程序=数据结构+算法
结构来看:变量,列表=数组
数据怎么存储,就是数据结构
整个就是一个过程,修改这个过程就是算法
数据是静态 ,算法是动态,加起来就是程序
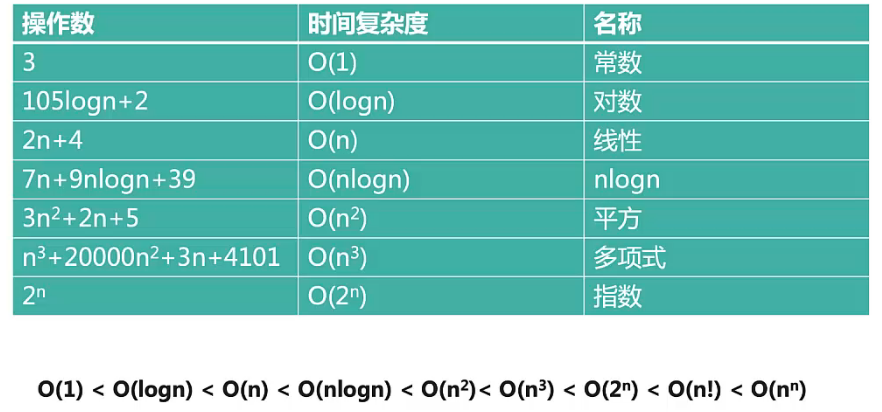
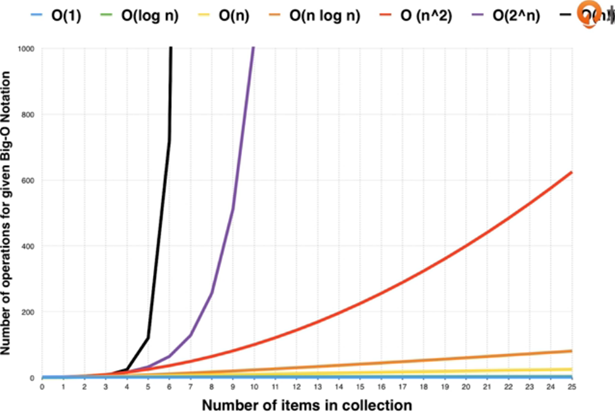
时间复杂度:大O表示法
如何一眼判断时间复杂度?
循环减半的过程O(logn)
几次循环就是n的几次方的复杂度
li = [1, 2, 10, 30, 33, 99] value = 10 # 二分法 # 时间复杂度O(logN)
'''
思路:
先取得该列表的索引中间值mid,如len(li)==0,则没有这个值
判断如li[mid]>最终值,则后再在递归调用前半部分,
判断如li[mid]<最终值,则后再在递归调用后半部分,如li[mid]=最终值,就找到结果.
'''
def binarysearch(li,value): if len(li)==0: print('not got it') return mid = len(li) // 2 if li[mid] == value: print('got it') return mid elif li[mid] > value: binarysearch(li[:mid], value) elif li[mid] < value: binarysearch(li[mid+1:], value) binarysearch(li, value)




斐波那契数列O(n^2)


