想做一个程序,实现的功能就是通过代码抓取某个公众号的最近三天的历史文章。
学习到了很多关于爬虫的小知识,比如怎么用request库,怎么用lxml,怎么用正则抓取想要部分的内容,怎么用beautiful soup之类之类的。可以说是基本实现了想要的功能。只是,存在了一个问题就是如果请求太多次就会爆验证码啊~~~像这样->
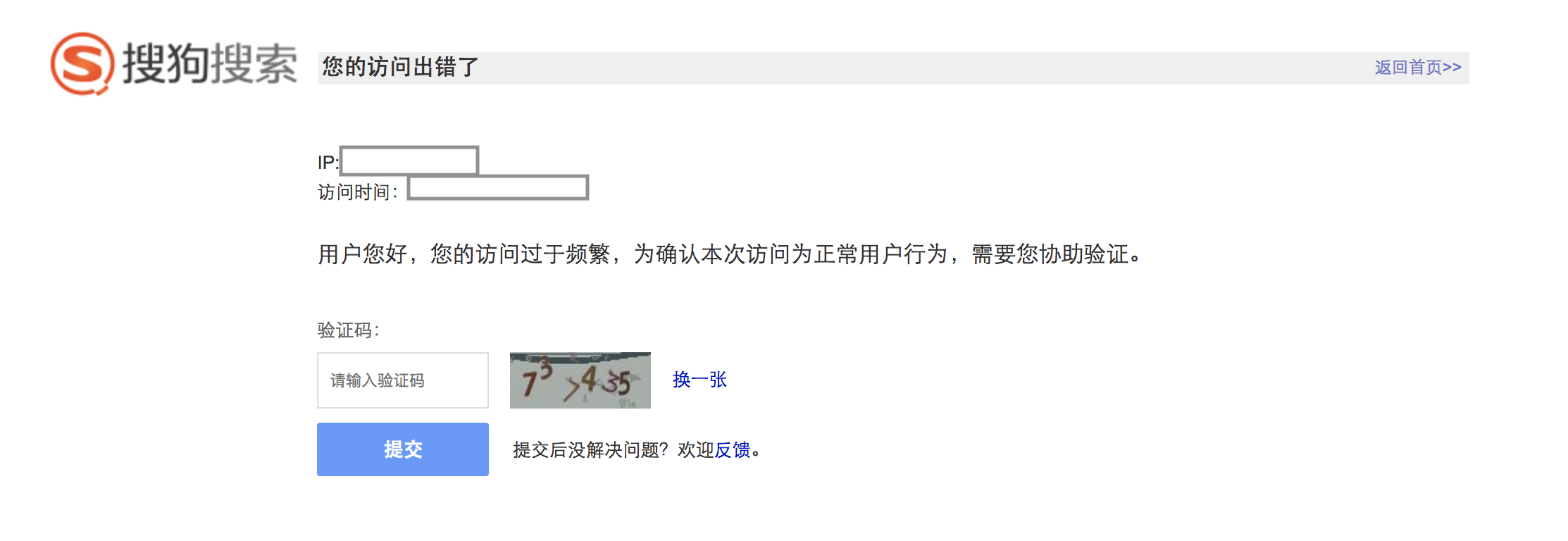
用程序试了一下,大概调用28次每次间隔30秒到1分钟就会出现验证码界面。
想着怎么解决这个问题,正好之前有学tensorflow,看可不可以训练一个可以自动识别验证码的程序。
在网上大致的搜了搜,有很老的用selenium和tessaract一起识别ocr的例子。看了一下代码主要是截屏之后获取验证码图片的部分,把那个图片放到tessaract的库里识别。
嗯,试试看好不好使吧...通过验证对于简单横平竖直无任何干扰的数字字母准确率可以很高可是如果是扭曲的验证码加干扰识别率特别低,所以果断放弃。
接着在网上找,找到了最近用tensorflow识别验证码的例子。看上去还不错
http://blog.topspeedsnail.com/archives/10858
大致原理就是应用CNN经过三次卷积操作+max pooling 最后一次全联接操作,通过softmax算出logit和loss。输入采用captcha库来自动生成验证码。
生成效果像这样:
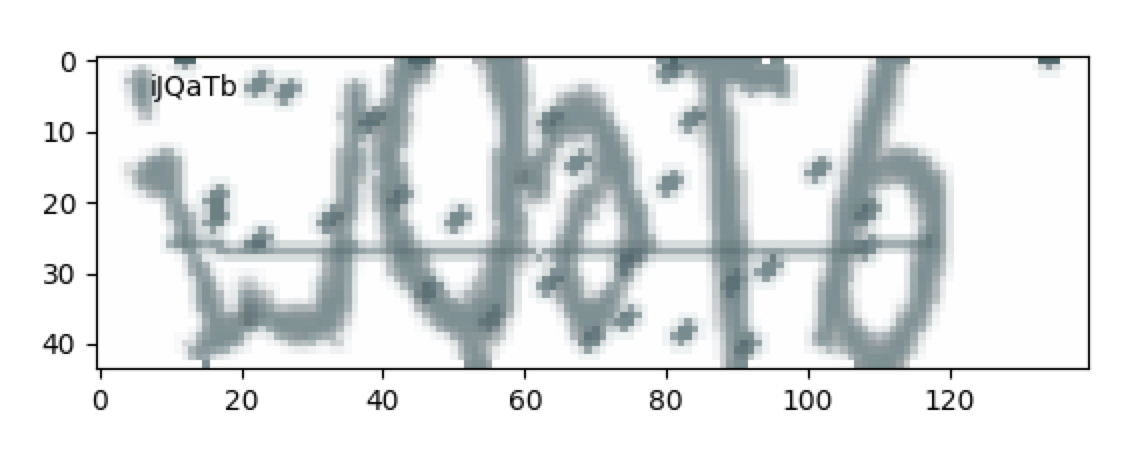
心想, 嗯这个输入和搜狗的验证码也是比较像了,用这个生成器生成的验证码来训练应该是差不多能好使吧。刚好谷歌提供了供机器学习的云平台。那就拿到云上跑一跑呗。反正有免费的300刀不用白不用。
核心代码如下(转载之以上那个链接中的代码):
1 x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1]) 2 # 3 conv layer 3 w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32])) 4 b_c1 = tf.Variable(b_alpha * tf.random_normal([32])) 5 conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1)) 6 conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 7 conv1 = tf.nn.dropout(conv1, keep_prob) 8 9 w_c2 = tf.Variable(w_alpha * tf.random_normal([3, 3, 32, 64])) 10 b_c2 = tf.Variable(b_alpha * tf.random_normal([64])) 11 conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2)) 12 conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 13 conv2 = tf.nn.dropout(conv2, keep_prob) 14 15 w_c3 = tf.Variable(w_alpha * tf.random_normal([3, 3, 64, 64])) 16 b_c3 = tf.Variable(b_alpha * tf.random_normal([64])) 17 conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3)) 18 conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 19 conv3 = tf.nn.dropout(conv3, keep_prob) 20 21 # Fully connected layer 22 w_d = tf.Variable(w_alpha * tf.random_normal([6 * 18 * 64, 1024])) 23 b_d = tf.Variable(b_alpha * tf.random_normal([1024])) 24 dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]]) 25 dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d)) 26 dense = tf.nn.dropout(dense, keep_prob) 27 28 w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN])) 29 b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN])) 30 out = tf.add(tf.matmul(dense, w_out), b_out) 31 # out = tf.nn.softmax(out) 32 return out
那个博主才用的是60*160的图片, 由于搜狗验证码大小是44 * 140,所以做了相应修改,直接让验证码生成器生成和搜狗验证码图片同样大小的图片。
同样原代码训练到准确率达到50%就停止了,我做了一下修改让程序准确率达到95%。

整整跑了一天8小时啊啊啊啊,好不容易跑出来的参数兴奋的想要验证一下对不对。
结果很是呵呵。。。几乎一个验证都识别不出来,虽说用验证码生成器生成的去验证可以达到几近全对的准确率。
所以结论就是拿这样的数据集训练而拿这样的数据去验证 , 根本就是驴唇不对马嘴。好失落,不过受教了~~~
, 根本就是驴唇不对马嘴。好失落,不过受教了~~~
况且想了一下从一开始想要拿tensorflow去识别验证码的方式就是行不通的。 因为一旦出现了验证码页面,则搜狗页面会判断疑似不像人,那么在之后的请求中,验证码页面只能出现的越来越频繁。而且在怎么验证码识别也不能达到100%正确不是?
