一、深度拷贝:
(一般了解)
1、浅拷贝:
s=[[1,2],'alex','asada'] s2=s.copy() print(s2) s2[0][1]=3 print(s2) print(s)

从该程序中可知,当第二层列表中元素被修改后,原列表内容也发生变化,这是因为元素修改,改变了列表指针,使得s列表s[0]元素指向元素发生变化。如图所示:
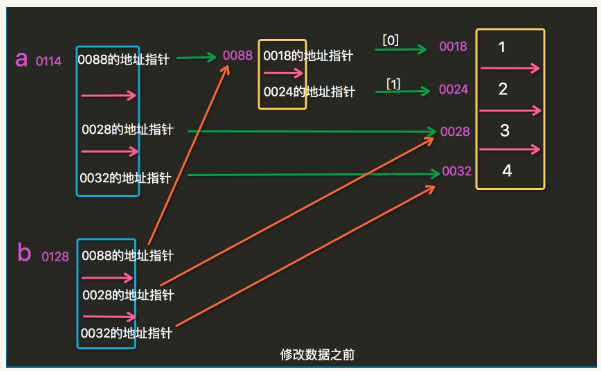
修改列表后,原列表发生变化(原因:a列表指针发生变化,造成原列表中列表数据变化)
浅拷贝:只拷贝第一层
深拷贝:全部拷贝
s3=[1,'alex','asada'] s4=s3.copy() s4[0]=2 print(s4) print(s3)
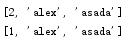
2、深度拷贝:
import copy s=[[1,2],'alex','asada'] s2=copy.deepcopy(s)#深拷贝操作 print(s2) s2[0][1]=3 print(s2) print(s)

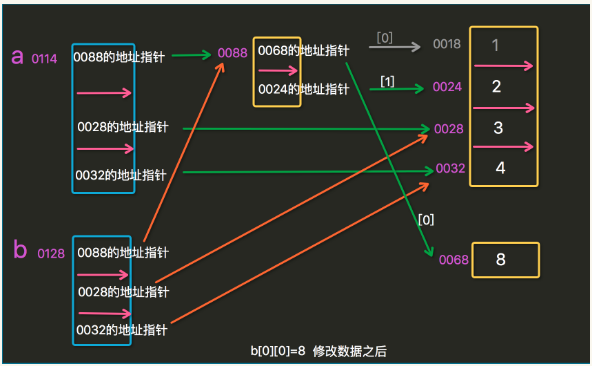
注意:深度拷贝操作后,即使新列表第二层被修改,原列表依然不变。
二、集合:
1、创建方法:
set() ,frozenset()
s=set('alex li') print(s,type(s))
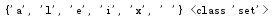
集合可将重复元素去除,数据类型为set
注:集合对象是一组无序排列可hash的值,集合成员可以做字典的键
2、访问集合:由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
3、更新集合:
s.add() s.update() s.remove()
1 s2=set('alvin') 2 s2.add('mm') 3 print(s2) #{'mm', 'l', 'n', 'a', 'i','v'}
1 s2.update('HO')#添加多个元素 2 print(s2) #{'mm', 'l', 'n', 'a', 'i', 'H', 'O', 'v'}
1 s2.remove('l') 2 print(s2) #{'mm', 'n', 'a', 'i', 'H', 'O', 'v'}
del:删除集合本身
4、集合类型操作符:
1、in not in
2、集合等价于不等价(==,!=)
3、子集,超集
1 s=set('alvinyuan') 2 s1=set('alvin') 3 print('v' in s) 4 print(s1<s)#True-------------s1是s的子集
4、联合(|): 联合(union)操作与集合的or操作其实等价的,联合符号有个等价的方法,union()。 并集操作
1 s1=set('alvin') 2 s2=set('yuan') 3 s3=s1|s2 4 print(s3) #{'a', 'l', 'i', 'n', 'y', 'v', 'u'} 5 print(s1.union(s2)) #{'a', 'l', 'i', 'n', 'y', 'v', 'u'}
5、交集(&):与集合and等价,交集符号的等价方法是intersection()
1 s1=set('alvin') 2 s2=set('yuan') 3 s3=s1&s2 4 print(s3)#{'n', 'a'} 5 print(s1.intersection(s2)) #{'n', 'a'}
6、差集(-):等价方法是difference()
1 s1=set('alvin') 2 s2=set('yuan') 3 s3=s1-s2 4 print(s3)#{'v', 'i', 'l'} 5 6 print(s1.difference(s2)) #{'v', 'i', 'l'} 7 8 s4=s2-s1 9 print(s4)#{'y','u'} 10 print(s2.difference(s1)) #{'y','u'}
7、对称差集(^):对称差分是集合的XOR(‘异或’),取得的元素属于s1,s2但不同时属于s1和s2.其等价方法symmetric_difference()
1 s1=set('alvin') 2 s2=set('yuan') 3 s3=s1^s2 4 print(s3) #{'l', 'v', 'y', 'u', 'i'} 5 6 print(s1.symmetric_difference(s2)) #{'l', 'v', 'y', 'u', 'i'}
三、字符串拼接:
1、字符串拼接:
1 v = 'i am %s, my hobby is basketball' %'alex' 2 print(v) #i am alex, my hobby is basketball
******************%s可以接收任何值,序列,但是%d只能接收数字************************
1 v='i am %s, my list is %s' %('alex', [1,2]) 2 print(v) #i am alex, my list is [1, 2]
1 v='My name is %s, i am %d' %('alex', 18) 2 print(v) #My name is alex, i am 18
2、打印小数,浮点数:
1 v1 = "percent %f" % 99.9762343423 #默认保持6位 2 v2 = "percent %.2f" % 99.9762343423 #保持2位 3 print(v1) #percent 99.976234 4 print(v2) #percent 99.98
3、打印百分比:
v="percent %.2f %%" %99.9762343423 print(v) #percent 99.98 %
4、接收字典:
1 v="My name is %(name)s, i am %(age)s" %{"name":"alex","age":18} 2 print(v) #My name is alex, i am 18
四、format字符串格式化:
1 v="My name is {},and I am {}".format("alex",18) 2 print(v) #My name is alex,and I am 18
元组形式
1 v="Hello! {0},My name is {1},and I am {2}".format("Alex","Haword",18) 2 print(v) #Hello! Alex,My name is Haword,and I am 18
1 v="My name is {name}, I am {age}".format(name="Alex",age=18) 2 print(v) #My name is Alex, I am 18