二分法查找




排序
'''
快速排序、堆排序、归并排序-小结
三种排序算法的时间复杂度都是O(nlogn)
一般情况下,就运行时间而言:
快速排序 < 归并排序 < 堆排序
三种排序算法的缺点:
快速排序:极端情况下排序效率低
归并排序:需要额外的内存开销
堆排序:在快的排序算法中相对较慢
'''
import random
import time
import sys
sys.setrecursionlimit(1000000)
'''
排序Low B三人组
冒泡排序:两次循环
选择排序:选择苹果
插入排序:斗地主插排
'''
def caltime(func):
def inner(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print('%s时间是: %s' % (func.__name__, end-start))
return inner
冒泡排序
'''
#冒泡排序,代码关键点:趟,无序区
首先,列表每两个相邻的数,如果前边的比后边的大,那么交换这两个数……
会发生什么?
优化:如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束算法。
##时间复杂度: O(n^2)
'''
@caltime
def BubbleSort(li):
for i in range(len(li)):
#### i = 0 i = 1 --- 8
flag = False
for j in range(len(li)-i-1): ### j = 0, 1, 2, 3, 7
if li[j] > li[j+1]: ### li[0] > li[1] | li[1] > li[2] | li[2] > li[3]
li[j], li[j+1] = li[j+1], li[j] #### [5,4,6,7,3,8,2,1,9]
flag = True
if not flag:
return
选择排序
'''
#选择排序,代码关键点:无序区,最小数的位置
思路:
一趟遍历记录最小的数,放到第一个位置;
再一趟遍历记录剩余列表中最小的数,继续放置;
#### 时间复杂度:O(n^2)
……
'''
@caltime
def selectSort(li):
for i in range(len(li)):
minLoc = i # minLoc = i = 0
for j in range(i+1, len(li)): # j = 1, j = 2
if li[j] < li[minLoc]: ### li[2] < li[minLoc] 4 < 5
li[j], li[minLoc] = li[minLoc], li[j] ## [5,7,4,6,3,8,2,9,1]
插入排序
'''
#插入排序,代码关键点:摸到的牌,手里的牌
思路:
列表被分为有序区和无序区两个部分。最初有序区只有一个元素。
每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空。
#### 时间复杂度:O(n^2)
'''
@caltime
def insertSort(li):
for i in range(1, len(li)):
tmp = li[i] ## tmp = li[1] = 5
j = i - 1 ## j = 1 - 1 = 0
while j >= 0 and li[j] > tmp: ## li[0] = 7 > 5:
li[j+1] = li[j] ## li[1] = li[0] = 7 ==> [7,7,4,6,3,8,2,9,1]
j = j - 1 ## j = -1
li[j+1] = tmp ### li[0] = tmp = 5 ==> [5,7,4,6,3,8,2,9,1]
快速排序
'''
#快速排序
好写的排序算法里最快的
快的排序算法里最好写的
快排思路:
取一个元素p(第一个元素),使元素p归位;
列表被p分成两部分,左边都比p小,右边都比p大;
递归完成排序。
详细思路:
归位第一个值,归位值的前半段和后半段进行排序
归位:
最左边的值定义tmp
如左边的索引大于右边,且最右边的值大于等于tmp,最右的索引-1.最左边的值赋值给最右边
如左边的索引大于右边,且最右边的值小于等于tmp,最左的索引+1.最右边的值赋值给最左边
如左边的索引非大于右边,那temp就还是最左边的值
返回最左边值的索引
'''
### O(n)
def partition(li, left, right):
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp:
right = right - 1
li[left] = li[right]
while left < right and li[left] <= tmp:
left = left + 1
li[right] = li[left]
li[left] = tmp
return left
## 时间复杂度: O(nlogn)
def _quickSort(li, left, right):
if left < right:
mid = partition(li, left, right) ### O(n)
_quickSort(li, left, mid - 1) ### O(logn)
_quickSort(li, mid + 1, right)
@caltime
def quickSort(li, left, right):
_quickSort(li, left, right)
归并排序
'''
归并排序:
分解:将列表越分越小,直至分成一个元素。
一个元素是有序的。
合并:将两个有序列表归并,列表越来越大。
'''
### 时间复杂度: O(nlogn)
def merge(li, low, mid, right):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= right:
if li[i] < li[j]:
ltmp.append(li[i])
i = i + 1
else:
ltmp.append(li[j])
j = j + 1
while i <= mid:
ltmp.append(li[i])
i = i + 1
while j <= right:
ltmp.append(li[j])
j = j + 1
li[low:right+1] = ltmp
def mergeSort(li, low, high):
if low < high:
mid = (low + high) // 2
mergeSort(li, low, mid)
mergeSort(li, mid + 1, high)
print('归并之前:', li[low:high+1])
merge(li, low, mid, high)
print('归并之后:', li[low:high + 1])
计数排序
现在有一个列表,列表中的数范围都在0到100之间,列表长度大约为100万。设计算法在O(n)时间复杂度内将列表进行排序。
'''
计数排序:创建一个列表,用来统计每个数出现的次数。
思路:
count定义循环列出1到10的数(按需求),如果li中有值在count中,定义count[index]计数+1
清空li
枚举count,把计算添加进li
'''
def countSort(li):
count = [0 for i in range(11)]
for index in li:
count[index] += 1
li.clear()
for index, val in enumerate(count):
print(index, val)
for i in range(val):
li.append(index)
li = [10,4,6,3,8,4,5,7]
countSort(li)
print(li)
li = [random.randint(1,100) for _ in range(10000)]
BubbleSort(li)
li = [random.randint(1,100) for _ in range(10000)]
selectSort(li)
li = [random.randint(1,100) for _ in range(10000)]
insertSort(li)
li = [random.randint(1,100) for _ in range(100000)]
print(li)
quickSort(li, 0, len(li)-1)
print(li)
现在有n个数(n>10000),设计算法,按大小顺序得到前10大的数。
'''
现在有n个数(n>10000),设计算法,按大小顺序得到前10大的数。
应用场景:榜单TOP 10
解析:
因为只要最大的十个数,所以没有必要将整个数据进行排序,因为剩下的数据是否有序不影响结果。
所以可以新建一个数量为10的数组,并将这个数组进行排序,使其有序。
然后从第11位开始取数据,拿取到的数据和十位的列表中的最小的那个做比较,如果不够大就继续循环取数,如果比最小的数大,就把取出的数据覆盖掉最小的数,并再对十位的数组排序。直至数据取完,十位数组里面储存的就是最大的十个数字。
按照这个思路可以用插入排序或者堆排序实现,下面用的是插入排序。
'''
# 将一个数组按照左大右小顺序排好
def inser_sort(list):
for i in range(1, len(list)):
tem = list[i]
j = i - 1
while j >= 0 and list[j] < tem:
list[j + 1] = list[j]
j = j - 1
list[j + 1] = tem
def topk(li, k):
list = li[0:k] # 创建一个长度为k的数组来储存最大的k个数
inser_sort(list) # 将这个K数组先按照大小顺序用插入偶排序排好
print(list)
print(list[-1])
for i in range(k, len(li)): # 将剩下的数字依次拿到
# 将拿到的数字和数组中最小的数字做对比
if li[i] > list[-1]: # 如果比最小的数字大,就做交换,把最小的数字换成取到的数
list[-1] = li[i]
# 交换之后进行排序
inser_sort(list)
print(list)
给定一个列表和一个整数,找到两个数的下标,使得这两个数的各为给定的整数,保证肯定仅有一个结果
'''
算法例子一:
给定一个列表和一个整数,找到两个数的下标,
使得这两个数的各为给定的整数,保证肯定仅有一个结果
'''
# 穷举法:
def brute_force(li,target):
n=len(li)
for i in range(0,n):
for j in range(i+1,n):
if li[i]+li[j]==target:
return i,j
# 二分查找法:
def bin_search(li, val):
low = 0
high = len(li) - 1
while low <= high:
mid = (low + high) // 2
if li[mid] == val:
return mid
elif li[mid] > val:
high = mid - 1
else:
low = mid + 1
return None
def search_index(li, target):
li.sort()
for i in range(0, len(li)):
j=bin_search(li[i + 1:], target - li[i])
if j:
return i,j
'''
方法三
先给列表排序,然后循环遍历列表,如果列表第一个数与列表最后一个数相加的和大于target,把被加数向左偏移一位,
如果列表第一个数与列表最后一个数相加的和小于target,把加数向右偏移一位
如果列表中两个数相加等于target,则返回列表中的两个数的下标
'''
def search_index(li,target):
li.sort()
j=len(li)-1
for i in range(j):
if li[i] + li[j] < target:
i += 1
elif li[i] + li[j] > target:
j -=1
else:
return i,j
给定一个升序列表和一个整数,返回该整数在列表中的下标范围
'''
算法例子二:给定一个升序列表和一个整数,返回该整数在列表中的下标范围
思路:先使用二分法找到val在列表中的下标,然后把下标分别向左和向中移动,直到下标的值不等于目标整数时返回下标的元组
'''
def bin_search(li,val):
low=0
high=len(li)-1
while low <= high:
mid=(low + high) // 2
if li[mid] == val:
return mid
elif li[mid] > val:
high = mid -1
else:
low=mid + 1
return None
def search_index(li,val):
i=0
j=0
mid=bin_search(li,val)
i=mid-1
j=mid + 1
while li[i] ==val:
i -= 1
while li[j] == val:
j += 1
return (i+1,j-1)
two_sum求两数之和
# two_sum求两数之和
# 给定一个列表和一个整数,设计算法找到两个数的下标,使得两个数之和为给定的整数,保证肯定仅有一个结果.
# 例:列表li=[0, 1, 2, 3, 4, 5, 6]与目标整数6,结果为{0: 6, 1: 5, 2: 4, 3: 3}.
li = [0, 1, 2, 3, 4, 5, 6]
# 解法1:
def two_sum_1(li, target):
for i in range(len(li)):
for j in range(i + 1, len(li)):
if li[i] + li[j] == target:
return i, j
print(two_sum_1(li, 6))
# 解法2
def two_sum_2(li, target):
d = {}
for i in range(len(li)):
b = target - li[i]
if b in d:
return d[b], i
else:
d[li[i]] = i
print(two_sum_2(li, 6))
# 解法3
# 结合二分查找法,可以找到所有的可能组合.
# 缺点:提供的列表必须是有序的,否则这个办法没有作用.
class Solution:
# 二分查找法
def binary_search(self, li, val, start, end):
while start <= end:
mid = (start + end) // 2
if li[mid] < val:
start = mid + 1
elif li[mid] > val:
end = mid - 1
else:
return mid
else:
return None
# 给定一个列表和一个整数,设计算法找到两个数的下标,使得两个数之和为给定的整数.
def two_sum3(self, li, target):
dic = {}
for i in range(len(li)):
a = li[i]
b = target - a
# 写0时,{0: 6, 1: 5, 2: 4, 3: 3, 4: 2, 5: 1, 6: 0}
# 写i时,{0: 6, 1: 5, 2: 4, 3: 3}
# 写i+1时,{0: 6, 1: 5, 2: 4}
res = self.binary_search(li, b, i, len(li) - 1)
if res != None:
dic[i] = res
return dic
# 实例化对象
s = Solution()
# 调用类方法
print(s.two_sum3(li, 6))
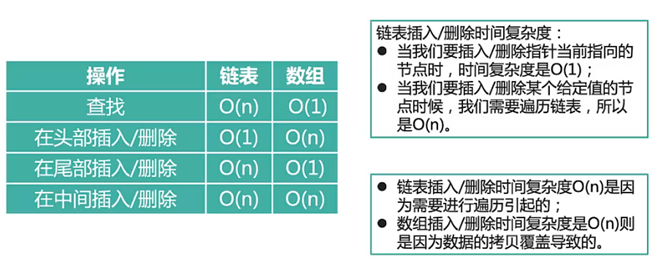
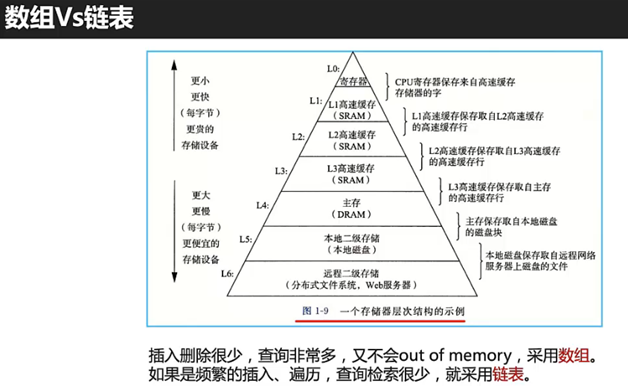
数组和链表
数组:就像在app上看连续几,可以自选哪一集观看
链表:就像电视台播放连续剧,只能等一集一集的播放.
线性表

顺序表
数组
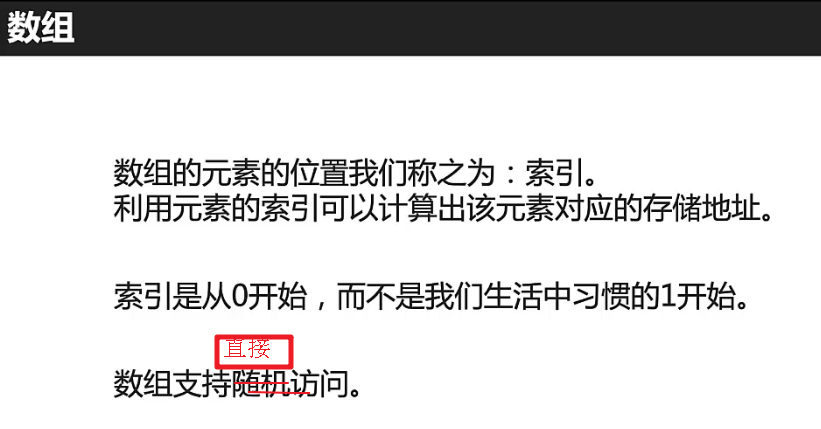
引用数组
动态数组

链表
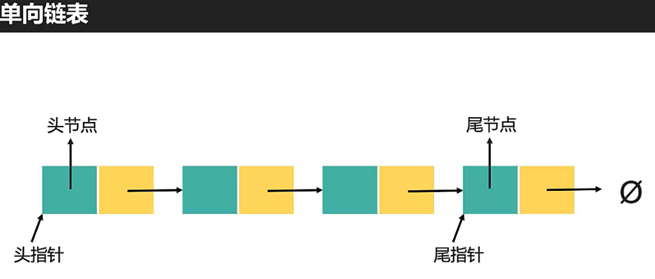
单向链表
双向链表

插入:创建新节点-next指针设置为空-头/尾指针指向新节点
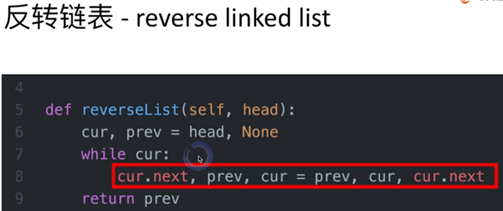
反转链表
链表交换相邻元素

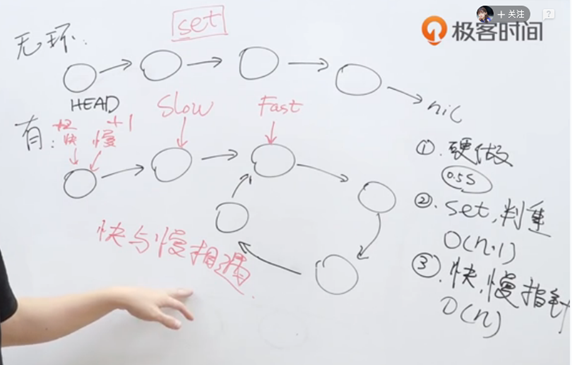
探测环

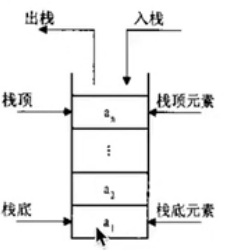
栈,队列:都是线性的容器
堆栈stack: 先进后出
入栈 # q.append('first')
出栈 # print(q.pop(-1))
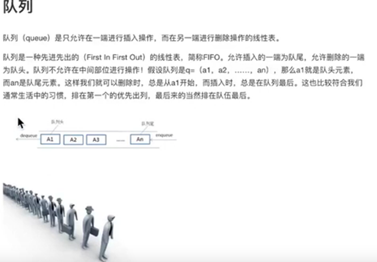
队列queue: 先进先出
入队 # q.append('first')
出队 # print(q.pop(0))

