说明:
LNMP架构。

crontab里有每隔20分钟重启php的任务;然后我用python写了个每1分钟检测php-cgi进程是否存在的脚本,如果不存在则调用重启php的脚本,并邮件通知管理员。crontab 和python脚本都调用的是/usr/local/webserver/php/restart_php.sh 这个脚本,权限都是root。
根据如下的邮件通知截图,说明在 13:20 和 14:20 的时候,crontab 里执行重启php任务失败(此时站点表现为502 Bad Gateway,因为 nginx 找不到反向代理)。接着后一分钟 python 脚本检测到 php-cgi 监听 9000 端口的进程不存在,然后再次调用了 restart_php.sh 脚本。

我们去看一下 php 的日志(/uar/local/webserver/php/log/php-fpm.log),为什么 crontab 重启会失败。
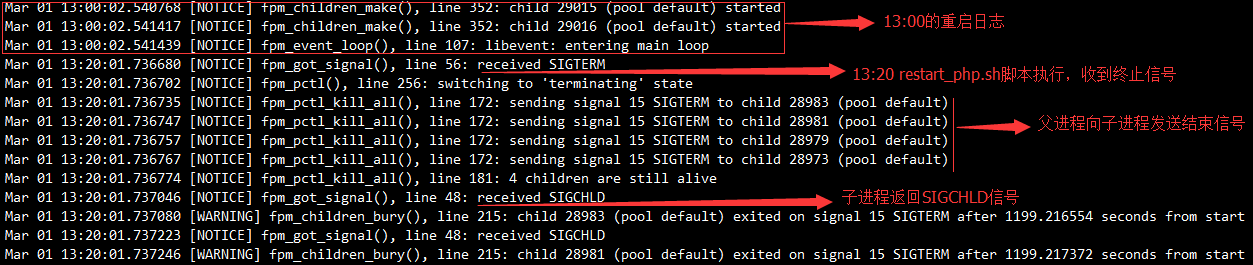

SIGCHLD信号说明:
“任何一个子进程(init除外)在exit后并非马上就消失,而是留下一个称为僵尸进程的数据结构,等待父进程处理。这是每个子进程都必需经历的阶段。另外子进程退出的时候会向其父进程发送一个SIGCHLD信号。”
然而父进程并没有挂起等待子进程的完全结束,所以会出现什么情况?我们先看一下restart_php.sh:


php-fpm stop命令会给 php-cgi 子进程发送SIGTERM信号,为确认所有进程被终止,紧接着又调用了两次 killall,然后才执行 php-fpm start 命令。但是这时候所有的子进程也不一定都终止了,所以如果这时候 php-fpm start,由于子进程还没有释放绑定的端口(9000),就会出现端口绑定失败:
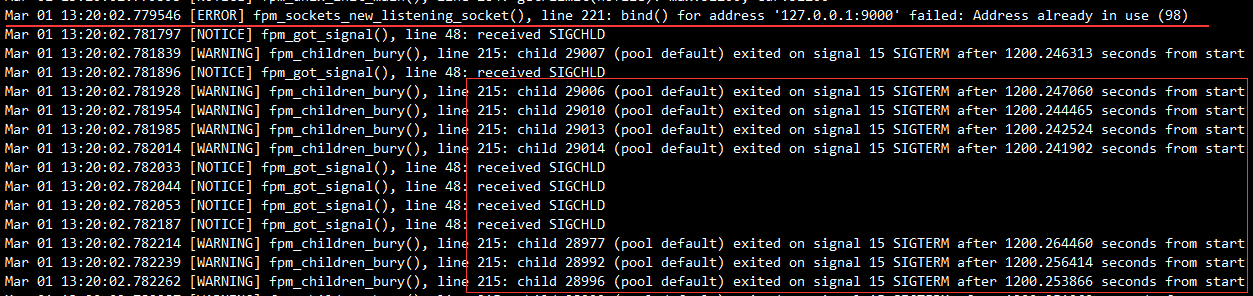

