numpy的np.fromfile会出现如下的问题,只能一次性读取文件的内容,不能追加读取,连续两次的np.fromfile读到的东西一样
如果数据文件太大(几个G或以上)不能一次性全读进去,需要追加读取
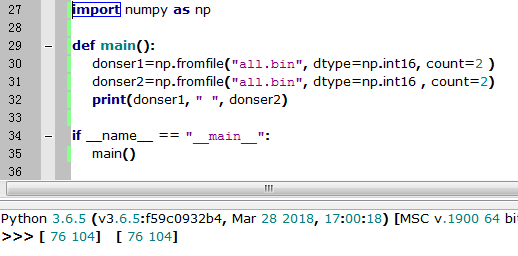
而我希望读到的donser1和donser2是连续的两段
(实际使用时,比如说读取的文件是二进制数据文件,每一块文件都包括包头+数据,希望将这两块分开获取,然后再做进一步处理)
代码:
import numpy as np length=2500 plt_arr=np.linspace(0.0, 0.0, length*2048*16) start=0 tail_size = 40 #40bit num_size=16*1024-40 # 16kb -40b def one_file(f, loop): global tail_size, num_size while loop: num = np.fromfile(f, dtype=np.int16, count=num_size) tail=np.fromfile(f, dtype=np.int16, count=tail_size) loop=loop-1 yield num, tail def main(): file_path="E://1-gl300c.r3f" global length, plt_arr, start loop=length with open(file_path, 'rb') as f: for num, tail in one_file(f, loop): plt_arr[start:start+len(num)]=num[:] start=start+len(num) return plt_arr[0:start] if __name__ == "__main__": donser=main() print(donser)
假设数据文件的格式是 数据+包尾,plt_arr存储全部的数据部分,包尾丢弃,该方法实现了多次连续追加读取数据文件的内容
plt_arr最好使用先开好大小再逐次赋值,亲测append方法和concatenate方法时间效率极差
或者不用numpy也可以,代码:
def read_in_chunks(filePath, chunk_size=16*1024): file_object = open(filePath,'rb') count=0 while True: chunk_data = file_object.read(chunk_size) if not chunk_data: break yield chunk_data[0:16*1024-28] if __name__ == "__main__": num=0 for chunk in read_in_chunks("E:\1-gl300c.r3f"): #process(chunk) # <do something with chunk> name=str(num)+".bin" num=num+1 if num<303000: continue if num>308001: break file_object = open(name, 'wb') file_object.write(chunk) file_object.close( )
numpy.fromfile的其他方法可以参考这个