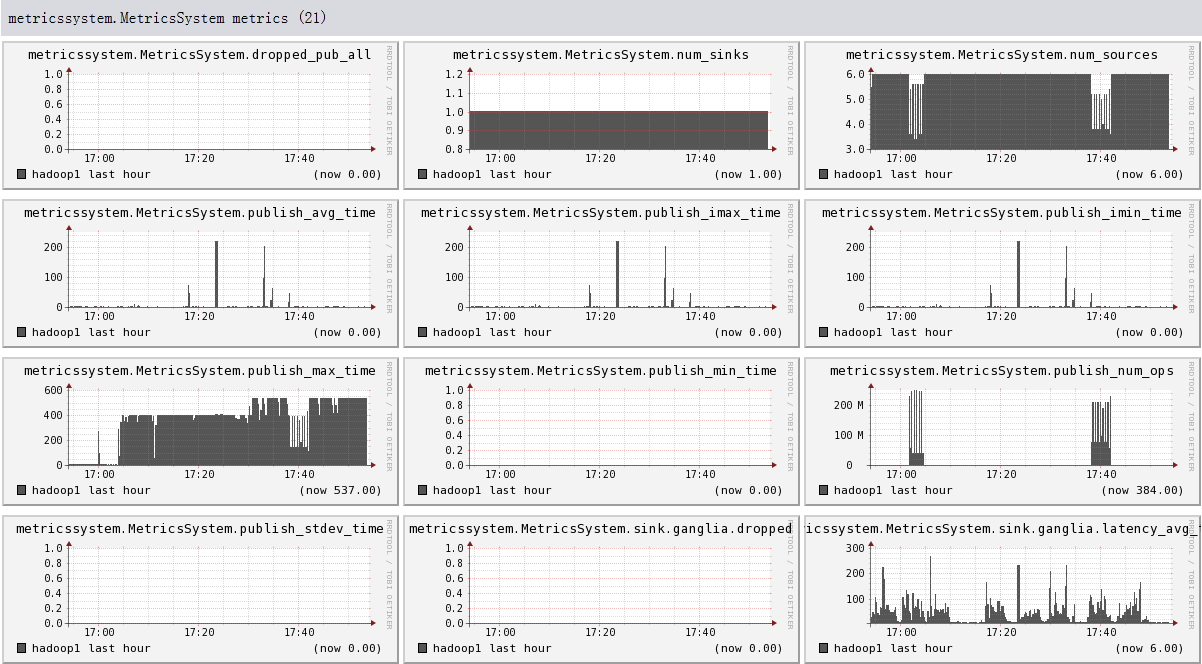
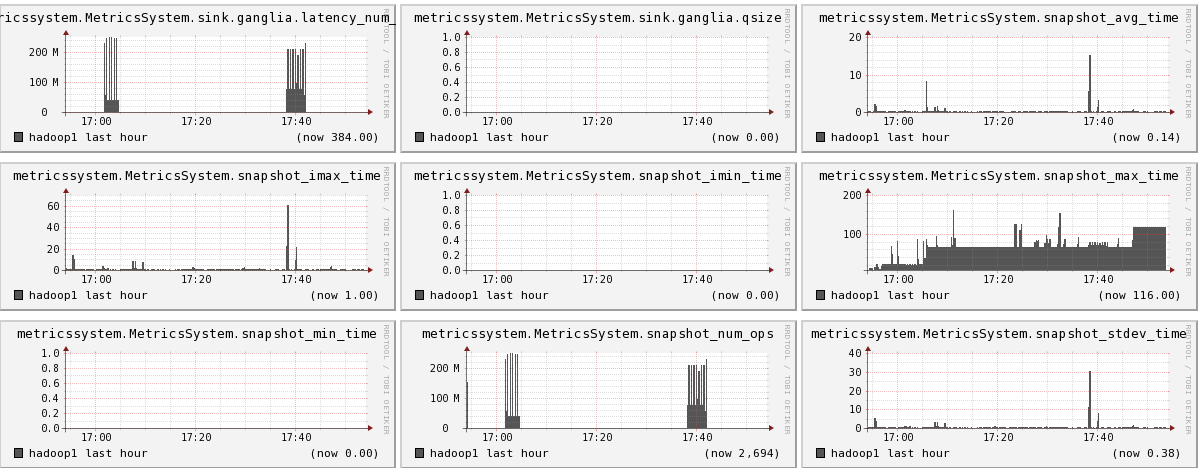

