tcpdump 命令使用
tcpdump命令参数解析

- option 可选参数:能够控制tcpdump命令,比如是否解析域名,将结果输出到文件,或者从文件读包数据,以及打印格式等。
- protocol 协议过滤:能够根据不同的协议进行过滤,常用的已经上面了。
- direction 方向过滤:能够根据数据的流向来进行过滤,也就是src和dst,也可以是两者。
- type 类型过滤:能够根据不同的类型进行过滤。
tcpdump输出结构
22:21:43.500014 IP 10.21.11.47.http > 11.0.85.18.51352: Flags [.], seq 697549179:697550639, ack 612207134, win 501, length 1460: HTTP: HTTP/1.1 200
这是直接不使用参数得到的其中一条输出
- 第一列:代表时间,分别是时分秒毫秒 22:21:43.500014。
- 第二列:代表网络协议 IP。
- 第三列:代表发送的方的地址(IP+port),其中10.21.11.47是IP,而http是端口,在tcpdump中http就代表80端口,所以也就是10.21.11.47.80,后面可以使用-nn参数来关闭转换。
- 第四列:代表数据流向,可以看出是10.21.11.47.http发送数据到11.0.85.18.51352。
- 第五列:代表接收方的地址,格式同第三列,可以看出这次商品是51352。
- 第六列:代表分隔,冒号。
- 第七列:代表数据包的相关内容。包括Flags标识符,seq号,ack号,win窗口大小,数据长度length,通信协议HTTP等。
Flag标识符
- [S]:代表SYN,同步标记,一般是在建立连接时使用,也就是TCP三次握手时使用。
- [.]:代表没有Flags,但是除了SYN包外所有的数据包都有ACK,所以这个标记也可以代表ACK。
- [P]:代表PUSH,推送数据,发送方通过使用PUSH位来通知接收方将所有收到的数据立即提交给服务器进程,而不需要等待额外数据(将缓存填满)而让数据在缓存中停留!这里所说的数据包括与此PUSH包一起传输的数据以及之前就为该进程传输过来的数据(滞留在缓存中的数据)。
- [R]:代表RST,复位标记,一般是异常终止通讯连接,当段到达不用于当前连接时,使用复位标志。换句话说,如果要向主机发送数据包以建立连接,并且没有这样的服务等待在远程主机上回答,则主机将自动拒绝您的请求,然后向您发送回复RST标志置1。这表示远程主机已重置连接。
- [F]:代表FIN,结束标记,带有该标志置位的数据包用来结束一个TCP回话,但对应端口仍处于开放状态,准备接收后续数据,一般用于TCP四次挥手中,需要注意的是,当主机发送FIN标志来关闭连接时,它可能会继续接收数据,直到远程主机也关闭了连接,尽管这仅在特定情况下发生。一旦连接被双方削减,则释放用于连接的每端的缓冲区。
- [U]:代表URG,紧急标记,在数据传输流中,主机正在向远程机器上运行的应用程序发送数据,可以使用紧急指针。如果出现问题,主机需要中止数据传输,并在另一端停止数据处理。在正常情况下,中止信号将在远程机器发送和排队,直到所有先前发送的数据都被处理,但是在这种情况下,需要立即处理中止信号。通过将中止信号的段紧急指针标志设置为“1”,远程机器将不会等待所有排队的数据被处理,然后执行中止。相反,它会给出特定的段优先级,立即处理它,并停止进一步的数据处理。
数据包内容
- seq:代表序列号,697549179:697550639代表从697549179到697549179:697550639。
- ack:确认序列号,一般为seq+1,但是如果使用tcpdump命令得到的输出可能会出现ack只是相对增量,而不是seq+1,这里使用-S的参数使用绝对确认序列号。
- win:窗口大小,代表对方最多还可以发送501个字节。
- length:代表发送的数据包的大小。
过滤规则
按照protocol协议过滤
