另一个很好的演示在这里
SOM
t是训练步
一个输入数据是n维向量

待训练的是一堆节点,这堆节点之间有边连着,通常是排成grid那样的网状结构
一个要训练的节点包含一个n维向量

训练从t=0开始,t=输入数据个数时结束
每步的更新规则是
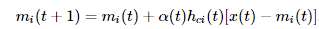
其中a(t)是一个随训练步数衰减的函数,c,i都是训练节点的索引,c是离x(t)最近的节点的索引,hci是节点mc和mi的边距离。也就是说每个训练步选一个输入数据x(t),将离它最近的节点mc向这个输入数据拉扯,这个节点又透过连着的边,带动邻近的节点向这个输入数据移动。
Batch SOM
这样输入数据太多的时候会很慢,改进的方法称为batch som。
方法是在每一步,对每个节点 mj,统计所有选中它为最近邻的输入数据的平均值,记为 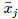 。
。
。再按下式更新每个节点的值。

nj是选了mj做最邻近的输入数据个数,hji是节点mi与节点mj的边距离。可见对于节点mi,它会更新到邻近所有节点mj对应的 的加权平均值。
的加权平均值。
的加权平均值。