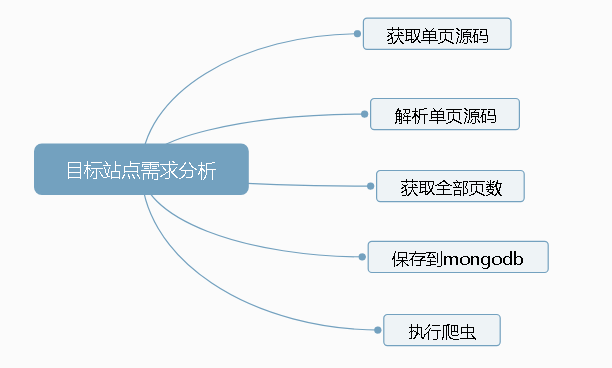
目标站点需求分析
涉及的库
import requests
import time
import pymongo
from lxml import etree
from requests.exceptions import RequestException
获取单页源码
def get_one_page(page):
'''获取单页源码'''
try:
url = "http://sh.ziroom.com/z/nl/z2.html?p=" + str(page)
print('url',url)
headers = {
'Referer':'http://sh.ziroom.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
res = requests.get(url,headers=headers)
time.sleep(1)
if res.status_code == 200:
return res.text
return None
except RequestException:
return None
解析单页源码
def parse_one_page(sourcehtml):
'''解析单页源码'''
contentTree = etree.HTML(sourcehtml) #解析源代码
results = contentTree.xpath('//ul[@id="houseList"]/li') #利用XPath提取相应内容
for result in results:
title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 0 else ""
area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接
nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else ""
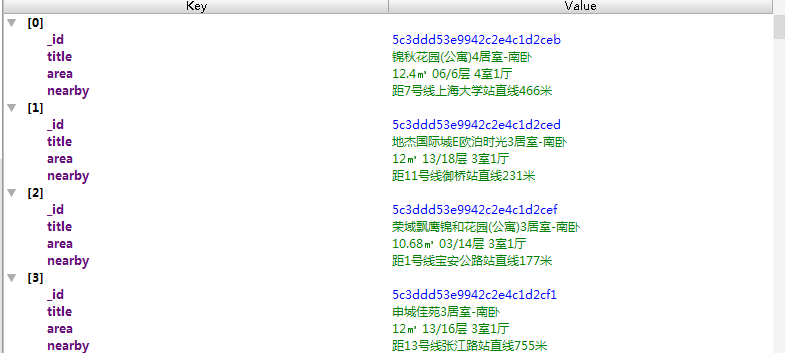
data = {
"title": title,
"area": area,
"nearby": nearby
}
print(data)
save_to_mongodb(data)
抓取总页数,保存到Mongobd中
def get_pages():
"""得到总页数"""
page = 1
html = get_one_page(page)
contentTree = etree.HTML(html)
pages = int(contentTree.xpath('//div[@class="pages"]/span[2]/text()')[0].strip("共页"))
return pages
def save_to_mongodb(result):
"""存储到MongoDB中"""
# 创建数据库连接对象, 即连接到本地
client = pymongo.MongoClient(host="localhost")
# 指定数据库,这里指定ziroom和表名
db = client.iroomz
db_table = db.roominfo
try:
#插入到数据库
if db_table.insert(result):
print("抓取成功",result)
except Exception as reason:
print("抓取失败",reason)
def task():
pages = get_pages()
print('总共',pages)
for page in range(1,int(pages)+1):
html = get_one_page(page)
parse_one_page(html)