第五讲、聚类
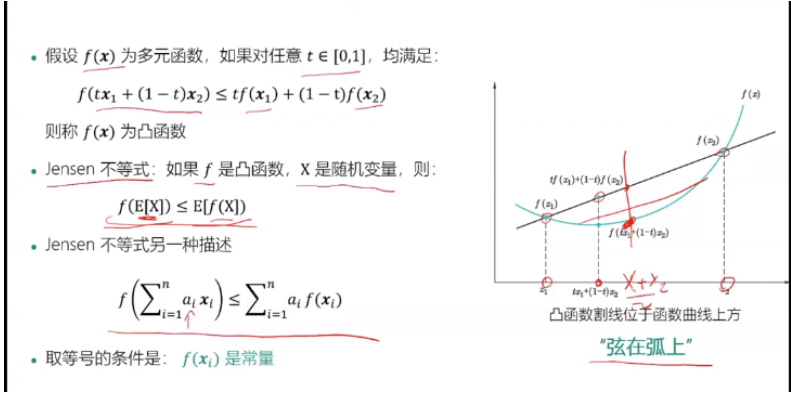
1.数学知识回顾:凸函数与jensen不等式
2.聚类简介 聚类的本质:将数据集中相似的样本进行分组的过程;
每个组称为一个簇(cluster)每个簇的样本对应一个潜在的类别;
样本没有类别标签,一种典型的无监督学习方法;
这些簇满足以下两个条件: 相同簇的样本之间距离较近;
不同簇的样本之间距离较远。
聚类方法:层次聚类、K-Means、谱聚类等。
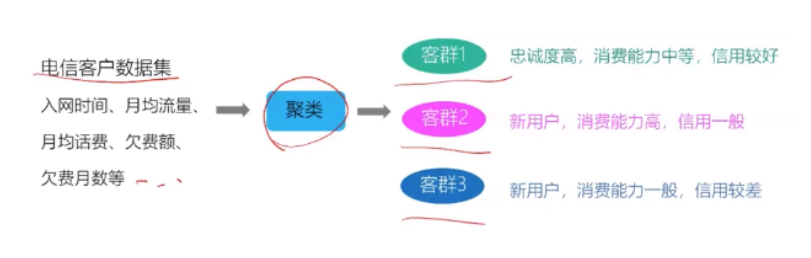
3.举例:客户分群
4.K-Means模型

①模型求解:
交替迭代法:固定c,优化r; 固定r,优化c。
固定c,优化r:

固定r,优化c:

②算法流程
(1).随机选择k个点作为初始中心
(2).Repeat: 将每个样本指派到最近的中心,形成k个类。
重新计算每个类的中心为该类样本均值
(3).直到中心不发生变化
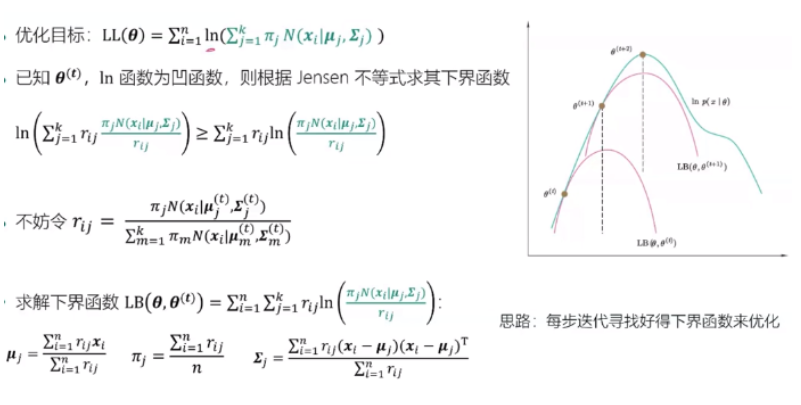
5.高斯混合模型

求解过程: