1.MapReduce的定义

2.MapReduce的优缺点
优点


缺点

3.MapReduce的核心思想
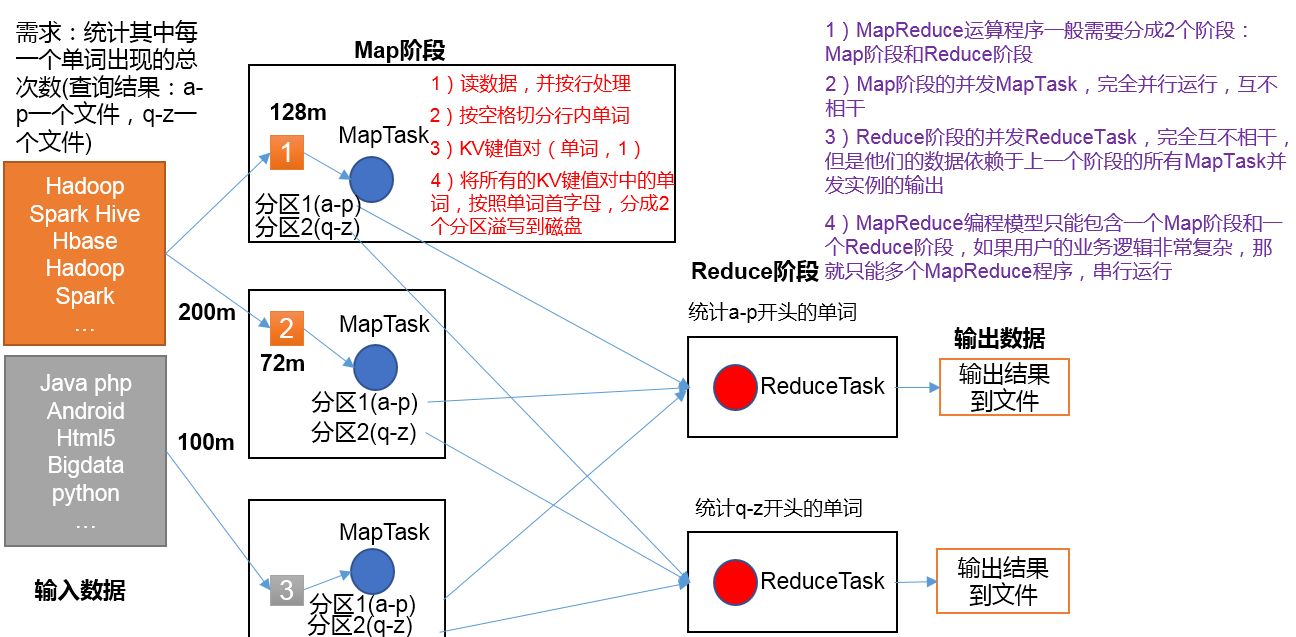
4.MapReduce进程

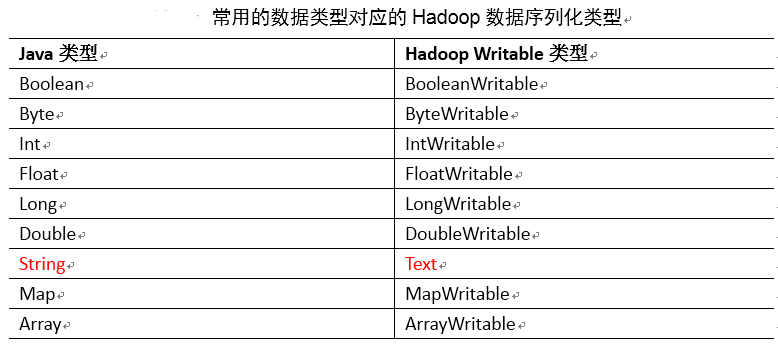
5.常用数据序列化类型
6.MapReduce的编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver


7.WordCount简单操作
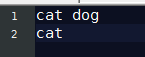
需求:在给定的文本文件中统计输出每一个单词出现的总次数
如一个类似这样的文件
Mapper类
package com.nty.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * author nty * date time 2018-12-07 16:33 */ //Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 四个泛型分别表示,输入Key类型,输入Value类型,输出Key类型,输出Value类型 public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> { //定义成员变量,节省堆内存 private Text key = new Text(); private IntWritable value = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); for (String word : words) { this.key.set(word); context.write(this.key,this.value); } } }
Reducer类
package com.nty.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * author nty * date time 2018-12-07 16:34 */ //Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> 四个泛型分别为,输入Key类型,输入Value类型,输出Key类型,输出Value类型 public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private int sum; private IntWritable total = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { sum = 0; for (IntWritable value : values) { sum += value.get(); } this.total.set(sum); context.write(key, this.total); } }
Driver类
package com.nty.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * author nty * date time 2018-12-07 16:35 */ public class WcDriver { public static void main(String[] args) throws Exception { //1.获取配置信息和任务 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); //2.设置加载路径 job.setJarByClass(WcDriver.class); //3.设置Mapper和Reducer job.setMapperClass(WcMapper.class); job.setReducerClass(WcReducer.class); //4.设置map和reduce的输入输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //5.设置输入和输出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); //6 提交 boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
main方法的args

输出结果