- proctol可使用协议有:tcp, udp, icmp, http, ip, ip6, arp, rarp, atalk, aarp, decnet, sca, lat, mopdl, moprc, iso, stp, ipx, or netbeui。所以可以直接使用这些协议进行过滤。
# 过滤出只有ip协议的
tcpdump ip
# 过滤出只有tcp和udp
tcpdump 'tcp or udp'
# 如果想过滤出同时多个,比如tcp中的ip6
tcpdump 'tcp and ip6'
按照direction方向过滤
- direction方向只有两个,那就是src和dst。可以使用这两个方向进行过滤。
# 过滤出发送方是 11.0.85.18
tcpdump src 11.0.85.18
# 过滤出接收方是 11.0.85.18
tcpdump dst 11.0.85.18
# 过滤出发送方或者接收方是 11.0.85.18
tcpdump 'src 11.0.85.18 or dst 11.0.85.18'
# 过滤出发送方是 11.0.85.18,接收方是 11.0.85.19
tcpdump 'src 11.0.85.18 and dst 11.0.85.19'
按照type类型过滤
- type类型只有host、port、net和portrang,可以使用这四种类型进行过滤。
# 过滤出IP地址是 11.0.85.18
tcpdump host 11.0.85.18
# 过滤出端口是 8080
tcpdump port 8080
# 过滤出网段是 192.168.10.0/24
tcpdump net 192.168.10.0/24
# 过滤出端口范围是 8080~8090
tcpdump portrang 8080-8090
# 过滤出源IP地址为 11.0.85.18 端口为80或者443,注意http可以代表80商品,https可以代表443端口
tcpdump 'src host 11.0.85.18 and (port http or https)'
可选参数
不解析域名
- -n:不把IP转换成域名,直接显示IP,避免了DNS lookup的过程,提高解析速度
- -nn:不把协议和商品转换为名称。
- -N:不打印host的域名部分,如果设置了该选项,tcpdump 将会打印'nic' 而不是 'nic.ddn.mil'。
数据包生成到文件
- -w:能够将抓包抓到的数据生成到文件中去,一般生成到一个以.pcap为后缀的文件中,再使用像wireshark的软件来解析。
# 将数据输出到文件 tcp.pcap中
tcpdump tcp -w tcp.pcap
从文件中解析出数据包
- -r:能够从文件中解析数据,也可以对文件中数据包进行过滤解析。
# 从 tcp.pcap 中过滤出ip的数据包
tcpdump ip -r tcp.pcap
输出内容的详细程序
- -v:产生详细的输出。比如包的TTL,id标识,数据包长度,以及IP包的一些选项。同时它还会打开一些附加的包完整性检测,比如对IP或ICMP包头部的校验和。
- -vv:产生比-v更详细的输出。比如NFS回应包中的附加域将会被打印, SMB数据包也会被完全解码。
- -vvv:产生比-vv更详细的输出。比如 telent 时所使用的SB, SE 选项将会被打印, 如果telnet同时使用的是图形界面,其相应的图形选项将会以16进制的方式打印出来。
时间显示格式
- -t:在每行的输出中不输出时间。
- -tt:在每行的输出中会输出时间戳。
- -ttt:输出每两行打印的时间间隔(以毫秒为单位)。
- -tttt:在每行打印的时间戳之前添加日期的打印。
数据包头部的显示格式
- -x:以16进制的形式打印每个包的头部数据(但不包括数据链路层的头部)。
- -xx:以16进制的形式打印每个包的头部数据(包括数据链路层的头部)。
- -X:以16进制和 ASCII码形式打印出每个包的数据(但不包括连接层的头部),这在分析一些新协议的数据包很方便。
- -XX:以16进制和 ASCII码形式打印出每个包的数据(包括连接层的头部),这在分析一些新协议的数据包很方便。
过滤网卡的数据包
- -i:指定要过滤的网卡接口,如果要查看所有网卡,可以 -i any。
