1.查询同一个字段不同种类下的数据:
case语句、round(X,2)表示X保留2位小数、FROM_UNIXTIME(data_time,'%y-%m-%d')格式化时间
SELECT FROM_UNIXTIME(data_time,'%y-%m-%d')AS sj, SUM(ROUND(data_size/1024,2))total, SUM(CASE WHEN data_type='01' THEN ROUND(data_size/1024,2) END) 11, SUM(CASE WHEN data_type='02' THEN ROUND(data_size/1024,2) END) 22, SUM(CASE WHEN data_type='03' THEN ROUND(data_size/1024,2) END)33 FROM t_traffic_data_amount GROUP BY sj ORDER BY sj DESC;
2.查询2张表
left join XX on XX
SELECT t_traffic_device_epolice.qymc, SUM(t_traffic_illegal.wfsl) wfzs, FROM_UNIXTIME(t_traffic_illegal.wfsd,'%y-%m-%d') sj FROM t_traffic_illegal LEFT JOIN t_traffic_device_epolice ON t_traffic_illegal.sbbh=t_traffic_device_epolice.sbbm WHERE t_traffic_device_epolice.qymc IS NOT NULL GROUP BY t_traffic_device_epolice.qymc ORDER BY sj DESC
3.格式化时间
时分格式:
FROM_UNIXTIME( aa, '%H:%i' )
年月日时分秒格式:
FROM_UNIXTIME(t_traffic_congestion .tjsj,'%Y/%m/%d %H%i%s')
4.限制查询结果的条数
查询10条数据:
LIMIT 10
limit 5 ,5
返回从行5开始的五行
5.条件查询
先格式化时间为小时的格式
再判断是否在7点和8点之间
如果在,就输出
t_traffic_point_speed.pjcs
如果不在,就输出0
IFNULL(ROUND(AVG(CASE WHEN FROM_UNIXTIME(t_traffic_point_speed.tjsj,'%H') IN(7,8) THEN t_traffic_point_speed.pjcs END),2),0) clsd_zgf
6.分组
ORDER BY sj DESC #以sj为分组倒序排序
7.1=1,1=2的使用:
在SQL语句组合时用的较多 “where 1=1” 是表示选择全部 “where 1=2”全部不选
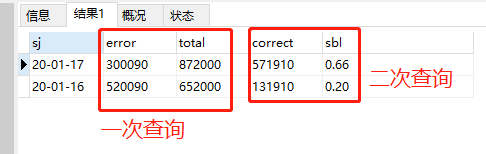
8.针对查询结果进行再次查询或者相加减乘除
首先把首次查询得到的结果当做一个表,再对这个表进行操作
SELECT t.*,( t.total - t.error) correct, #t.* 查询出第一次查询的结果 ROUND((( t.total - t.error)/t.total),2) sbl FROM (SELECT FROM_UNIXTIME(data_time,'%y-%m-%d')AS sj, SUM(CASE WHEN type='total_error' THEN num END) error, SUM(CASE WHEN type='total' THEN num END) total FROM t_traffic_license_plate_recognition GROUP BY sj) t ORDER BY sj DESC;
得到的结果:
9.CONCAT函数用于将两个字符串连接起来,形成一个单一的字符串,各个串直接用,分隔。
CONCAT( b.sbmc, '[', b.sbbm, ']' ) sbmc
#输出 阳关路[0002568989999]
CONCAT( RTrim(b.sbmc), '[', b.sbbm, ']' ) sbmc
#RTrim()函数去掉值右边的空格
LTrim()去掉左边的空格
Trim()去掉串两边的空格
10.正则表达式
select prod_name from products where prod_name REGEXP ‘1000’ order by prod_name; #检索列prod_name包含文本1000的所有行 select prod_name from products where prod_name REGEXP ‘.000’ order by prod_name; #检索列prod_name包含任意字符的所有行(.000表示匹配任意一个字符) 进行OR匹配: select prod_name from products where prod_name REGEXP ‘1000 | 2000’ order by prod_name; #检索列prod_name包含文本1000或2000的所有行,或者两者都满足的数据 匹配几个字符之一: select prod_name from products where prod_name REGEXP ‘[123] Ton’ order by prod_name; #[123]定义一组字符,意思是匹配1或2或3,也可写做[1|2|3] 匹配范围: select prod_name from products where prod_name REGEXP ‘[1-5] Ton’ order by prod_name; #[1-5]定义一个范围,匹配1到5,返回满足的数据 匹配特殊字符:(必须用\为前导) select prod_name from products where prod_name REGEXP ‘\.’ order by prod_name; #检索列prod_name包含 . 的所有行