string判断,{[()]}是否完整


用堆栈实现队列
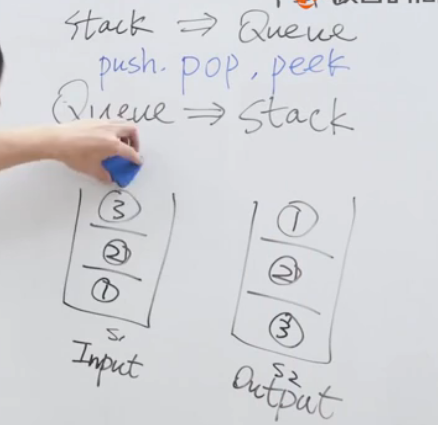
实时判断数据流中第K大元素


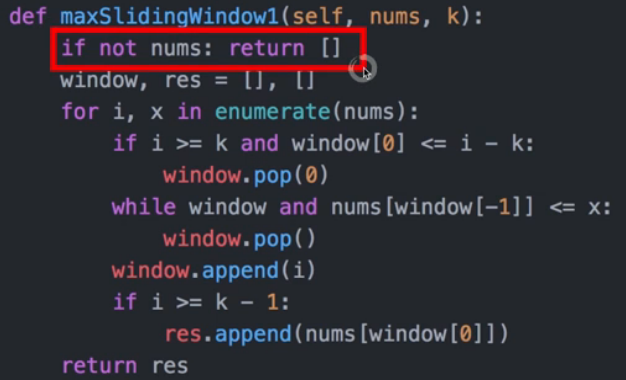
滑动窗口最大值


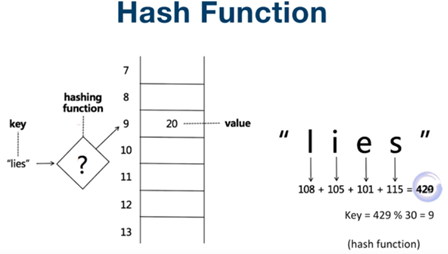
map vs set, hash
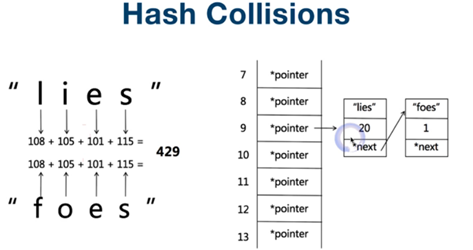
hash碰撞:放列表(拉链法)