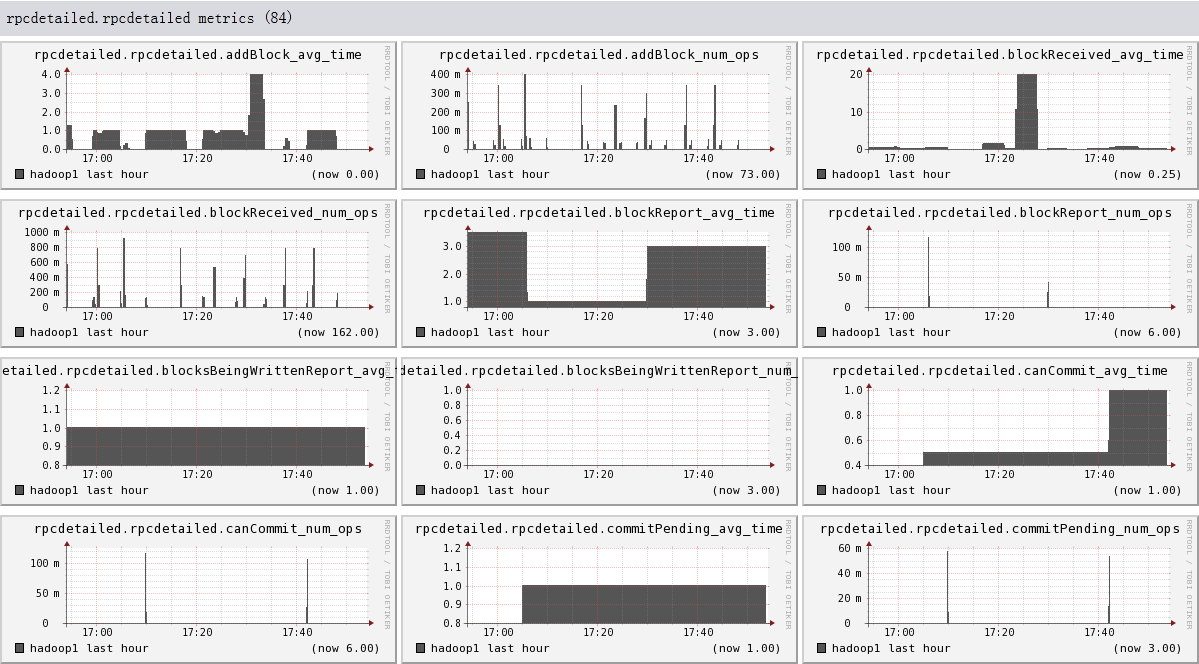
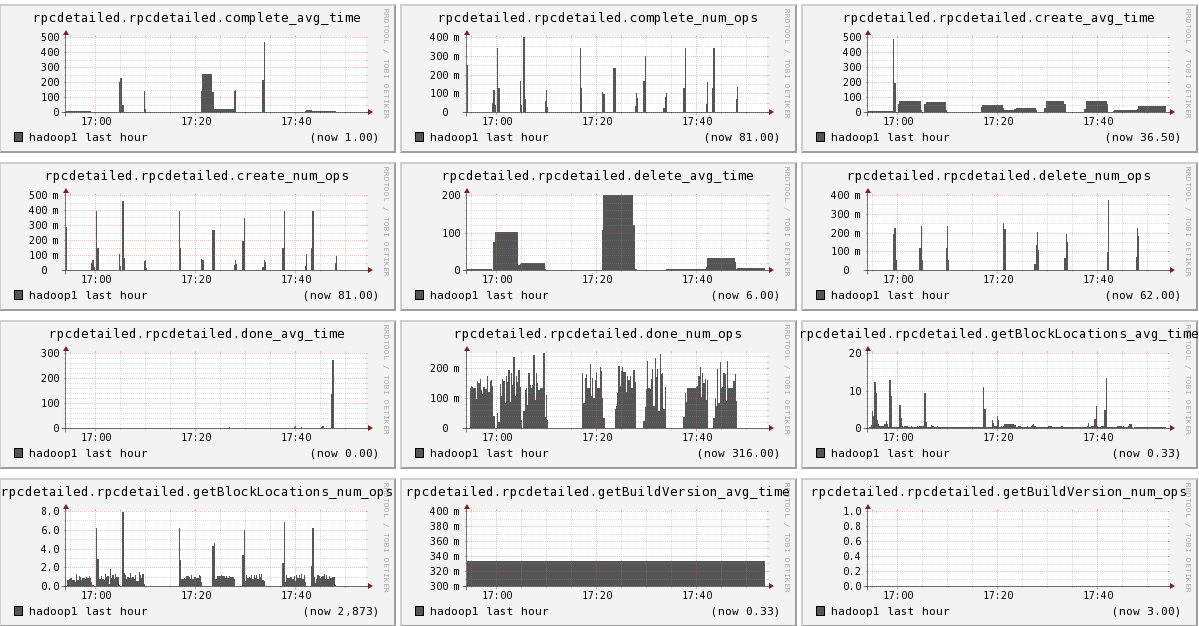
