编译器优化机制详解
1 字节码是如何执行的?
主要包含解释执行(由解释器一行一行翻译执行)和编译执行(将字节码编译成机器码,直接执行机器码)。
- 解释执行:优势在于没有编译的等待时间,性能相对编译执行差。
- 编译执行:运行效率高,比解释执行快一个数量级;会带来额外的开销(CPU,内存)
查看和切换运行模式
>java -version
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode) // 混合模式
C:\Users\lizho>java -Xint -version
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, interpreted mode)
-Xint // 解释执行
-Xcomp // 编译模式,不能编译的解释执行
-Xmixed // 混合模式
通常一开始使用解释器解释执行。当虚拟机发现某个方法或者代码块执行频繁时,便判定这些代码为热点代码。为了提高这部分代码的执行效率,会采用即时编译器JIT,将热点代码编译成与本地平台相关的机器码,并进行分层优化。
2 Hotspot即时编译
C1/C2编译器
C1编译器,是客户端编译器,简单快速,主要关注局部的优化。适用于执行时间较短或对启动性能有要求的程序。例如,GUI应用对界面启动速度就有一定要求。
C2编译器,是服务端编译器,主要为长期运行的服务器端应用程序做性能调优,适用于执行时间较长或对峰值性能有要求的程序。
分层编译
Hotspot默认开启分层编译,分层编译分为5层。
- 解释执行
- 简单C1编译:会用C1编译器进行一些简单的优化,不开启 Profiling(JVM监控)。
- 受限的C1编译:仅执行带方法调用次数以及循环回边执行次数Profiling的C1编译
- 完全C1编译:会执行带有所有 Profiling的C1代码
- C2编译∶使用C2编译器进行优化,该级别会启用一些编译耗时较长的优化,一些情况下会根据性能监控信息进行一些非常激进的性能优化
级别越高,应用启动越慢,优化的开销越高,峰值性能也越高。
