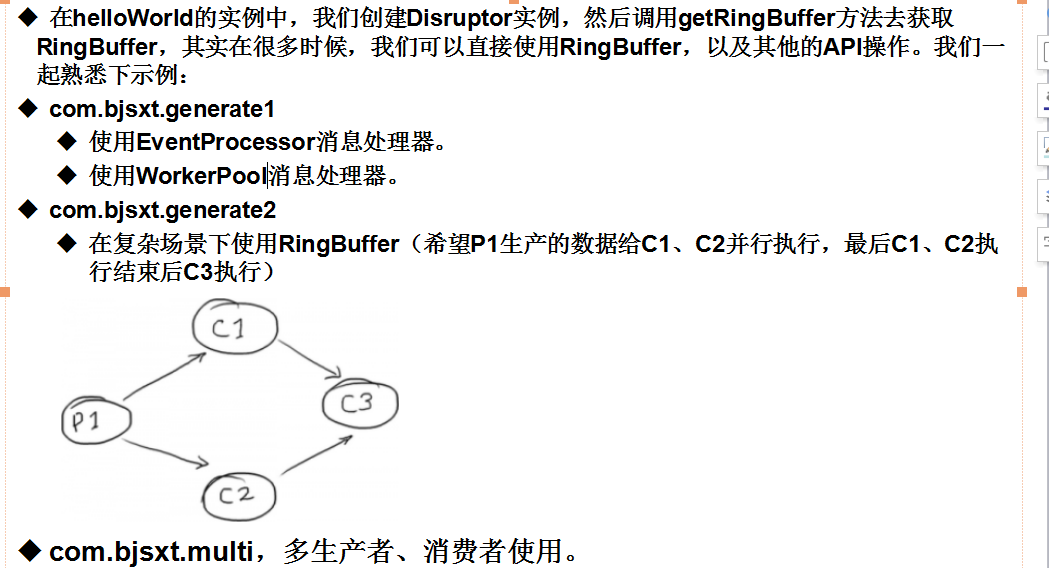
简介:
Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动方式。业务逻辑处理器的核心是Disruptor。
Disruptor它是一个开源的并发框架,并获得2011 Duke’s 程序框架创新奖,能够在无锁的情况下实现网络的Queue并发操作。 Disruptor是一个高性能的异步处理框架,或者可以认为是最快的消息框架(轻量的JMS),也可以认为是一个观察者模式的实现,或者事件监听模式的实现。
目前我们使用disruptor已经更新到了3.x版本,比之前的2.x版本性能更加的优秀,提供更多的API使用方式。
下载disruptor-3.3.2.jar引入我们的项目既可以开始disruptor之旅。 在使用之前,首先说明disruptor主要功能加以说明,你可以理解为他是一种高效的"生产者-消费者"模型。也就性能远远高于传统的BlockingQueue容器。 官方学习网站:http://ifeve.com/disruptor-getting-started/
在Disruptor中,我们想实现hello world 需要如下几步骤:
第一:建立一个Event类
第二:建立一个工厂Event类,用于创建Event类实例对象
第三:需要有一个监听事件类,用于处理数据(Event类)
第四:我们需要进行测试代码编写。实例化Disruptor实例,配置一系列参数。然后我们对Disruptor实例绑定监听事件类,接受并处理数据。
第五:在Disruptor中,真正存储数据的核心叫做RingBuffer,我们通过Disruptor实例拿到它,然后把数据生产出来,把数据加入到RingBuffer的实例对象中即可。 我们一起来看下这个HelloWorld程序:com.bjsxt.base
RingBuffer: 被看作Disruptor最主要的组件,然而从3.0开始RingBuffer仅仅负责存储和更新在Disruptor中流通的数据。对一些特殊的使用场景能够被用户(使用其他数据结构)完全替代。
Sequence: Disruptor使用Sequence来表示一个特殊组件处理的序号。和Disruptor一样,每个消费者(EventProcessor)都维持着一个Sequence。大部分的并发代码依赖这些Sequence值的运转,因此Sequence支持多种当前为AtomicLong类的特性。
Sequencer: 这是Disruptor真正的核心。实现了这个接口的两种生产者(单生产者和多生产者)均实现了所有的并发算法,为了在生产者和消费者之间进行准确快速的数据传递。
SequenceBarrier: 由Sequencer生成,并且包含了已经发布的Sequence的引用,这些的Sequence源于Sequencer和一些独立的消费者的Sequence。它包含了决定是否有供消费者来消费的Event的逻辑。
Disruptor术语:
WaitStrategy:决定一个消费者将如何等待生产者将Event置入Disruptor。
Event:从生产者到消费者过程中所处理的数据单元。Disruptor中没有代码表示Event,因为它完全是由用户定义的。
EventProcessor:主要事件循环,处理Disruptor中的Event,并且拥有消费者的Sequence。它有一个实现类是BatchEventProcessor,包含了event loop有效的实现,并且将回调到一个EventHandler接口的实现对象。
EventHandler:由用户实现并且代表了Disruptor中的一个消费者的接口。 Producer:由用户实现,它调用RingBuffer来插入事件(Event),在Disruptor中没有相应的实现代码,由用户实现。
WorkProcessor:确保每个sequence只被一个processor消费,在同一个WorkPool中的处理多个WorkProcessor不会消费同样的sequence。
WorkerPool:一个WorkProcessor池,其中WorkProcessor将消费Sequence,所以任务可以在实现WorkHandler接口的worker吃间移交 LifecycleAware:当BatchEventProcessor启动和停止时,于实现这个接口用于接收通知。


如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。
我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠。
因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。
这是对CPU缓存友好的,也就是说在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
简单的demo
package bhz.base; import java.nio.ByteBuffer; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import com.lmax.disruptor.RingBuffer; import com.lmax.disruptor.YieldingWaitStrategy; import com.lmax.disruptor.dsl.Disruptor; import com.lmax.disruptor.dsl.ProducerType; public class LongEventMain { public static void main(String[] args) throws Exception { //创建缓冲池 ExecutorService executor = Executors.newCachedThreadPool(); //创建工厂 LongEventFactory factory = new LongEventFactory(); //创建bufferSize ,也就是RingBuffer大小,必须是2的N次方 int ringBufferSize = 1024 * 1024; // /** //BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现 WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy(); //SleepingWaitStrategy 的性能表现跟BlockingWaitStrategy差不多,对CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景 WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy(); //YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性 WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy(); */ //创建disruptor Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory, ringBufferSize, executor, ProducerType.SINGLE, new YieldingWaitStrategy()); // 连接消费事件方法 disruptor.handleEventsWith(new LongEventHandler()); // 启动 disruptor.start(); //Disruptor 