匹配字符类:
| [:alnum:] | 任意字母和数字(同[a-z A-Z 0-9]) |
| [:alpha:] | 任意字符(同[a-z A-Z]) |
| [:blank:] | 空格和制表(同[\t]) |
| [:contrl:] | ASCII控制字符(ASCII 0到31和127) |
| [:digit:] | 任意数字(同[0-9]) |
| [:graph:] | 与[:print:]相同,但不包括空格 |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同[\f \n \r \t \v]) |
| [:upper:] | 任意大写字母(同[A-Z]) |
| [:xdigit:] | 任意十六进制数字(同[a-f A-F 0-9]) |
匹配多个实例:
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个多1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
select prod_name from products where prod_name REGEXP '\([0-9] sticks?\)' 输出: prod_name TNT(1 stick) TNT(2 sticks) #\([0-9]匹配0-9的数字,sticks?\匹配stick和sticks,(s后的?使s可选,因为?匹配的是0个或1个匹配) select prod_name from products where prod_name REGEXP '[[:digit:]]{4}' 输出: prod_name jetpack 1000 jetpack 2000 #[:digit:]匹配任意数字,所以它是一个集合。{4}确切的要求它前面的字符(任意数字)出现4次,所以[[:digit:]]{4}匹配连载一起的人员4位数字 也可这样实现: select prod_name from products where prod_name REGEXP '[0-9][0-9][0-9][0-9]'
定位符:
| ^ | 文本的开始 |
| $ |
文本的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
elect prod_name from products where prod_name REGEXP '^[0-9\.]' 输出: prod_name .5 ton anvil 1 ton anvil 2 ton anvil #^匹配串的开始。因此^[0-9\.]只在.或任意数字为串的第一个字符时才匹配它们
11.日期和时间处理函数
| AddDate() | 增加一个日期(天、周等) |
| AddTime() | 增加一个时间(时、分等) |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前时间 |
|
Date() |
返回日期时间的日期部分 |
| DateDiff() | 计算两个日期只差 |
| Date_Add() | 高度灵活的日期运算函数 |
| Date_Format() | 返回一个格式化的日期或时间串 |
| Day() | 返回一个日期的天数部分 |
| DayOfWeek() | 对于一个日期,返回对应的星期几 |
| Hour() | 返回一个时间的小时部分 |
| Minute() | 返回一个时间的分钟部分 |
| Month() | 返回一个日期的月份部分 |
| Now() | 返回当前日期和时间 |
| Second() | 返回一个日期的秒部分 |
| Time() | 返回一个日期时间的时间部分 |
| Year() | 返回一个日期的年部分 |
select cust_id,order_num from orders where Date(order_date) = '2021-06-28' #因为order_date存储的时间格式是2021-06-28 00:00:00,如果不用Date函数则无法比较,使用Date函数只会提取出2021-06-28这部分。(Time()函数也是这样,提取后面部分)
12.count()函数:
count(*):对表中行的数目进行计数,所有行都会计数
count(column):对特定列中具有值的行进行计数,忽略NULL值
count(1)效率比count(*)高
13.删除
delete from orders where id = 1001 #删除表中的符合条件的数据 truncate orders #删除orders表中的所有数据
14.更新个插入
update orders set order_id=100 where order_id=1001 #更新一列 update orders set order_id=100,price=5 where order_id=1001 #更新多列 insert into table values() #插入值
15.连接多个表
select order_nama,order_price,order_id from names,prices,ids where names.name=prices.name and prices.id=ids.id and id=5 #3个表联合查数据 select order_nama,order_price,order_id from order_name where(select * from products where id =5) #以子查询为条件
union:自动去掉重复的行,可以手动加上union all
select order_id,order_name,order_p from products where id=5 unoin select user_id,user_name,user_p from user where id=5