Memcached 缓存系统简介
What is Memcached?
- Memcached是一个自由开源的,高性能,高并发,分布式内存对象缓存系统。
- Memcached是一种完全基于内存的key-value存储,用来存储小块的任意数据(字符串、对象)。这些数据可以是数据库调用、API调用或者是页面渲染的结果。
- Memcached简单但功能强大;其简单的设计促进了快速部署、易于开发,并解决了大型数据缓存所面临的许多问题。且它的API兼容大多数流行的语言。
工作原理
- memcached是一套C/S模式架构的软件,在服务器端启动服务守护进程,可以为memcached服务器指定监听的IP地址、端口号、并发访问连接数、以及分配多少内存来处理客户端的请求的参数
- memcached本身是一个非常轻量级的服务,不支持主辅同步,也没有集群的概念。但为了可扩展性,memcached 服务器server端和 memcached 客户client端结合起来可以构成一个分布式系统。在memcached分布式系统中,各个 memcached 节点之间无须通信,所以扩展性非常好。
- memcached采用的是异步I/O,其实现方式是基于事件的单进程和单线程。使用libevent作为事件通知机制,多个服务器端可以协同工作,但这些服务器端之间是没有任何通信联系的,每个服务器只对自己的数据进行管理。应用程序端通过指定缓存服务器的IP地址和端口,就可以连接memcached服务进行相互通信
- memcached是完全基于内存操作的,是一个缓存系统,从本质它不是一个数据库系统,也不支持持久化。因此存取速度非常快;但是断电数据即消失。
memcached缓存系统在openstack服务中的作用
- 在大型海量并发访问网站及openstack等集群中,对于关系型数据库,尤其是大型关系型数据库,如果对其进行每秒上万次的并发访问,并且每次访问都在一个有上亿条记录的数据表中查询某条记录时,其效率会非常低,对数据库而言,这也是无法承受的。
- 缓存系统的使用可以很好的解决大型并发数据访问所带来的效率低下和数据库压力等问题,缓存系统将经常使用的活跃数据存储在内存中避免了访问重复数据时,数据库查询所带来的频繁磁盘i/o和大型关系表查询时的时间开销,因此缓存系统几乎是大型网站的必备功能模块。
- 缓存系统可以认为是基于内存的数据库,相对于后端大型生产数据库而言基于内存的缓存数据库能够提供快速的数据访问操作,从而提高客户端的数据请求访问反馈,并降低后端数据库的访问压力。
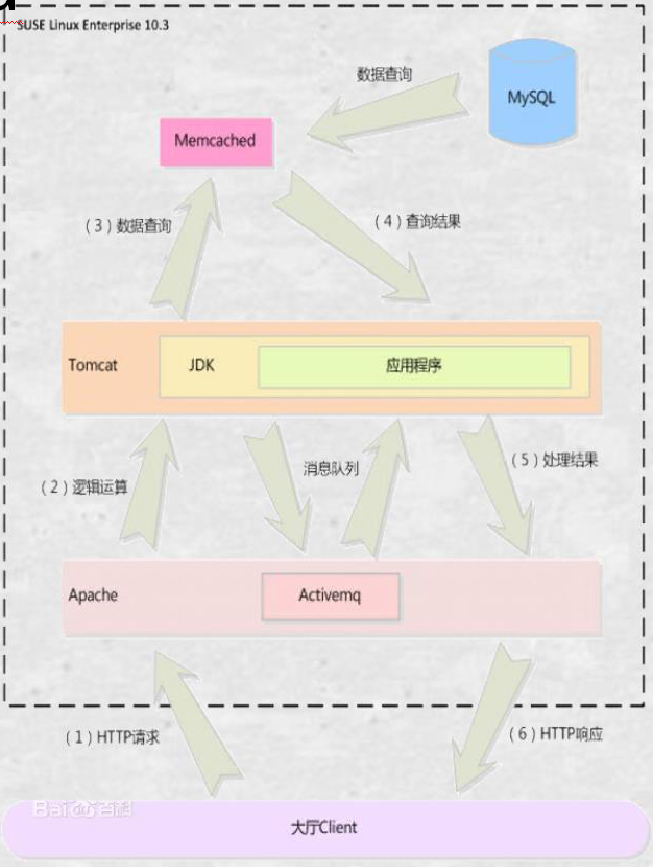
memcached缓存系统工作流程
- 检查客户端请求的数据是否在 Memcache 中,如果存在,直接将请求的数据返回,不在对数据进行任何操作。
- 如果请求的数据不在 Memcache 中,就去数据库查询,把从数据库中获取的数据返回给客户端,同时把数据缓存一份 Memcache 中
- 每次更新数据库的同时更新 Memcache 中的数据库。确保数据信息一致性。
- 当分配给 Memcache 内存空间用完后,会使用LRU(least Recently Used ,最近最少使用 ) 策略加到其失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据。

原文地址:https://www.cnblogs.com/du-z/p/11270033.html