的事件发布过程是一个两阶段提交的过程: //发布事件 RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); LongEventProducer producer = new LongEventProducer(ringBuffer); //LongEventProducerWithTranslator producer = new LongEventProducerWithTranslator(ringBuffer); ByteBuffer byteBuffer = ByteBuffer.allocate(8); for(long l = 0; l<100; l++){ byteBuffer.putLong(0, l); producer.onData(byteBuffer); //Thread.sleep(1000); } disruptor.shutdown();//关闭 disruptor,方法会堵塞,直至所有的事件都得到处理; executor.shutdown();//关闭 disruptor 使用的线程池;如果需要的话,必须手动关闭, disruptor 在 shutdown 时不会自动关闭; } }
package bhz.base; import java.nio.ByteBuffer; import com.lmax.disruptor.RingBuffer; /** * 很明显的是:当用一个简单队列来发布事件的时候会牵涉更多的细节,这是因为事件对象还需要预先创建。 * 发布事件最少需要两步:获取下一个事件槽并发布事件(发布事件的时候要使用try/finnally保证事件一定会被发布)。 * 如果我们使用RingBuffer.next()获取一个事件槽,那么一定要发布对应的事件。 * 如果不能发布事件,那么就会引起Disruptor状态的混乱。 * 尤其是在多个事件生产者的情况下会导致事件消费者失速,从而不得不重启应用才能会恢复。 * <B>系统名称:</B><BR> * <B>模块名称:</B><BR> * <B>中文类名:</B><BR> * <B>概要说明:</B><BR> * @author 北京尚学堂(alienware) * @since 2015年11月23日 */ public class LongEventProducer { private final RingBuffer<LongEvent> ringBuffer; public LongEventProducer(RingBuffer<LongEvent> ringBuffer){ this.ringBuffer = ringBuffer; } /** * onData用来发布事件,每调用一次就发布一次事件 * 它的参数会用过事件传递给消费者 */ public void onData(ByteBuffer bb){ //1.可以把ringBuffer看做一个事件队列,那么next就是得到下面一个事件槽 long sequence = ringBuffer.next(); try { //2.用上面的索引取出一个空的事件用于填充(获取该序号对应的事件对象) LongEvent event = ringBuffer.get(sequence); //3.获取要通过事件传递的业务数据 event.setValue(bb.getLong(0)); } finally { //4.发布事件 //注意,最后的 ringBuffer.publish 方法必须包含在 finally 中以确保必须得到调用;如果某个请求的 sequence 未被提交,将会堵塞后续的发布操作或者其它的 producer。 ringBuffer.publish(sequence); } } }
package bhz.base; //http://ifeve.com/disruptor-getting-started/ public class LongEvent { private long value; public long getValue() { return value; } public void setValue(long value) { this.value = value; } }
package bhz.base; import com.lmax.disruptor.EventFactory; // 需要让disruptor为我们创建事件,我们同时还声明了一个EventFactory来实例化Event对象。 public class LongEventFactory implements EventFactory { @Override public Object newInstance() { return new LongEvent(); } }
package bhz.base; import com.lmax.disruptor.EventHandler; //我们还需要一个事件消费者,也就是一个事件处理器。这个事件处理器简单地把事件中存储的数据打印到终端: public class LongEventHandler implements EventHandler<LongEvent> { @Override public void onEvent(LongEvent longEvent, long l, boolean b) throws Exception { System.out.println(longEvent.getValue()); } }
package bhz.base; import java.nio.ByteBuffer; import com.lmax.disruptor.EventTranslatorOneArg; import com.lmax.disruptor.RingBuffer; /** * Disruptor 3.0提供了lambda式的API。这样可以把一些复杂的操作放在Ring Buffer, * 所以在Disruptor3.0以后的版本最好使用Event Publisher或者Event Translator来发布事件 * <B>系统名称:</B><BR> * <B>模块名称:</B><BR> * <B>中文类名:</B><BR> * <B>概要说明:</B><BR> * @author 北京尚学堂(alienware) * @since 2015年11月23日 */ public class LongEventProducerWithTranslator { //一个translator可以看做一个事件初始化器,publicEvent方法会调用它 //填充Event private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR = new EventTranslatorOneArg<LongEvent, ByteBuffer>() { @Override public void translateTo(LongEvent event, long sequeue, ByteBuffer buffer) { event.setValue(buffer.getLong(0)); } }; private final RingBuffer<LongEvent> ringBuffer; public LongEventProducerWithTranslator(RingBuffer<LongEvent> ringBuffer) { this.ringBuffer = ringBuffer; } public void onData(ByteBuffer buffer){ ringBuffer.publishEvent(TRANSLATOR, buffer); } }