过滤流向的数据包
- -Q:选择是入方向还是出方向的数据包,可选项有:in, out, inout,也可以使用 --direction=[direction] 。
输出内容控制
- -D : 显示所有可用网络接口的列表。
- -e : 每行的打印输出中将包括数据包的数据链路层头部信息。
- -E : 揭秘IPSEC数据-L :列出指定网络接口所支持的数据链路层的类型后退出。
- -Z:后接用户名,在抓包时会受到权限的限制。如果以root用户启动tcpdump,tcpdump将会有超级用户权限。
- -d:打印出易读的包匹配码。
- -dd:以C语言的形式打印出包匹配码。
- -ddd:以十进制数的形式打印出包匹配码。
其他常用参数
- -A:以ASCII码方式显示每一个数据包(不显示链路层头部信息)。在抓取包含网页数据的数据包时, 可方便查看数据。
- -l : 基于行的输出,便于你保存查看,或者交给其它工具分析。
- -q : 简洁地打印输出。即打印很少的协议相关信息, 从而输出行都比较简短。
- -c : 捕获 count 个包 tcpdump 就退出。
- -s : tcpdump 默认只会截取前 96 字节的内容,要想截取所有的报文内容,可以使用-s number, number 就是你要截取的报文字节数,如果是 0 的话,表示截取报文全部内容。
- -S : 使用绝对序列号,而不是相对序列号,前面说过ack有时就会是相对序列号,可以使用-S,来使用绝对序列号。
- -C:file-size,tcpdump 在把原始数据包直接保存到文件中之前, 检查此文件大小是否超过file-size.。如果超过了, 将关闭此文件,另创一个文件继续用于原始数据包的记录。新创建的文件名与-w 选项指定的文件名一致, 但文件名后多了一个数字。该数字会从1开始随着新创建文件的增多而增加。file-size的单位是百万字节。
- -F:使用file 文件作为过滤条件表达式的输入, 命令行上的输入将被忽略。
规则组合运算
逻辑运算符
- and:且运算符,也可以表示为 &&,表示全部条件都要满足。
- or:或者运算符,也可以表示为 ||,表示任何一条件满足即可。
- not:否定运算符,也可以表示为 !,表示对原来的否定,真变假,假变真。
- ():括号,优先运算,不过在使用时要用引号包起来,因为括号是shell的特殊符号。
条件运算符
- =:判断二者相等。
- ==:判断二者相等。
- !=:判断二者不相等。
关键字
- if:表示网卡接口名。
- proc:表示进程名。
- pid:表示进程 id。
- svc:表示 service class。
- dir:表示方向,in 和 out。
- eproc:表示 effective process name。
- epid:表示 effective process ID
应用
# 过滤出源IP地址为 11.0.85.18 端口为80或者443,注意http可以代表80商品,https可以代表443端口
tcpdump 'src host 11.0.85.18 and (port http or https)'
# 过滤来自进程名为 a 发出的流经 en0 网卡的数据包,或者不经过 en1 的流入方向数据包
tcpdump '(if = en0 and proc = a) or (dir = in and if = en1)'
特殊规则过滤
基于协议头部过滤
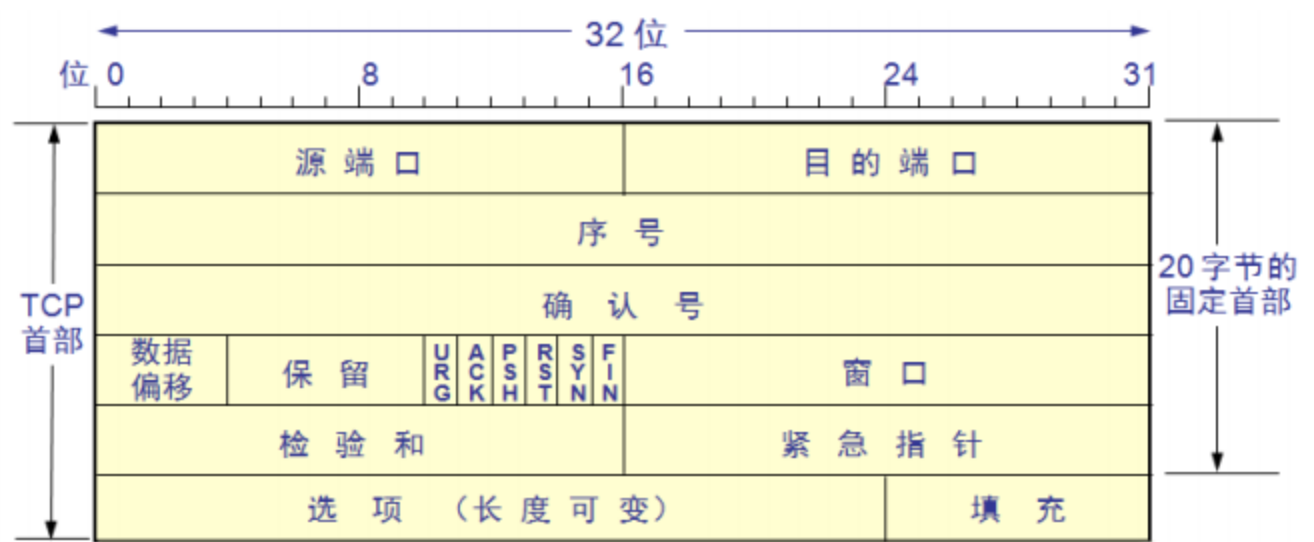
- tcpdump运行使用数据包的标志位进行过滤,语法
- proto [expr:size]
- proto:是常用的协议,比如ip,tcp,arp,udp,icmp等。
- expr:可以是数值,也可以是以一个表达式,表示与指定协议开始处的字节偏移量。
- size:是可以选的,表示从字节偏移量开始截取多少字节。
- tcpfalg:表示一个常量13,它代表着与指定协议开头相关的字节偏移量,也就是标记位,也就是它能够直接找到标记位在TCP头部的位置。tcp[tcpflags] = tcp[13]。
