1.outputFormat接口实现类

2.自定义outputFormat
步骤:
1). 定义一个类继承FileOutputFormat
2). 定义一个类继承RecordWrite,重写write方法
3. 案例
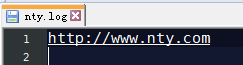
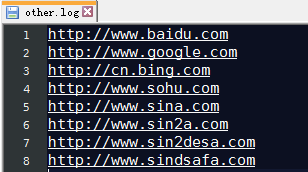
有一个log文件,将包含nty的输出到nty.log文件,其他的输出到other.log
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.nty.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
自定义类继承FileOutputFormat
package com.nty.outputFormat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * author nty * date time 2018-12-12 19:28 */ public class FilterOutputFormat extends FileOutputFormat<LongWritable, Text> { @Override public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { FilterRecordWrite frw = new FilterRecordWrite(); frw.init(job); return frw; } }
自定义RecordWriter,重写write
package com.nty.outputFormat; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * author nty * date time 2018-12-12 19:29 */ public class FilterRecordWrite extends RecordWriter<LongWritable, Text> { private FSDataOutputStream nty; private FSDataOutputStream other; //将job通过参数传递过来 public void init(TaskAttemptContext job) throws IOException { String outDir = job.getConfiguration().get(FileOutputFormat.OUTDIR); FileSystem fileSystem = FileSystem.get(job.getConfiguration()); nty = fileSystem.create(new Path(outDir + "/nty.log")); other = fileSystem.create(new Path(outDir + "/other.log")); } @Override public void write(LongWritable key, Text value) throws IOException, InterruptedException { String address = value.toString() + " "; if(address.contains("nty")) { nty.write(address.getBytes()); } else { other.write(address.getBytes()); } } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { //关流 IOUtils.closeStream(nty); IOUtils.closeStream(other); } }
Driver类设置
package com.nty.outputFormat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * author nty * date time 2018-12-12 19:29 */ public class FilterDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(FilterDriver.class); job.setOutputFormatClass(FilterOutputFormat.class); FileInputFormat.setInputPaths(job, new Path("d:\Hadoop_test")); FileOutputFormat.setOutputPath(job, new Path("d:\Hadoop_test_out")); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
输出结果