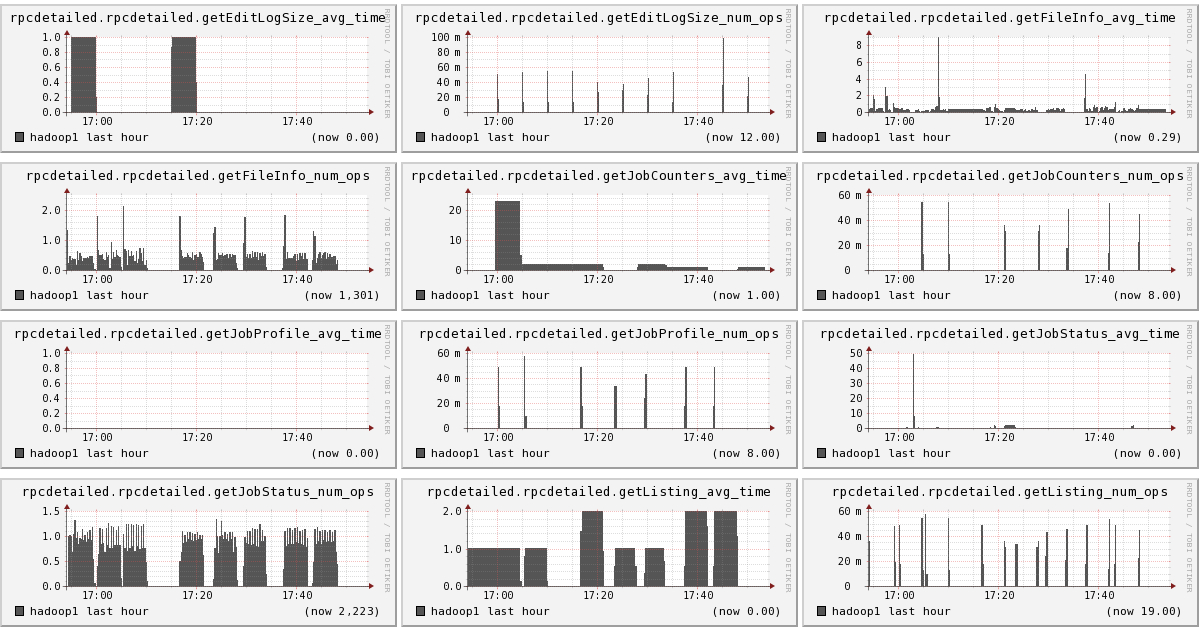
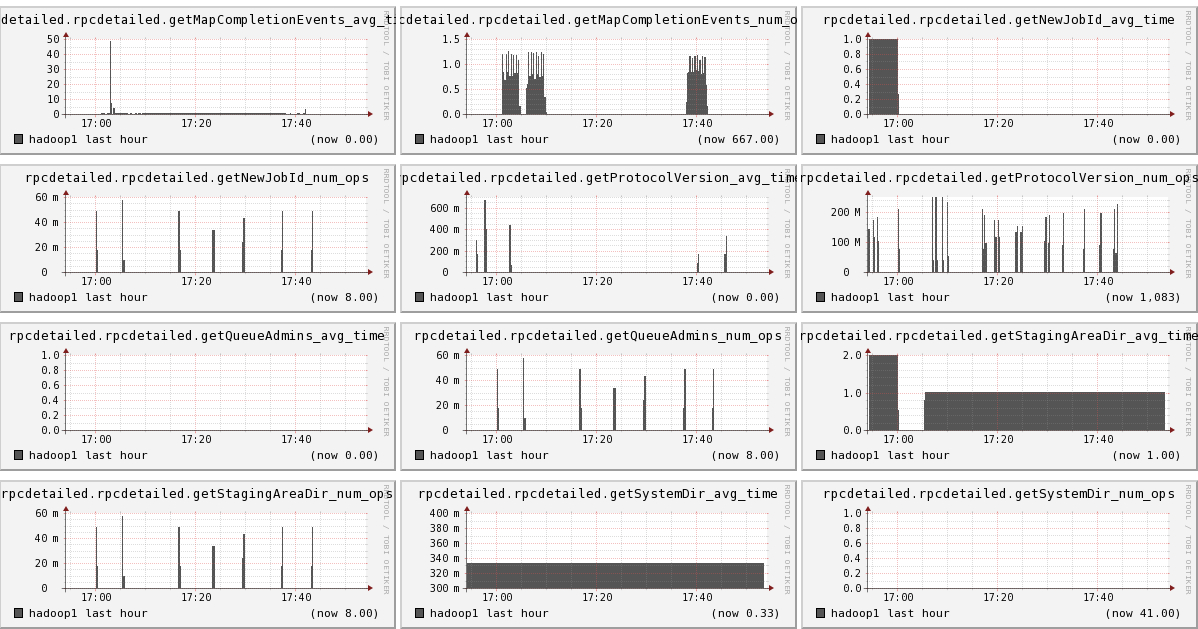
