与RDD类似,DStream也提供了自己的一系列操作方法,这些操作可以分成四类:
- Transformations 普通的转换操作
- Window Operations 窗口转换操作
- Join Operations 合并操作
- Output Operations 输出操作
2.2.3.1 普通的转换操作
普通的转换操作如下表所示:
|
转换 |
描述 |
|
map(func) |
源 DStream的每个元素通过函数func返回一个新的DStream。 |
|
flatMap(func) |
类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素。 |
|
filter(func) |
在源DSTREAM上选择Func函数返回仅为true的元素,最终返回一个新的DSTREAM 。 |
|
repartition(numPartitions) |
通过输入的参数numPartitions的值来改变DStream的分区大小。 |
|
union(otherStream) |
返回一个包含源DStream与其他 DStream的元素合并后的新DSTREAM。 |
|
count() |
对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam。 |
|
reduce(func) |
使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚 合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
|
countByValue() |
计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
|
reduceByKey(func, [numTasks]) |
当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
|
join(otherStream, [numTasks]) |
当被调用类型分别为(K,V)和(K,W)键值对的2个DStream 时,返回类型为(K,(V,W))键值对的一个新DSTREAM。 |
|
cogroup(otherStream, [numTasks]) |
当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
|
transform(func) |
通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
|
updateStateByKey(func) |
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。 |
在上面列出的这些操作中,transform()方法和updateStateByKey()方法值得我们深入的探讨一下:
l transform(func)操作
该transform操作(转换操作)连同其其类似的 transformWith操作允许DStream 上应用任意RDD-to-RDD函数。它可以被应用于未在 DStream API 中暴露任何的RDD操作。例如,在每批次的数据流与另一数据集的连接功能不直接暴露在DStream API 中,但可以轻松地使用transform操作来做到这一点,这使得DStream的功能非常强大。例如,你可以通过连接预先计算的垃圾邮件信息的输入数据流(可能也有Spark生成的),然后基于此做实时数据清理的筛选,如下面官方提供的伪代码所示。事实上,也可以在transform方法中使用机器学习和图形计算的算法。
示例:
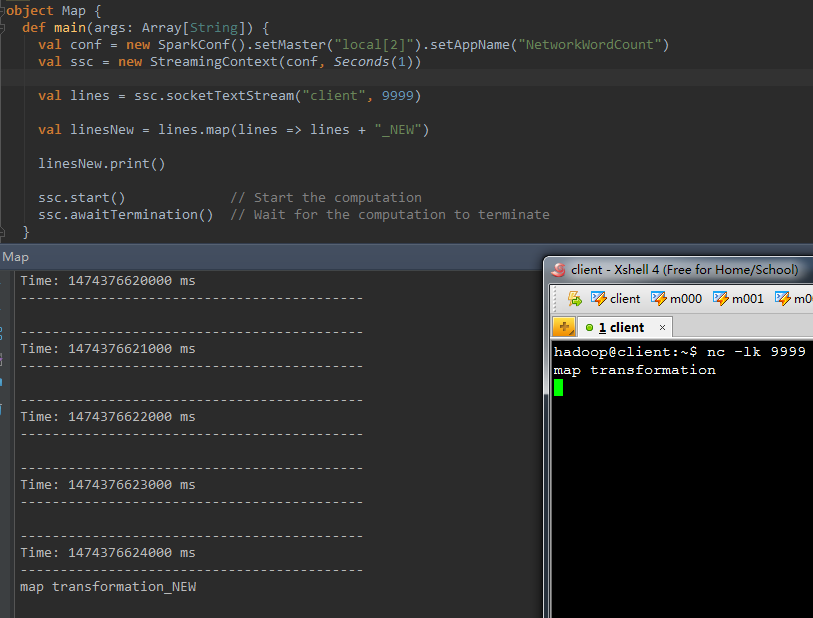
1、map(func)
val b = a.map(func)
val linesNew = lines.map(lines => lines + "_NEW" )
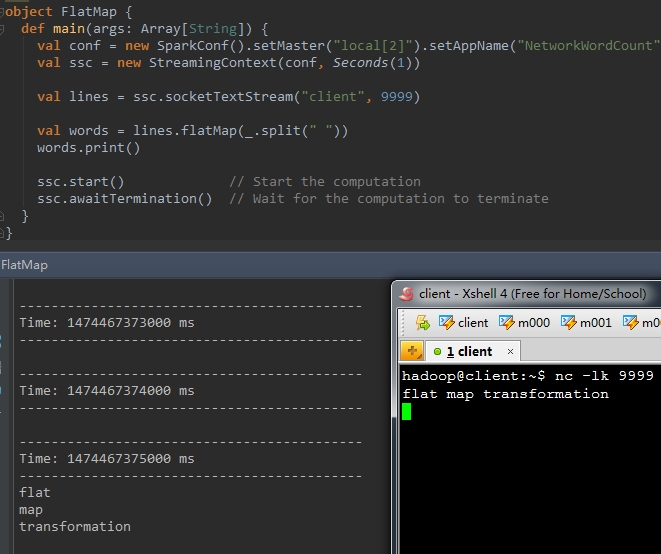
2、flatMap(func)
val b = a.flatMap(func)
val words = lines.flatMap(_.split( " " ))
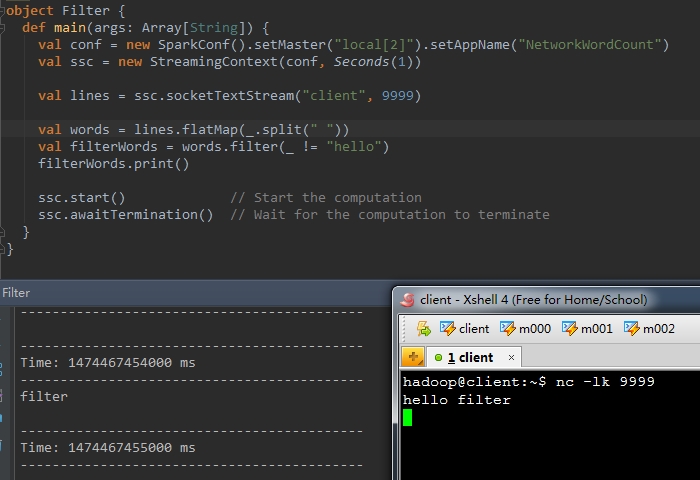
val b = a.filter(func)

