1、flume的外部结构:
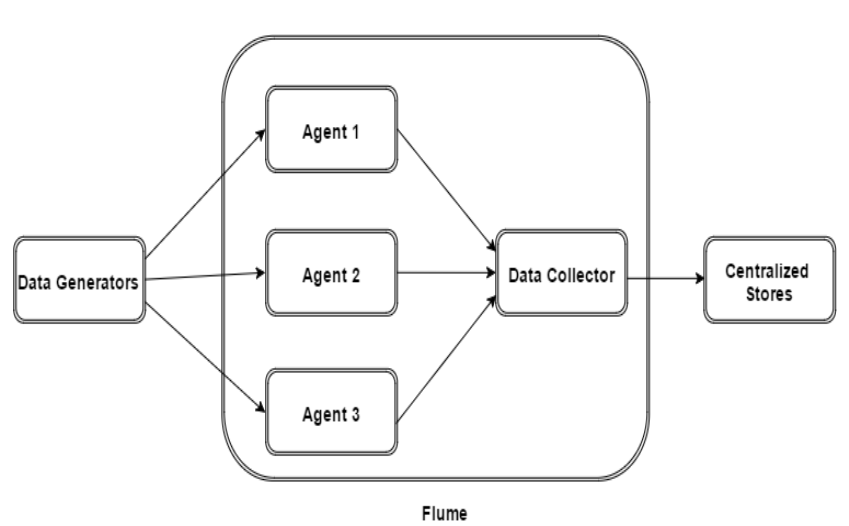
如上图所示,数据发生器(如:facebook,twitter)产生的数据被被单个的运行在数据发生器所在服务器上的agent所收集,之后数据收容器从各个agent上汇集数据并将采集到的数据存入到HDFS或者HBase中。
2. Flume 事件
事件作为Flume内部数据传输的最基本单元.它是由一个转载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是HDFS/HBase)和一个可选头部构成.
典型的Flume 事件如下面结构所示:

我们在将event在私人定制插件时比如:flume-hbase-sink插件是,获取的就是event然后对其解析,并依据情况做过滤等,然后在传输给HBase或者HDFS。
3.Flume Agent
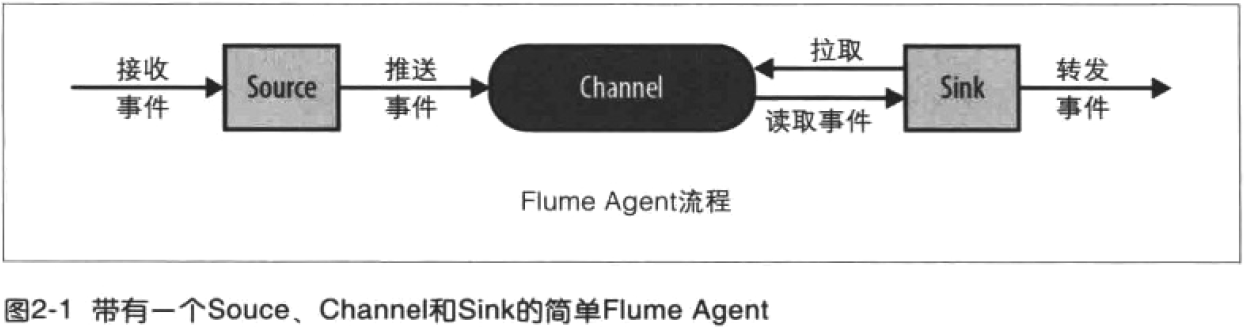
我们在了解了Flume的外部结构之后,知道了Flume内部有一个或者多个Agent,然而对于每一个Agent来说,它就是一共独立的守护进程(JVM),它从客户端哪儿接收收集,或者从其他的 Agent哪儿接收,然后迅速的将获取的数据传给下一个目的节点sink,或者agent. 如下图所示flume的基本模型

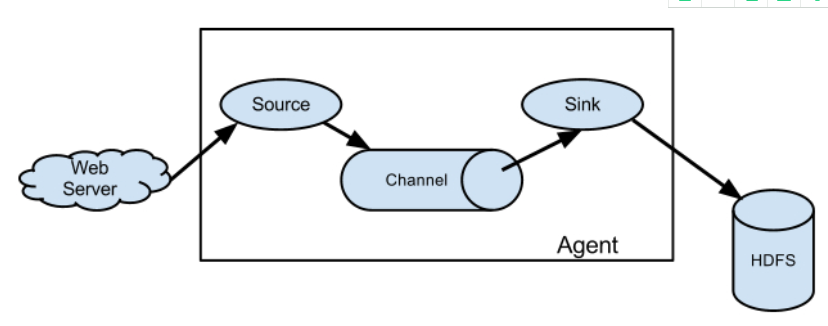
每个flume agent包含三个主要组件:source、channel、sink。
Source:从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%等。是从一些其他产生数据的应用中接收数据的活跃组件,有自己产生数据的source,不过这些source通常用于测试目的,source可以监听一个或者多个网络端口,用于接收数据或者可以从本地文件系统读取数据,每个source必须至少连接一个channel,基于一些标准,一个source可以写入几个channel,复制事件到所有或某些channel。
