(本系列只用作本人笔记,如果看官是以新手开始学习RL,不建议看我写的笔记昂)
今天是2020年2月7日,开始二刷david silver ulc课程。https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
还记得去年九月份在YOUTUBE上硬刚david silver课的时候的激情。
david silver课件汇总:(共10节课)
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
课程资料下载(我的蓝奏云):https://www.lanzous.com/b00z7vhcd ,密码david
强化学习,比较形象地说,是找到求生法则的一门技术。这是我最开始对这门技术感兴趣的原因。我最初对RL感兴趣是因为机器通过这门技术竟然能像智慧生命体一样摸爬滚打学到求生法则并“活”下去。这就很迷了。当时下决心一定要搞清楚是怎么回事。
强化学习把世界抽象为两部分,主观能动体agent和客观环境env。 智能主体,称为agent。相当于生命体。而外部环境称为env(envirnment)。
我们要做的,就是训练这个agent,提升它的智力能力,使之更好的应对env。就像大自然草原上刚出生的一只小鹿,逐渐学会在草原上生存。
将事物的发展变化抽象为一组State序列。每一个State是具体某个时间点的状态。
对于agent。把agent的行为抽象为行为空间A。A可以是离散的可以是连续的。把agent应对环境的反应方案抽象为策略pai:OxA—>[0,1]
对于env。reward激励是agent在做出行为a之后env给agent的feedback。比如说,小鹿吃到草了,那么reward为+1,小鹿被老虎吃了,reward为-99。
一些小总结:
1.强化学习不同于其他机器学习算法,它们的基础理论可以说正交.其他的机器学习算法大多在贝叶斯理论的基础上发展而来.而强化学习是以马尔可夫决策过程MDP<S,A,R,seta,P>为基础而来.它依靠反馈有一定延时的Reward激励信号而学习.
2.马尔可夫性:
未来stage只受当前stage影响,而与过去stage无关,即

3.agent状态 & env状态 辩解(摘自叶强知乎)
- 完全可观测的环境 Fully Observable Environments(个体对环境的观测 = 个体状态 = 环境状态)
正式地说,这种问题是一个马儿可夫决定过程(Markov Decision Process, MDP)
- 部分可观测的环境 Partially Observable Environments(个体状态 ≠ 环境状态)
个体间接观测环境。举了几个例子:
- 一个可拍照的机器人个体对于其周围环境的观测并不能说明其绝度位置,它必须自己去估计自己的绝对位置,而绝对位置则是非常重要的环境状态特征之一;
- 一个交易员只能看到当前的交易价格;
- 一个扑克牌玩家只能看到自己的牌和其他已经出过的牌,而不知道整个环境(包括对手的牌)状态。
正式地说,这种问题是一个部分可观测马儿可夫决策过程。个体必须构建它自己的状态呈现形式,比如:记住完整的历史:
这种方法比较原始、幼稚。还有其他办法,例如 :
1. Beliefs of environment state:此时虽然个体不知道环境状态到底是什么样,但个体可以利用已有经验(数据),用各种个体已知状态的概率分布作为当前时刻的个体状态的呈现:
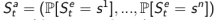
2. Recurrent neural network:不需要知道概率,只根据当前的个体状态以及当前时刻个体的观测,送入循环神经网络(RNN)中得到一个当前个体状态的呈现:
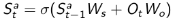
4.两对儿哲学理念辩解
4(1).预测和控制 Prediction & Control
预测:根据一个给出的POLICY,评价未来。可以看成是求解在给定策略下的价值函数(value function)的过程。
|——How well will I(an agent) do if I(the agent) follow a specific policy?
控制:找到最大化未来奖励的方案。
|——同样的条件,在所有可能的策略下最优的价值函数,最优策略是什么?
4(2).探索和利用 Exploration & Exploitation
在线广告推广时,显示最受欢迎的广告和显示一个新的广告;
油气开采时选择一个已知的最好的地点同在未知地点进行开采;
玩游戏时选择一个你认为最好的方法同实验性的采取一个新的方法。
5.学习和规划 learning & planning
learning和planning是设计一个RL算法以及理解一个RL算法要考虑的两个哲学概念。
learning就是去获知R(s,a)=?,planning就是根据已知迭代优化agent。
我们去设计一个RL算法,
如果env是给出的,那只搞planning就完了。
如果env没有给出,那肯定要先有learning再搞planning。
(env给出与否 = R(s,a) for any (s,a)是否给出)