一、前言
ThreadLocal这个对象就是为多线程而生的,没有了多线程ThreadLocal就没有存在的必要了。可以将任何你想在每个线程独享的对象放置其中,并在任何时候取出来。
二、基本用法
ThreadLocal的使用方法其实特别简单:
- 在某个类(相当于工厂类,因为当获取不到的时候你要创建一个给它)中创建静态的ThreadLocal。
- 在别的地方调用它的set和get方法用来存放对象。
下面展示一个样例:

package yiwangzhibujian;
public class ThreadLocalUse{
//创建一个静态的ThreadLocal对象,当做仓库,存储每个线程自己的资源
//此处用Object来代替,可以使连接Connection
private static ThreadLocal<Object> store=new ThreadLocal<Object>();
//当每个线程要获取一个线程资源的时候,调用get方法
public Object get(){
//首先去仓库中去寻找
Object obj=store.get();
//如果不存在那就创建一个给线程,并把创建的放到仓库中
if(obj==null){
obj=new Object();
set(obj);
}
return obj;
}
//想将线程资源放到仓库调用set方法,
public void set(Object obj){
store.set(obj);
}
}
这是一个使用模板,可以根据具体情况来做相应改变。
三、ThreadLocal理解
3.1 ThreadLocal会导致内存泄漏吗
首先明确表示使用ThreadLocal不会导致内存泄漏。现在做如下测试证明这个观点,有如下程序:
public class ThreadLocalTest{
//创建一个ThreadLocal用来存储每个线程的对象
private static ThreadLocal<Object> local=new ThreadLocal<Object>();
//一个常量,用来创建10M大小的对象使用
private static final int _1MB=1024*1024;
public static void main(String[] args) throws Exception{
//创建一个Runnable对象
Runnable r=new Runnable(){
@Override
public void run(){
System.out.println("子线程内创建对象并放置ThreadLocal中");
//创建一个10M大小的数组,并将其放到ThreadLocal中
byte[] data=new byte[10*_1MB];
local.set(data);
System.out.println("子线程运行结束,代表线程结束");
}
};
//创建线程并运行
Thread t=new Thread(r);
t.start();
System.out.println("主线程休眠一秒,为了让创建的子线程执行完毕");
Thread.sleep(1000);
System.out.println("休眠完成,主线程准备分配一个10M大小的数组");
byte[] data2=new byte[10*_1MB];
System.out.println("分配数组完毕");
}
}
在程序右键点击Run as->Run Configurations进行虚拟机配置:

配置如下,-XX:+PrintGCDetails(打印垃圾回收日志) -XX:+PrintGCTimeStamps(打印回收时间,可不用) -Xms18M -Xmx18M(设置初始化和最大内存为18M,这么做的目的是,当创建两个10M大小的数组时,会内存溢出还是将ThreadLocal内的进行回收):
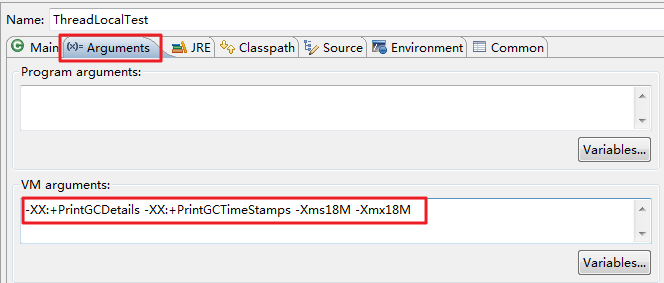
首先介绍这个程序的目的就是创建一个对象放置到ThreadLocal中,看看垃圾回收器会不会在线程结束的时候对其进行回收。运行结果如下:
主线程休眠一秒,为了让创建的子线程执行完毕 子线程内创建对象并放置ThreadLocal中 子线程运行结束,代表线程结束 休眠完成,主线程准备分配一个10M大小的数组 1.102: [GC [PSYoungGen: 376K->224K(5376K)] 10616K->10464K(17664K), 0.0077785 secs] [Times: user=0.03 sys=0.00, real=0.01 secs] 1.110: [GC [PSYoungGen: 224K->224K(5376K)] 10464K->10464K(17664K), 0.0008971 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 1.111: [Full GC [PSYoungGen: 224K->0K(5376K)] [PSOldGen: 10240K->164K(12288K)] 10464K->164K(17664K) [PSPermGen: 3030K->3030K(21248K)], 0.0058052 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 分配数组完毕
可以发现,当主线程准备分配一个10M大小的数组时发现内存不够,会调用垃圾处理器进行回收,通过[PSOldGen: 10240K->164K(12288K)] 可以看出,放入ThreadLocal中的对象被回收了。
3.2 使用全局Map替换ThreadLocal可不可以
我曾经也想过使用全局Map来替换ThreadLocal,即使用如下代码表示展示的样例:
public class ThreadLocalUse{
private static Map<Thread,Object> store=new HashMap<Thread,Object>();
//当每个线程要获取一个线程资源的时候,调用get方法
public Object get(){
//首先去仓库中去寻找
Object obj=store.get(Thread.currentThread());
//如果不存在那就创建一个给线程,并把创建的放到仓库中
if(obj==null){
obj=new Object();
set(obj);
}
return obj;
}
//想将线程资源放到仓库调用set方法,
public void set(Object obj){
store.put(Thread.currentThread(),obj);
}
}
这样也可以做到线程内共享对象,但是有一个致命的缺点,那就是当线程结束后,存储在Map中的对象必须手动清除,否则将会导致内存泄漏。
3.3 对比ThreadLocal和synchronized同步机制
很多人都会对这两个对象进行比对,我也谈一下我自己的想法。
使用synchronized是为了将多条语句进行原子化操作,比说对于递增操作i++,任意一个线程在执行代码时都要保证别的线程不能执行这个代码,否则就会产生脏数据,使用synchronized可以避免这一点。
而使用ThreadLocal就是给每个线程存储对象用的。既然每个线程使用了自己的对象,没有了竞争就不会出现多线程相关的问题。
3.4 我对ThreadLocal的一点点理解
本来呢,我也一直在想ThreadLocal设计的有一点点不合理,比如为什么只能存储一个对象呢,存储多个对象多好呀,或者Thread直接内置一个Map多好,就可以这样操作:
Thread.currentThread().map.put(key,value); Thread.currentThread().map.get(key);