有效的字母异位词


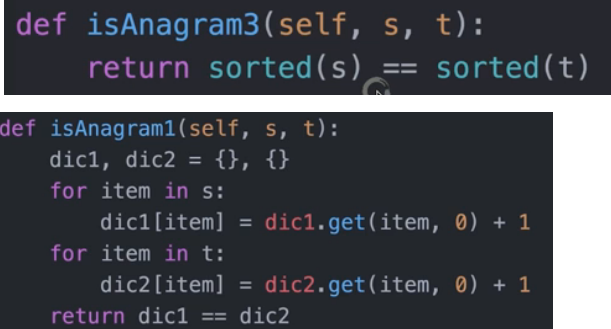
两数之和


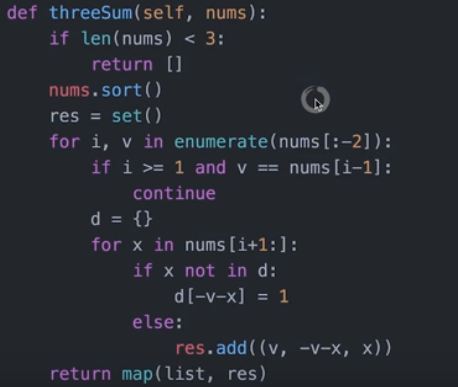
三数之和


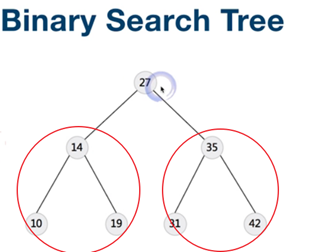
树,二叉树,二叉搜索树
二叉树:每个节点只有两个孩子

图
二叉搜索树

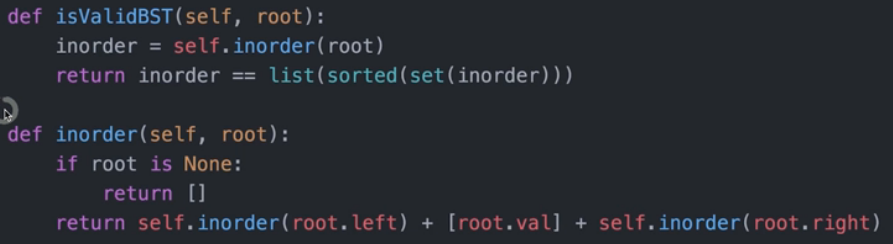
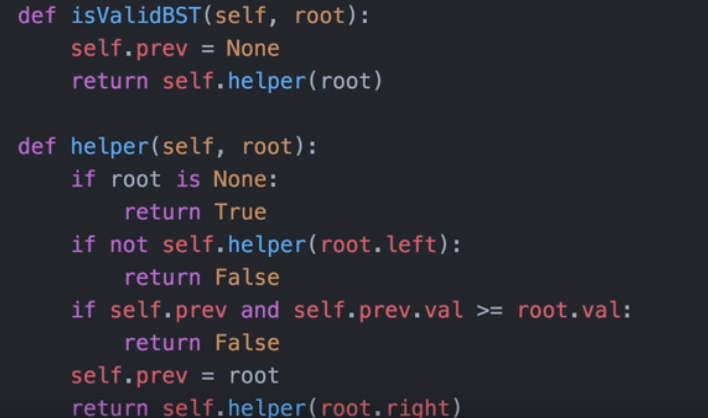
验证二叉搜索树


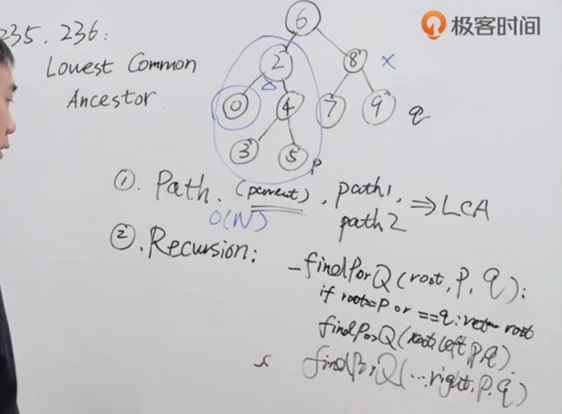
二叉树搜索树的最近公共祖先


二叉树的遍历

算法
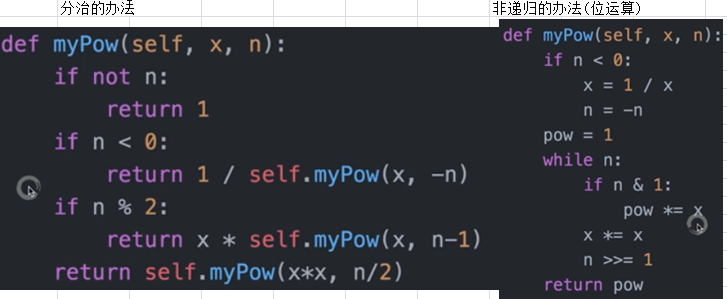
递归Recursion和分治

Pow(x,n)

求众数

贪心算法greedy

36元最少需要多少张纸币


买卖股票的最佳时机


广度优先搜索BFS
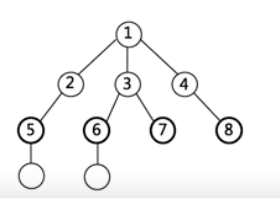
深度优先搜索DFS
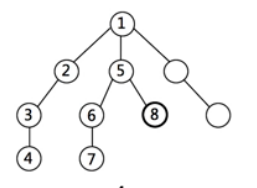
二叉树的层次遍历

