最大熵模型推导
1. 似然函数
概率和似然的区别:概率是已知参数的条件下预测未知事情发生的概率,而似然性是已知事情发生的前提下估计模型的参数.我们通常都是将似然函数取最大值时的参数作为模型的参数.
那么为何要取似然函数取最大值的参数作为模型的参数?我们基于这样的假设:对于已经发生的事情,在同样条件下再次发生的概率就会很大.假如模型的参数固定,然后用这个参数固定的模型来预测已经发生的事情,这时我们得到的概率不一定很大,并且不同的参数得到概率是不一样的,但是事实上这个事情已经发生了,也就是说发生这个事情的概率为1,此时我们就需要让模型对这个事情的预测概率越大越好.即概率越大其发生的可能性越大,也就越符合已经发生的事情!
最大似然估计也是统计学中经验风险最小化的例子.计算极大似然估计的方法:首先写出似然函数,对似然函数取对数并整理,然后求导数,最后解似然方程.其中似然函数常用概率密度函数.

3 最大熵模型原理(对偶函数的极大化):
最大熵模型的依据是最大熵原理,最大熵原理是:在没用更多信息的前提下,使用等概率的方法会使得模型的效果最好.最大熵模型基本围绕下面两点而展开:
1)保证模型满足已知的所有约束.
2)在第一点的基础上使得模型的熵最大.
最大熵模型的分析过程:
1)从训练集合中抽取若干特征.
2) 对于抽取出的每个特征i,我们使用特征函数 来表示.当特征i符合某一条件时,我们将特征函数设置一个值1,否则设置0.
来表示.当特征i符合某一条件时,我们将特征函数设置一个值1,否则设置0.
3)找出特征函数的约束条件.为了让模型拟合训练数据,我们需要让:

首先我们需要将上述问题转化成无条件的最优化问题,这时需要用Lagrange定理,但是上述问题并不满足Lagrange定理,于是我们先将最大化问题转化成最小化问题:

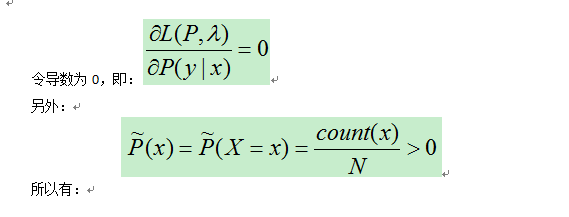

这就是我们所需要的最大熵模型下的概率估计,实际上,对偶问题的极大化等价于最大熵模型的极大似然估计.至此,我们已经得到了最大熵模型的目标估计,而模型中的最优参数则是对偶问题最大时的参数.



于是有:
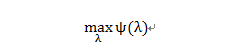
上式并没有一个显式的解析解,因此需要借助于数值的方法.由于其是一个光滑的凸函数,所以可以求解的方法很多.可以使用的方法有:
1)通用迭代尺度法(GIS: Generalized Iterative Scaling)
2)改进的迭代尺度法(IIS: Improved Iterative Scaling)
3)梯度下降算法
4)拟牛顿法(牛顿法)
其中,前两个方法是专门为最大熵模型而设计的,后两种方法为通用的算法.
6. 总结:
此文有较多的公式化简过程,看起来很复杂.总的来说,最大熵模型是个相对简单的算法,简单来说,它主要就是约束条件+最大化条件熵.其中约束条件主要是提取训练集的特征,得到每个特征的特征函数,然后将特征函数关于经验联合分布的期望近似为特征函数关于模型的联合分布期望,这样对每个特征函数都到一个约束条件,另外,还要附加上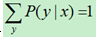 ,然后在满足约束条件的基础上求最大化条件熵
,然后在满足约束条件的基础上求最大化条件熵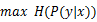 .
.