# 只想开启C2层,只能做到禁用中间编译层(123层)
-XX:-TieredCompilation
# 只想开启C1层,生效0和1层
-XX:-TieredCompilation -XX:TieredStopAtLevel=1
3 JVM如何找到热点代码?
基于采样的热点探测。通过采样,不断探测栈顶,发现哪个方法执行次数多;
基于计数器的热点探测。统计方法的执行次数,由此判断热点方法。Hotspot使用计数器方法。
Hotspot内置两类计数器
方法调用计数器( Invocation Counter)
用于统计方法被调用的次数,在不开启分层编译的情况下,在C1编译器下的默认阈值是1500次,在C2模式下是10000次。也可用-XX: CompileThreshold=X指定阈值。
方法调用计数器默认统计的是一个相对的执行频率,即一段时间之内方法被调用的次数。如果超过时间限度,仍然不满足编译阈值,则计数器减少一半,这个过程称为计数器热度衰减,这段时间称为半衰周期。
-XX:-UseCounterDecay 关闭热度衰减,使计数器统计方法调用的绝对次数。只要时间够长,大多数方法都会编译成本地代码。
-XX:CounterHalfLifeTime 设置半衰周期s。
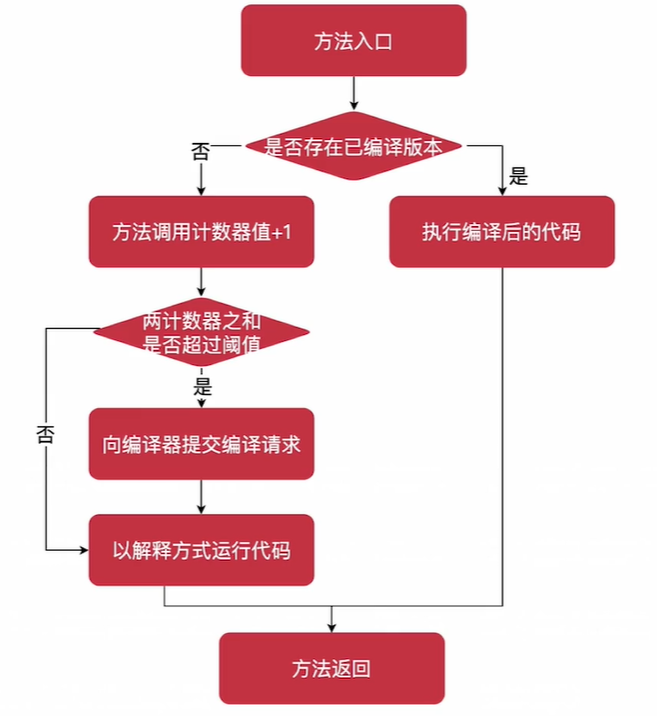
【注意】JVM按照两个计数器之和判断是否需要编译。
回边计数器( Back Edge Counter)
用于统计—个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”( Back Edge)。在不开启分层编译的情况下,C1编译器下的默认阈值13995,C2默认为10700,可使用-XX:OnStackReplacePercentage=X指定阈值
建立回边计数器的主要目的是为了触发OSR(OnStackReplacement栈上替换)编译(介绍略)。回边计数器的流程图跟上图类似,不同的是向编译器发起OSR请求。
当开启了分层编译,JVM会根据当前带编译的方法数以及编译线程数动态调整阈值。上面的两个参数失效。
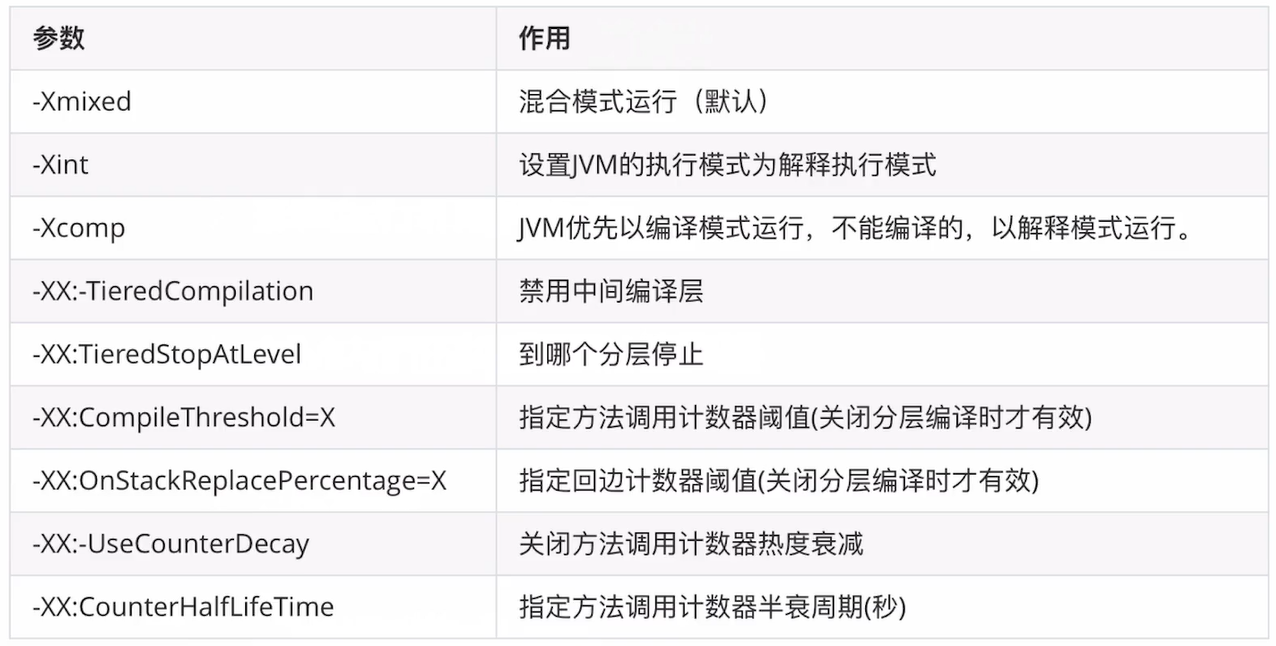
JVM参数小结