val wordsOne = words.map(_ + "_one" ) val wordsTwo = words.map(_ + "_two" ) val unionWords = wordsOne.union(wordsTwo) wordsOne.print() wordsTwo.print() unionWords.print()

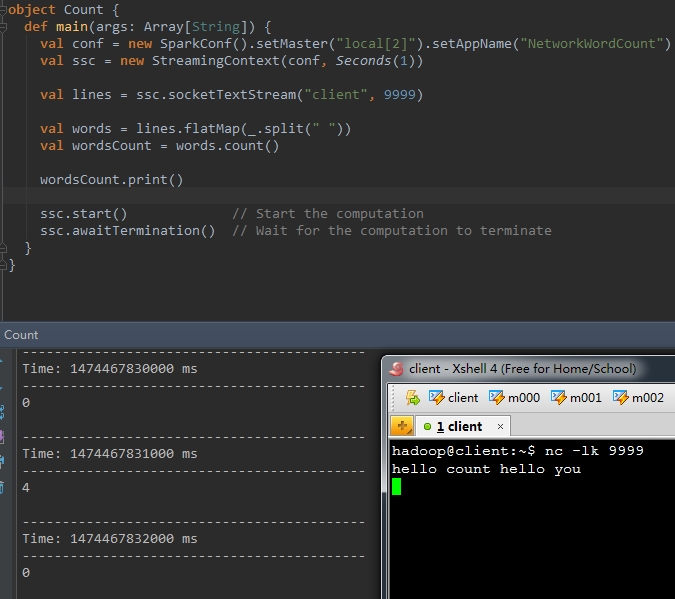
val wordsCount = words.count()
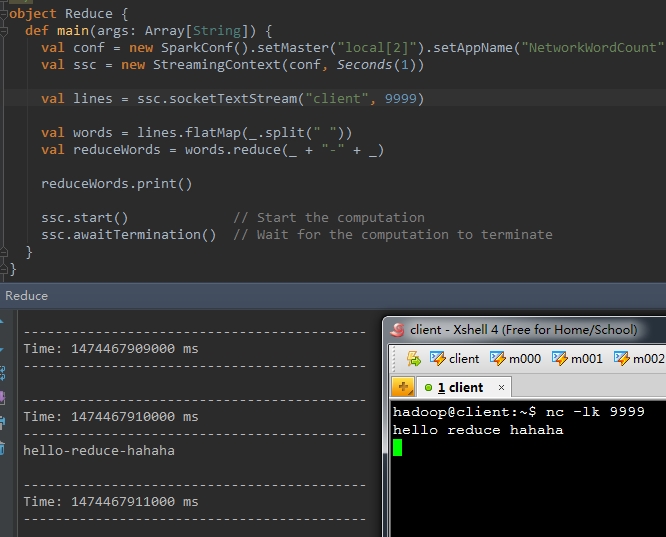
下面的代码,将每一个单词用"-"符号进行拼接
val reduceWords = words.reduce(_ + "-" + _)
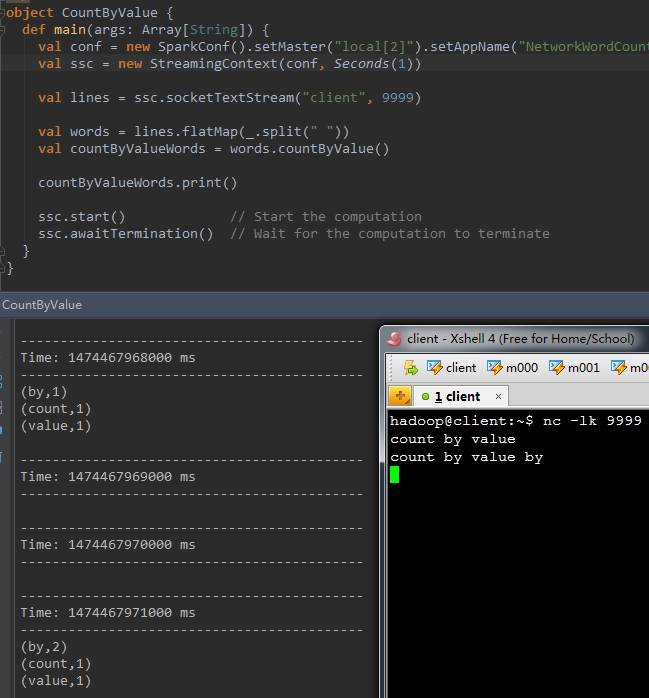
以下代码统计words中不同单词的个数
val countByValueWords = words.countByValue()
下面代码将words转化成(word, 1)的形式,再以单词为key,个数为value,进行word count。
val pairs = words.map(word => (word , 1)) val wordCounts = pairs.reduceByKey(_ + _)

下面代码中,首先将words转化成(word, (word + "_one"))和(word, (word + "_two"))的形式,再以word为key,将后面的value合并到一起。
val wordsOne = words.map(word => (word , word + "_one" )) val wordsTwo = words.map(word => (word , word + "_two" )) val joinWords = wordsOne.join(wordsTwo)

下面代码首先将words转化成(word, (word + "_one"))和(word, (word + "_two"))的形式,再以word为key,将后面的value合并到一起。

l updateStateByKey操作
该 updateStateByKey 操作可以让你保持任意状态,同时不断有新的信息进行更新。要使用此功能,必须进行两个步骤 :
(1) 定义状态 - 状态可以是任意的数据类型。
(2) 定义状态更新函数 - 用一个函数指定如何使用先前的状态和从输入流中获取的新值 更新状态。
让我们用一个例子来说明,假设你要进行文本数据流中单词计数。在这里,正在运行的计数是状态而且它是一个整数。我们定义了更新功能如下:

此函数应用于含有键值对的DStream中(如前面的示例中,在DStream中含有(word,1)键值对)。它会针对里面的每个元素(如wordCount中的word)调用一下更新函数,newValues是最新的值,runningCount是之前的值。