- tcp-fin, tcp-syn, tcp-rst, tcp-push, tcp-ack, tcp-urg 这些同样可以理解为别名常量,分别代表 1,2,4,8,16,32,64。这些都是标记位处的字节的二进制数转换为十进制数的大小。比如tcp-fin 就是 (00000001)2,tcp-sync就是(00000010)2。
- 当tcp[tcpflags] == tcp-syn 时,这个包就是syn包。
- 当tcp[tcpflags] == tcp-fin 时,这个包就是fin包。
- 其他的类似
# 抓取syn包的方式
# 使用数字
tcpdump 'tcp[13]&2 != 0' # 最好不要写成 tcpdump 'tcp[13] == 2',因为syn包也有可能包含其他标记位,比如 ack
# 使用常量,也可以混用,就不给例子了
tcpdump 'tcp[tcpflags]&tcp-syn != 0'
# 抓取syn包和ack包
tcpdump 'tcp[tcpflags]&tcp-syn != 0 and tcp[tcpflags]&tcp-ack != 0'
# 或者
tcpdump 'tcp[tcpflags]&(tcp-syn|tcp-ack) == (tcp-syn|tcp-ack)'
# 或者 tcp-sync|tcp-ack = 18
tcpdump 'tcp[tcpflags]&18 == 18'
# 抓取syn包或ack包
tcpdump 'tcp[tcpflags]&tcp-syn != 0 or tcp[tcpflags]&tcp-ack != 0'
# 或者
tcpdump 'tcp[tcpflags]&(tcp-syn|tcp-ack) != 0'
基于数据包大小过滤
# 大于 32 字节
tcpdump greater 32
# 小于 128 字节
tcpdump less 128
基于mac地址过滤
tcpdump ether host [mac_addr]
基于网关过滤
tcpdump gateway 10.8.0.0
基于广播或者多播过滤
# 广播
tcpdump broadcast
# 多播
tcpdump muticast
# 按以太广播
tcpdump ehter broadcast
# 按以太多播
tcpdump ether multicast
应用
- 抓取HTTP GET请求的数据包。
# 抓取HTTP GET请求数据包
tcpdump -s 0 -A -vvv 'tcp[((tcp[12:1] & 0xf0) >> 2):4] == 0x47455420'
- 看起来挺复杂,进行一步步拆解,tcp[12:1]是从第12个字节开始读取1个字节,可以看一下上面的TCP头部图,可以知道读出来的是数据偏移,数据偏移就是代表TCP头部长度的,它是以4字节为单位的,一共4位。所以读出了数据偏移后,然后数据偏移只有4位,但一个字节有8位,所以只取前4位就可以了。&0xf0就是将后四位置为0,应该再右移4位就能够正好得到数据偏移了,但是因为数据偏移是以4字节为单位的,所以需要再乘以4,也就是需要再左移2位,那么两个一合并就是右移2位了。因此就得到了tcp中body的开始偏移,再取前四位,就是HTTP的协议,而GET的16进制就是0x474554,因为GET是3个字符,最后会多一个空格,所以合起来就是0x47455420。就得到了这个表达式。
抓包实战
抓取HTTP 相关请求
# 从 HTTP 请求头中提取 HTTP 用户代理:
tcpdump -nn -A -s 1500 -l | grep "User-Agent:"
# 通过 egrep 可以同时提取用户代理和主机名(或其他头文件)
tcpdump -nn -A -s1500 -l | egrep -i "r-Agent:|Host:"
# 抓取 GET 请求包
tcpdump -s 0 -A -vv 'tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x47455420'
# 或者
tcpdump -vvAls 0 | grep 'GET'