嗯,不过之前的用tensorflow训练的方法是6个数字一起预测, 如果改进的话是不是可以单个预测并且预测验证码长度。如同之前做过的识别街边房子的房号一样。
代码大致是这样的:
1 @staticmethod 2 def logits(image_batch, drop_rate): 3 patch_size = 5 4 num_channels = 3 5 depth = 16 6 num_hidden = 64 7 num_length_label = 7 8 num_digit_label = 11 9 image_size = 64 10 # variable 11 layer1_weights = tf.Variable(tf.truncated_normal([patch_size, patch_size, num_channels, depth], stddev=0.1)) 12 layer1_biases = tf.Variable(tf.zeros([depth])) 13 layer2_weights = tf.Variable(tf.truncated_normal([patch_size, patch_size, depth, depth], stddev=0.1)) 14 layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth])) 15 layer3_weights = tf.Variable( 16 tf.truncated_normal([image_size // 4 * image_size // 4 * depth, num_hidden], stddev=0.1)) 17 layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden])) 18 length_weights = tf.Variable(tf.truncated_normal([num_hidden, num_length_label], stddev=0.1)) 19 length_biases = tf.Variable(tf.constant(1.0, shape=[num_length_label])) 20 digit1_weights = tf.Variable(tf.truncated_normal([num_hidden, num_digit_label], stddev=0.1)) 21 digit1_biases = tf.Variable(tf.constant(1.0, shape=[num_digit_label])) 22 digit2_weights = tf.Variable(tf.truncated_normal([num_hidden, num_digit_label], stddev=0.1)) 23 digit2_biases = tf.Variable(tf.constant(1.0, shape=[num_digit_label])) 24 digit3_weights = tf.Variable(tf.truncated_normal([num_hidden, num_digit_label], stddev=0.1)) 25 digit3_biases = tf.Variable(tf.constant(1.0, shape=[num_digit_label])) 26 digit4_weights = tf.Variable(tf.truncated_normal([num_hidden, num_digit_label], stddev=0.1)) 27 digit4_biases = tf.Variable(tf.constant(1.0, shape=[num_digit_label])) 28 digit5_weights = tf.Variable(tf.truncated_normal([num_hidden, num_digit_label], stddev=0.1)) 29 digit5_biases = tf.Variable(tf.constant(1.0, shape=[num_digit_label])) 30 31 conv1 = tf.nn.conv2d(image_batch, layer1_weights, [1, 1, 1, 1], padding='SAME') 32 hidden1 = tf.nn.relu(conv1 + layer1_biases) 33 pool1 = tf.nn.max_pool( 34 hidden1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 35 conv = tf.nn.conv2d(pool1, layer2_weights, [1, 1, 1, 1], padding='SAME') 36 hidden2 = tf.nn.relu(conv + layer2_biases) 37 pool = tf.nn.max_pool( 38 hidden2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 39 shape = pool.get_shape().as_list() 40 reshape = tf.reshape(pool, [shape[0], shape[1] * shape[2] * shape[3]]) 41 hidden = tf.nn.relu(tf.matmul(reshape, layer3_weights) + layer3_biases) 42 43 length_logits = tf.matmul(hidden, length_weights) + length_biases 44 digit1_logits = tf.matmul(hidden, digit1_weights) + digit1_biases 45 digit2_logits = tf.matmul(hidden, digit2_weights) + digit2_biases 46 digit3_logits = tf.matmul(hidden, digit3_weights) + digit3_biases 47 digit4_logits = tf.matmul(hidden, digit4_weights) + digit4_biases 48 digit5_logits = tf.matmul(hidden, digit5_weights) + digit5_biases 49 50 length_logits, digit_logits = length_logits, tf.stack([digit1_logits, digit2_logits, digit3_logits, 51 digit4_logits, digit5_logits], axis=1) 52 53 return length_logits, digit_logits
就是每一个都分开训练,最后跑的时候得到一组loss。这样训练可能更快一些吧~并且灵活度可能更高一些。
至此拿deep learning识别验证码就告一段落吧。可以说是虽败犹荣吧, 嗯。以上。