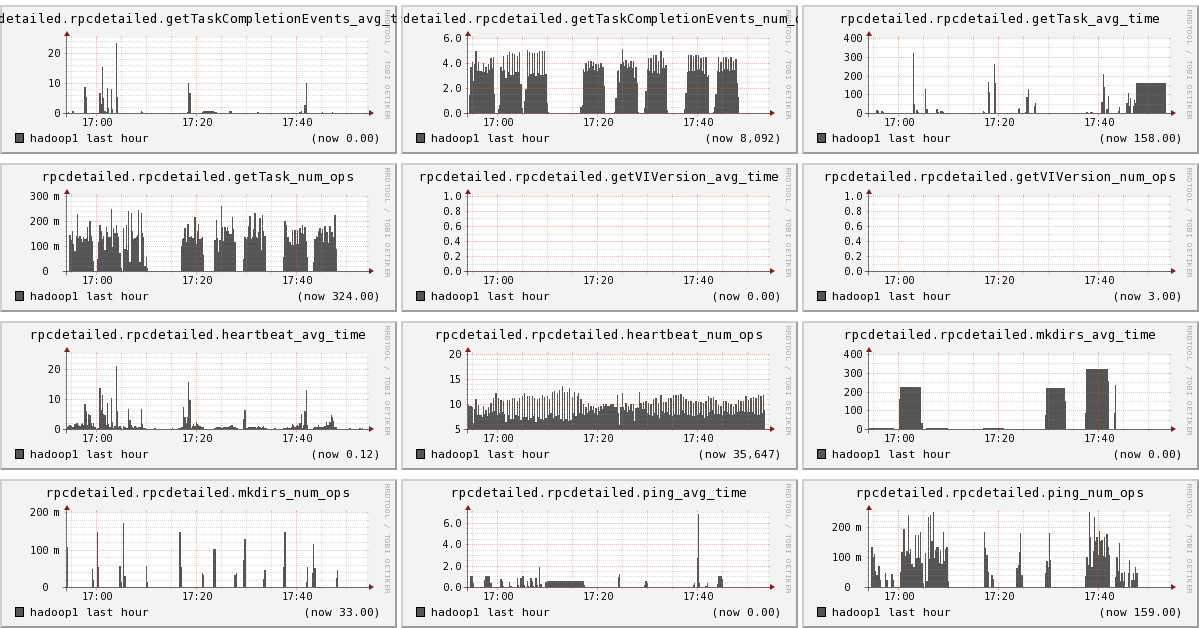
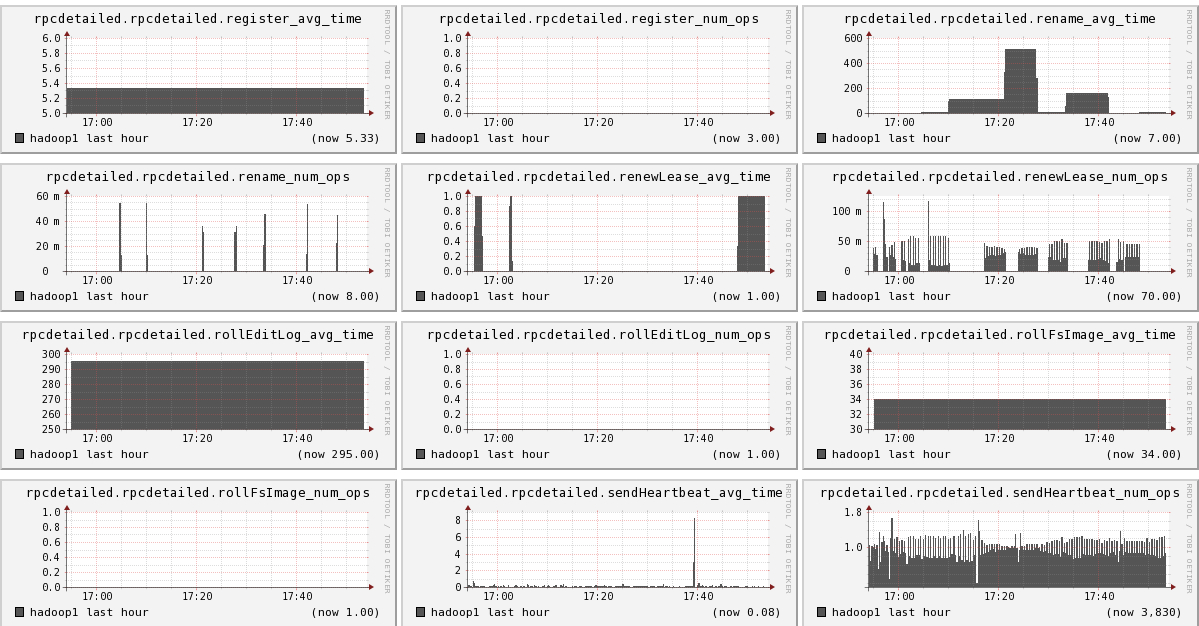