# 抓取 POST 请求包, 注意:该方法不能保证抓取到 HTTP POST 有效数据流量,因为一个 POST 请求会被分割为多个 TCP 数据包。
tcpdump -s 0 -A -vv 'tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x504f5354'
# 或者
tcpdump -vvAls 0 | grep 'POST'
# 从 HTTP POST 请求中提取密码和主机名
tcpdump -s 0 -A -n -l | egrep -i "POST /|pwd=|passwd=|password=|Host:"
# 提取 HTTP 请求的主机名和路径
tcpdump -s 0 -v -n -l | egrep -i "POST /|GET /|Host:"
# 抓取 80 端口的 HTTP 有效数据包,排除 TCP 连接建立过程的数据包(SYN / FIN / ACK)
tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
找出发包数最多的IP
# 找出200个包内发包最多的前10个 IP
tcpdump -nnn -t -c 200 | cut -f 1,2,3,4 -d '.' | sort | uniq -c | sort -nr | head -n 10
- cut:cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
- -b:以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d:自定义分隔符,默认为制表符。
- -f:与-d一起使用,指定显示哪个区域。
- -n:取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除。
- sort:sort 可针对文本文件的内容,以行为单位来排序。
- -b: 忽略每行前面开始出的空格字符。
- -c:检查文件是否已经按照顺序排序。
- -d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f:排序时,将小写字母视为大写字母。
- -i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m:将几个排序好的文件进行合并。
- -M:将前面3个字母依照月份的缩写进行排序。
- -n:依照数值的大小排序。
- -u:意味着是唯一的(unique),输出的结果是去完重了的。
- -o:后接<输出文件> 将排序后的结果存入指定的文件。
- -r:以相反的顺序来排序。
- -t:后接<分隔字符> 指定排序时所用的栏位分隔字符。
- +:后接<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- uniq:uniq 可检查文本文件中重复出现的行列。
- -c:或--count 在每列旁边显示该行重复出现的次数。
- -d:或--repeated 仅显示重复出现的行列。
- -f:<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
- -s:<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
- -u:或--unique 仅显示出一次的行列。
- -w:<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
抓取DNS请求和响应
# DNS 的默认端口是 53
tcpdump -i any -s0 port 53
切割pcap文件
# 当抓取大量数据并写入文件时,可以自动切割为多个大小相同的文件。例如,下面的命令表示每 3600 秒创建一个新文件 capture-(hour).pcap,每个文件大小不超过 200*1000000 字节
tcpdump -w /tmp/capture-%H.pcap -G 3600 -C 200