之前发过禅道的各种数据统计报表,使用过程中优化了一些,反映最多的是项目bug的解决时长统计问题:
1.比如当天下班左右提交的bug,研发第二天来解决,晚上这段时间应该去掉,不应计算在内
2.节假日、周末这些时间也应该去掉
python有公用模块chinesecalendar可以解决解决第二个问题,不过这个模块有个缺陷,每年需要更新一下,获取当年的节假日,当然你也可以把节假日周末信息存入数据库动态调整获取。
common_workday.py 计算两个时间内的休息日天数
1 ##common_workday.py 2 3 4 # coding = utf-8 5 # 计算周末、节假日时间天数 6 7 from datetime import datetime, timedelta 8 from chinese_calendar import is_workday 9 10 11 def workdays(start, end): 12 """ 13 :param start: 14 :param end: 15 :return: 16 """ 17 # 字符串格式日期的处理 18 if type(start) == str: 19 start = datetime.strptime(start, '%Y-%m-%d').date() 20 if type(end) == str: 21 end = datetime.strptime(end, '%Y-%m-%d').date() 22 # 开始日期大,颠倒开始日期和结束日期 23 if start > end: 24 start, end = end, start 25 counts = 0 26 while True: 27 if start > end: 28 break 29 # 计算两个日期间的节假日和周末数 30 if is_workday(start) is False: 31 counts += 1 32 start += timedelta(days=1) 33 return counts
bug_time_summary.py 统计汇总时间(从数据库查询出数据后直接处理)
## bug_time_summary.py ##*****代码片段*****## mysql_l = deal_mysql(sys._getframe()) if len(mysql_l) > 0: le = [] for i in mysql_l: le.append(list(i)) for i in le: # bug解决时间减去bug提交时间 ta = round(float((i[7] - i[6]).total_seconds() / 3600), 2) # 两个时间之间的周末、节假日天数 tb = float(workday.workdays(i[6].date(), i[7].date()) * 24) hour_sub = 0 if i[6].day != i[7].day and i[6].hour >= 17: # 17点后提交的bug,计算需扣除的跨天小时数【8.5:计算方式自己动态调整,9点上班,考虑有人8点半来就修复bug了,所以取个8.5,提交bug分钟数舍弃计算,影响不大;另外17点之前提交的bug,不排除跨天时间】 hour_sub = 24 - i[6].hour + 8.5 # 最终结果 time_subtract = round(ta - tb - hour_sub, 2) i.append(time_subtract) end = [] name = '' count = 0 avg_time = 0 for index, i in enumerate(le): if index == 0: name = i[5] count = 1 avg_time = i[8] else: if i[5] == name: count += 1 avg_time += i[8] if index == len(le) - 1: end.append([le[index][0], le[index][1], le[index][5], count, round(avg_time / count, 2)]) else: end.append([le[index - 1][0], le[index - 1][1], le[index - 1][5], count, round(avg_time / count, 2)]) name = i[5] count = 1 avg_time = i[8] if index == len(le) - 1: end.append([le[index][0], le[index][1], le[index][5], count, round(avg_time / count, 2)]) sum_p = 0 sum_time = 0 for i in end: sum_p += i[3] sum_time += i[4]*i[3] avn = round(sum_time / sum_p, 2) end = sorted(end, key=lambda x: x[3], reverse=True) data = np.tile(end, 1) d = data.T # 获取列表合并算法 al = dt.find_same_column(d, 1) # td 处理 td = deal_td(al) # tr处理 tr = deal_tr(td) s, h = deal_html(tr, avn) ##*****代码片段*****##
改进前:

改进后:
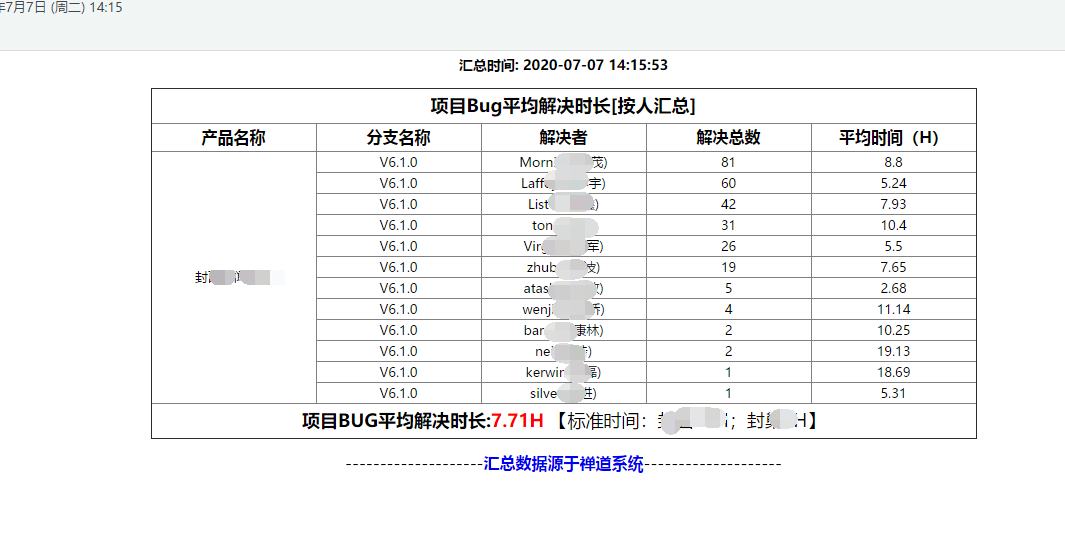
同样的详情表也可以这样处理~~