channal:channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等。
一般来说,channel是被动组件(虽然它们可以为了清理或者垃圾回收运行自己的线程),缓冲agent已经接收,但尚未写出到另一个agent或者存储系统的数据,channel的行为像队列,source写入到它们,sink从它们中读取,多个source可以安全地写入到相同channel,并且多个sink可以从相同的channel进行读取,可是一个sink只能从一个channel读取,如果多个sink从相同的channel读取,它可以保证只有一个sink将会从channel读取一个指定特定的事件。
sink: sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase。Sink连续轮询各自的channel来读取和删除事件,sink将事件推送到下一阶段,或者最终目的地。一旦在下一阶段或其目的地中数据是安全的,sink通过事务提交通知channel,可以从channel中删除这些事件。
flume本身不限制agent中source、channel和sink的数量,因此flume source可以接收事件,并可以通过配置将事件复制到多个目的地,这使得source通过channel处理器、拦截器和channel选择器,写入数据到channel成为可能。
每个source都有自己的channel处理器,每次source将数据写入channel,它是通过委派该任务到其channel处理器来完成的,然后,channel处理器将这些事件传到一个或多个source配置的拦截器中。
拦截器:用于source和channel之间,用来更改或者检查Flume的events数据。是一段代码,可以基于某些它完成的处理来读取事件和修改或删除事件,基于某些标准,如正则表达式,拦截器可以用来删除事件,为事件添加新报头或移除现有的报头等,每个source可以配置成使用多个拦截器,按照配置中定义的顺序被调用,将拦截器的结果传递给链的下一个单元,这就是所谓的责任链的设计模式,一旦拦截器处理完事件,拦截器链返回的事件列表传递到channel列表,即通过channel选择器为每个事件选择channel。
