scrapyd
安装
scrapyd-中心节点,子节点安装scrapyd-client
pip3 install scrapyd
pip3 install scrapyd-client

scrapyd-client两个作用
把本地的代码打包生成egg包
把egg上传到远程的服务器上
windows配置scrapyd-deploy
H:Python36Scripts下创建scrapyd-deploy.bat
python H:/Python36/Scripts/scrapyd-deploy %*
curl.exe放入H:Python36Scripts
启动scrapyd启动服务!!!!!!!!!!
scrapyd-deploy 查询
切换到scrapy中cmd运行scrapyd-deploy
H:DDD-scrapydouban>scrapyd-deploy
scrapyd-deploy -l

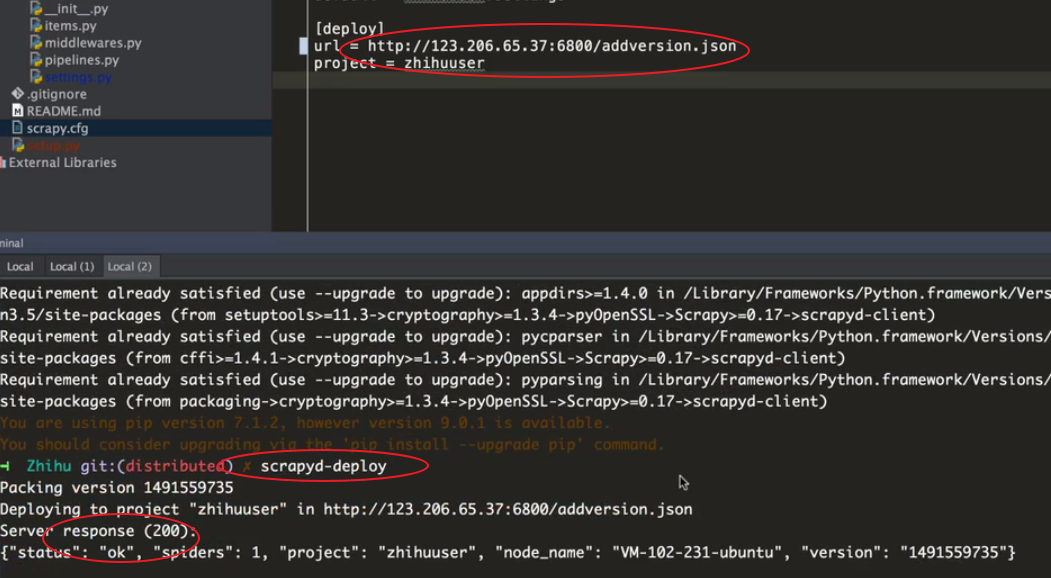
scrapy中scrapy.cfg修改配置
[deploy:dj] #开发项目名
url = http://localhost:6800/
project = douban #项目名
scrapy list这个命令确认可用,结果dang是spider名

如不可用,setting中添加以下

scrapyd-deploy 添加爬虫
scrapyd-deploy dj -p douban
H:/Python36/Scripts/scrapyd-deploy dang1 -p dangdang
dang1是开发项目名,dangdang是项目名

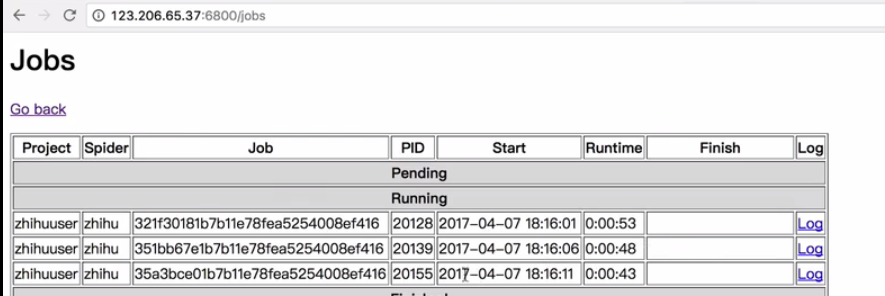
http://127.0.0.1:6800/jobs
scrapyd 当前项目的状态
curl http://localhost:6800/daemonstatus.json

curl启动爬虫
curl http://localhost:6800/schedule.json -d project=dangdang -d spider=dang
dangdang是项目名,dang是爬虫名

project=douban,spider=doubanlogin
curl http://localhost:6800/schedule.json -d project=douban -d spider=doubanlogin


远程部署:scrapyd-deploy
scrapyd-deploy 17k -p my17k
列出所有已经上传的spider
curl http://47.97.169.234:6800/listprojects.json

列出当前项目project的版本version
curl http://47.97.169.234:6800/listversions.json?project=my17k

远程启动spider
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

运行三次,就类似于开启三个进程
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

查看当前项目的运行情况

取消爬虫项目的job任务
curl http://localhost:6800/cancel.json -d project=dangdang -d job=68d25db0506111e9a4c0e2df1c2eb35b
curl http://47.97.169.234:6800/cancel.json -d project=my17k -d job=be6ed036508611e9b68000163e08dec9

centos配置scrapyd
https://www.cnblogs.com/ss-py/p/9661928.html
安装后新建一个配置文件:
sudo mkdir /etc/scrapyd
sudo vim /etc/scrapyd/scrapyd.conf
写入如下内容:(给内容在https://scrapyd.readthedocs.io/en/stable/config.html可找到)
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
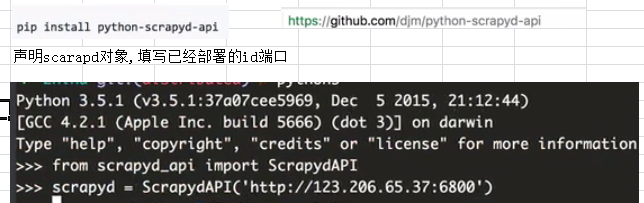
scrapyd-api
安装
scrapyd-api对scrapyd进行了一些封装
from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
使用
显示所有的projects
scrapyd.list_projects()

显示该项目下的spiders
scrapyd.list_spiders('my17k')

from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
print(scrapyd.list_projects()) #查询项目名
print(scrapyd.list_spiders('my17k')) #查询该项目名下的爬虫名