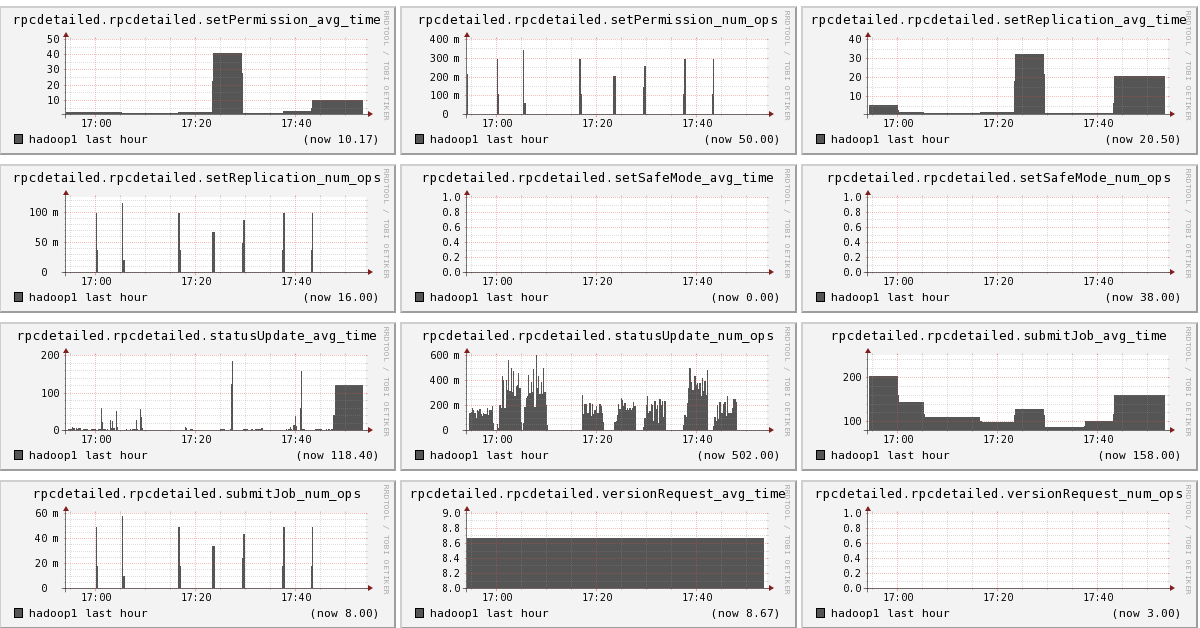
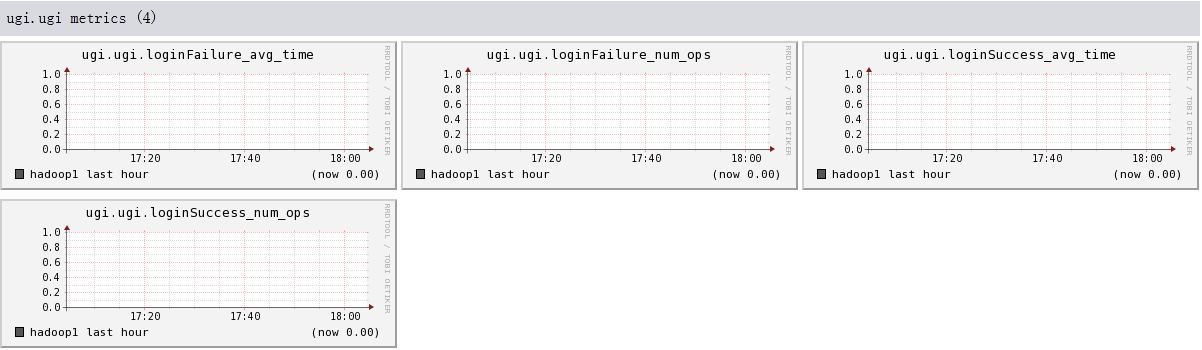
结论
- 此hadoop集群是没有启动security,因为ugi没有数据
- 可以看出hadoop的一些参数信息
- 可以看出目前hadoop的一些系统信息,是否繁忙