管道选择器 channels Selectors:
在多管道是被用来选择使用那一条管道来传递数据(events). 管道选择器又分为如下两种:
- 默认管道选择器: 每一个管道传递的都是相同的events
- 多路复用通道选择器: 依据每一个event的头部header的地址选择管道。
source可以通过处理器-拦截器-选择器路由写入多个channel,channel选择器的决定每个事件必须写入到source附带的哪个channel的组件。因此拦截器可以用来插入或删除事件中的数据,这样channel选择器可以应用一些条件在这些事件上,来决定事件必须写入哪些channel,channel选择器可以对事件应用任意过滤条件,来决定每个事件必须写入哪些channel,以及哪些channel是必须的或可选的。
写入到必需的channel失败将会导致channel处理器抛出channelexception,表明source必须重新重试该事件,而未能写入可选channel失败仅仅忽略它,一旦写出事件,处理器会对source指示成功状态,可能发送确认给发送该事件的系统,并继续接受更多的事件。 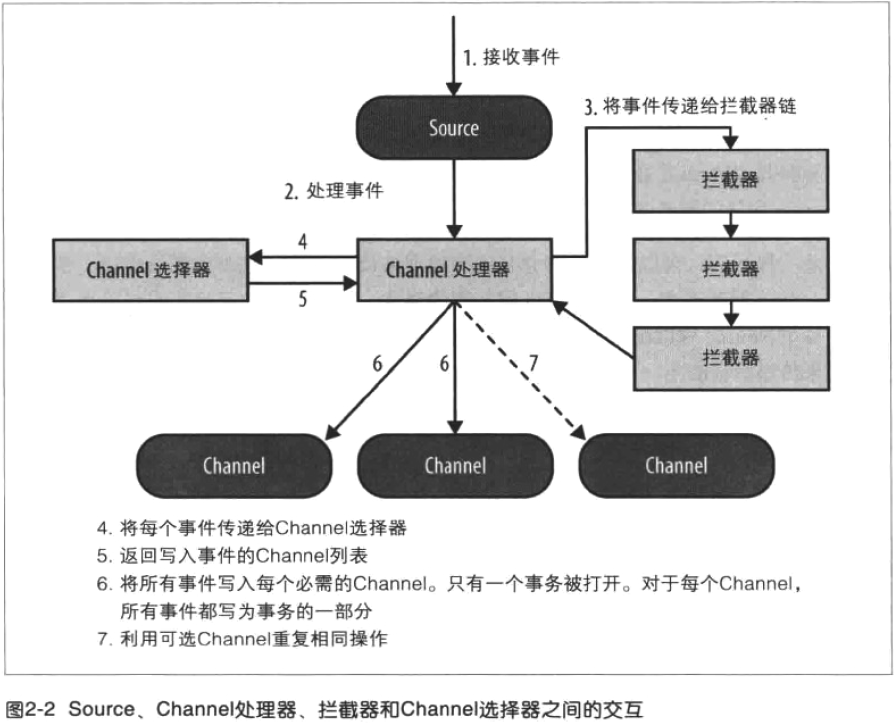
Sink运行器运行一个sink组,sink组可含有一个或多个sink,如果组中只存在一个sink,那么没有组将更有效率,sink运行器仅仅是一个询问sink组来处理下一批事件的线程,每个sink组有一个sink处理器,处理器选择组中的sink之一去处理下一个事件集合,每个sink只能从一个channel获取数据,尽管多个sink可以从同一个channel获取数据,选定的sink从channel中接收事件,并将事件写入到下一阶段或最终目的地。 
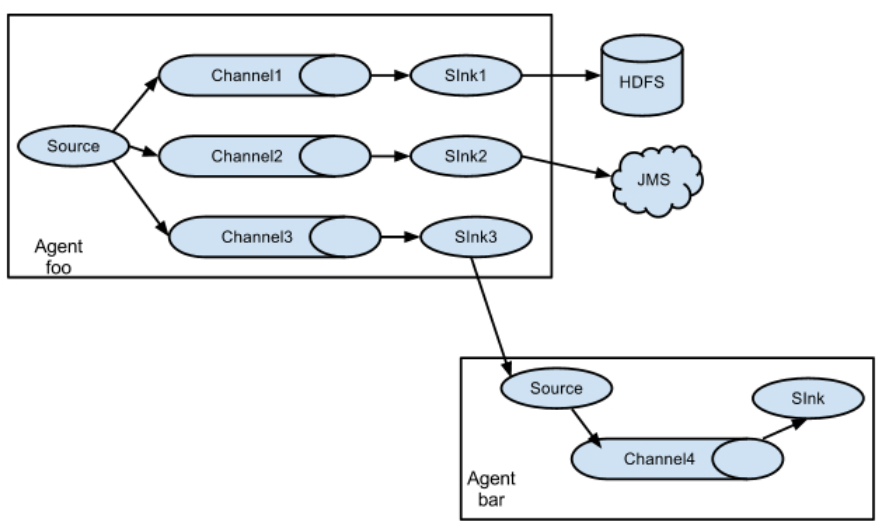
4、组合示例