【转】并行开发
地址:http://www.cnblogs.com/woxpp/p/3924476.html
TPL中引入了一个新命名空间System.Threading.Tasks,在该命名空间下Task是主类,表示一个类的异步的并发的操作,创建并行代码的时候不一定要直接使用Task类,在某些情况下可以直接使用Parallel静态类(System.Threading.Tasks.Parallel)下所提供的方法,而不用底层的Task实例。
Parallel.Invoke
试图将很多方法并行运行,如果传入的是4个方法,则至少需要4个逻辑内核才能足以让这4个方法并发运行,逻辑内核也称为硬件线程。
需要注意的是:1.即使拥有4个逻辑内核,也不一定能够保证所需要运行的4个方法能够同时启动运行,如果其中的一个内核处于繁忙状态,那么底层的调度逻辑可能会延迟某些方法的初始化执行。
2.通过Parallel.Invoke编写的并发执行代码一定不能依赖与特定的执行顺序,因为它的并发执行顺序也是不定的。
3.使用Parallel.Invoke方法一定要测量运行结果、实现加速比以及逻辑内核的使用率,这点很重要。
4.使用Parallel.Invoke,在运行并行方法前都会产生一些额外的开销,如分配硬件线程等。
好处:这是一种并行运行很多方法的简单方式,使用Parallel.Invoke,不需要考虑任务和线程的问题。
下面贴代码:
 View Code
View Code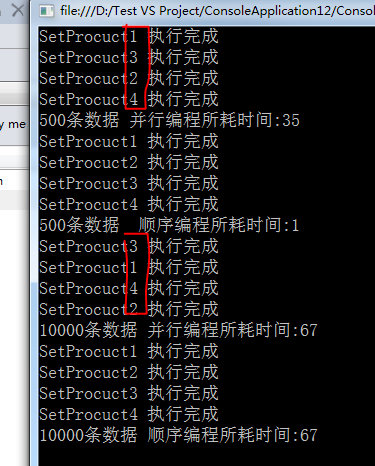
图中我们可以看出利用 Parallel.Invoke编写的并发执行代,它的并发执行顺序也是不定的。
但是所执行的时间上比不采用并行编程所耗的时间差不多。
这是因为我们在并行编程中操作了共享资源 ProductList ,如果我把代码做出以下修改,采用并行编程的好处就显现出来了。
View Code我将每个方法中的资源隔离,性能显而易见。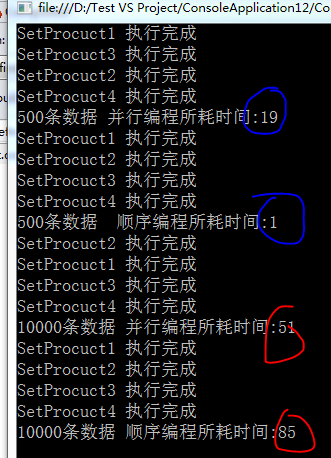
但是在操作500条数据时,显然采用并行操作并不明智,并行所带来的损耗比较大,在实际的开发中,还是要注意下是否有必要进行并行编程。
Parallel.For
将for循环替换成Parallel.For,并采用适合这个新方法的参数,就可以对这个已有的for循环进行重构,使其能够充分利用并行化优势。
需要注意的是:1.Parallel.For不支持浮点数的步进,使用的是Int32或Int64,每一次迭代的时候加1
2.由于循环体是并行运行,去迭代执行的顺序无法保证
下面贴代码
View Code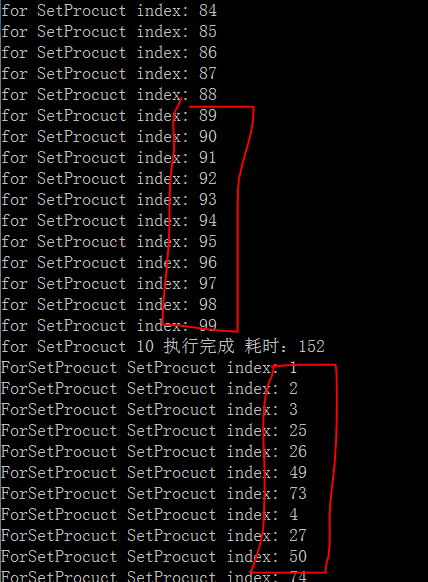
由图中我们可以看出,使用Parallel.For所迭代的顺序是无法保证的。
Parallel.ForEach
Parallel.ForEach提供一个并行处理一组数据的机制,可以利用一个范围的整数作为一组数据,然后通过一个自定义的分区器将这个范围转换为一组数据块,每一块数据都通过循环的方式进行处理,而这些循环式并行执行的。
下面贴代码:
View Code
ParallelLoopState
ParallelLoopState该实例提供了以下两个方法用于停止 Parallel.For,Parallel.ForEach
Break-这个方法告诉并行循环应该在执行了当前迭代后尽快地停止执行。吐过调用Break时正在处理迭代100,那么循环仍然会处理所有小于100的迭代。
Stop-这个方法告诉并行循环应该尽快停止执行,如果调用Stop时迭代100正在被处理,那么循环无法保证处理完所有小于100的迭代
下面贴代码
View Code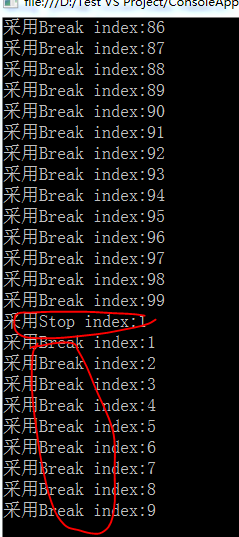
由图中可以看出Break可以保证输出满足所有条件的数据,而Stop则无法保证。