注意看日志,在端口绑定失败之后,还陆续有子进程退出的日志打印,再次说明 php-fpm start 的时候还有子进程没 kill 干净。
再看 13:21 的时候,python 脚本又来调用 restart_php.sh 了:


注意看有4个子进程只运行了59秒(对比前面的日志,正常运行的子进程应该是1200秒——20分钟),这就是13:20重启的时候生成的4个子进程。(如果重启正常应该是75个子进程,因为端口绑定失败,所以其他子进程没启动成功)
然后这次重启就成功了。为什么这次重启一定会成功?因为第二次重启在第一次重启一分钟后,如果第一次重启成功了,第二次重启不会进行;第一次重启失败了(会产生4个子进程),那么第二次重启时会首先杀掉前面的4个子进程,因为只有4个,kill 起来很快很干净,然后再执行 php-fpm start 时就不会端口绑定错误了。
解决办法
知道原因之后,解决方案就简单了。目的只有一个:在php-fpm start 之前确保子进程已经完全退出。
(1)使用 killall -w 参数
但是要注意。


(2)使用 ps 、pgrep 等命令检测php-cgi子进程是否存在。
(3)在php-fpm start 之前 sleep 几秒。
我采用的是方案(1),目前测试中,尚未出现问题。从下面日志中可见php-fpm start 距离 php-fpm 完全退出约有两秒的时间。




另外,从下面日志看出,502 Bad Gateway 这个问题在2015年很少,从2016年2月22号开始,很频繁出现9000端口绑定错误。不知道是改动了什么地方。



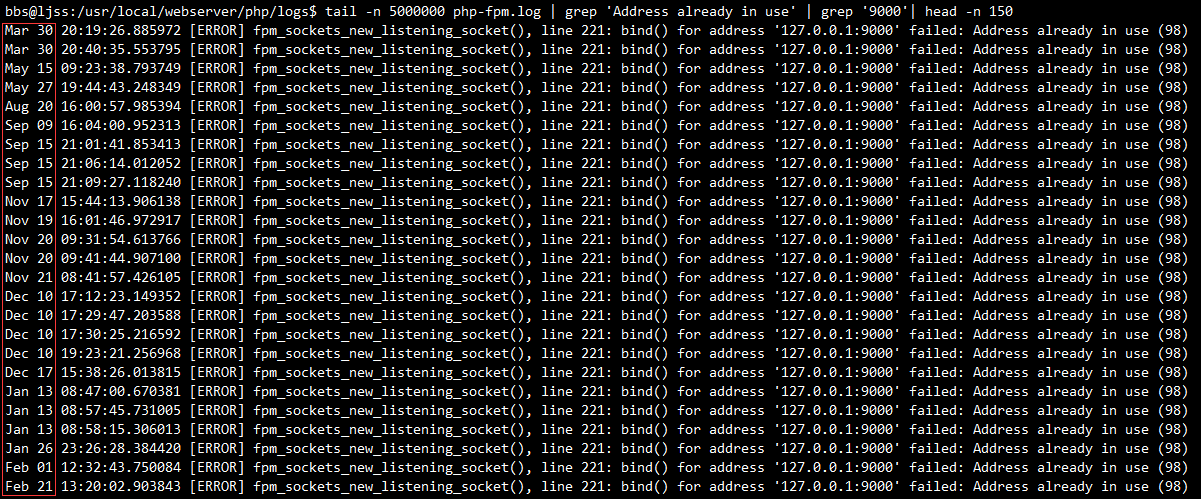


再另外,重启php的根本原因是句柄泄漏(越来越多文件打开,不重启会导致系统死机)?这个问题似乎由来已久,在/home/bbs/目录下有一个php_file_open.txt文件,创建日期为12年7月30号。


文件内容为 lsof -c php-cgi 命令的执行结果:


这个文件有17000多行,可见当时就存在句柄泄漏的问题,所以才有了crontab里的定时重启php。

