一.程序(其实我现在也没理解了什么意思,但先记在着,网上其他的也是直接照抄,烦躁)
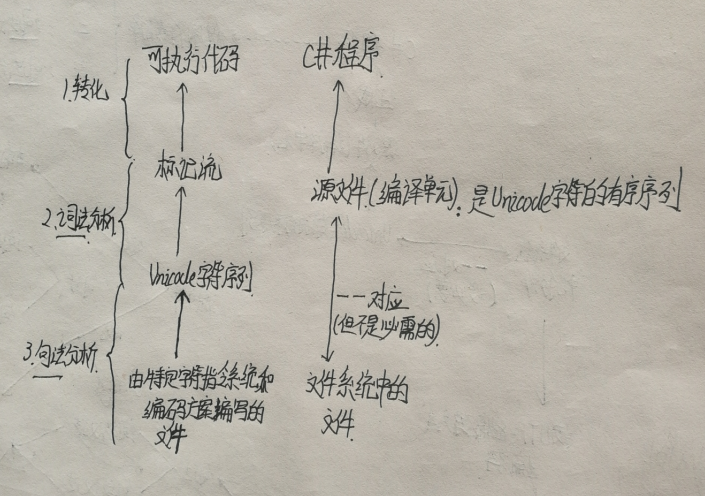
C#程序:由一个/多个源文件(编译单元)组成,源文件是Unicode字符的有序序列;源文件与文件系统中的文件有一一对应关系,但为了获得最大的可移植性,书中推荐文件系统中的文件按照UTF-8编码方式进行编码;
从概念上讲,程序编译分为三个步骤:
1.转化:这一步将特定字符指令系统和编码方案编写的文件转化成Unicode字符序列;
2.词法分析:这一步将Unicode输入字符流转化为标记流;
3.句法分析:这一步将标记流转化为可执行代码。
二.句法中的文法(上面句法分析就是拿着标记流到句法中寻找代码的意思然后执行,我是这么认为的)
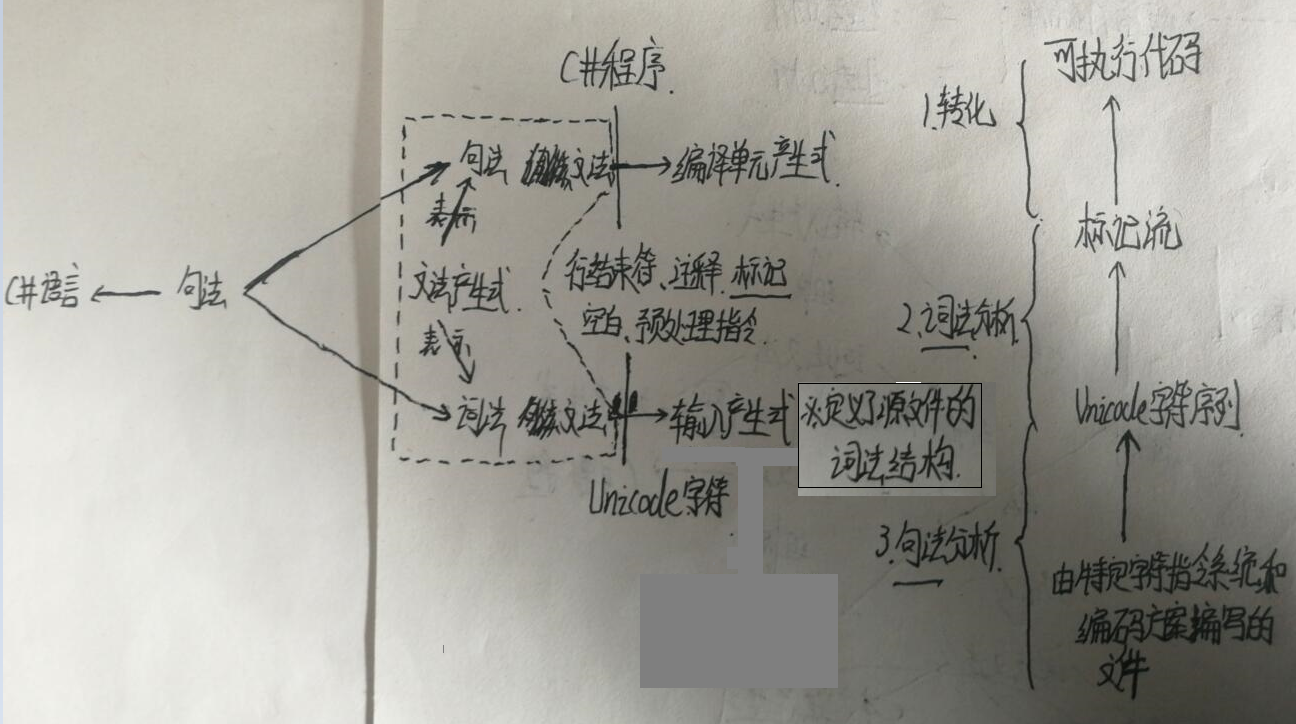
表示C#编程语言的句法有两种文法:词法文法、句法文法。
词法文法:规定怎么将Unicode字符结合起来构成行结束符、空白、注释、标记和预处理指令;C#程序中的每个源文件都必须符合词法文法的输入产生式。
句法文法:规定如何把这些由词法文法产生的标记再结合起来构成C#程序;C#程序中的每个源文件都必须符合句法文法的编译单元产生式。
文法产生式:比如有一本书,这本书是中文写的,中文又是由横、竖、撇、捺等一笔一划组成。我们现在就把编程的句法比作这本书,词法文法、句法文法就像中文,那么横、竖、撇、捺就是文法产生式,即词法和句法文法就是使用文法产生是来表示。每个文法产生式定义一个非结束符号和它可能的扩展(这个扩展可以是非结束符或结束符组成的序列),非结束符显示为斜体,结束符显示为等宽字体。(词法文法的结束符时Unicode字符集中的字符;句法文法的结束符是由词法文法定义的标记)
解释了文法产生式的概念,接着说它的书写格式。第一行是该产生式所定义的非结束符号的名称和一个冒号。后续每缩进一行就包含一个可能的扩展。
while-statement:
while(boolean-expression)embedded-statement
上面两行语句就是简单的文法产生式,while-statement:表示定义一个while语句:;第二行说明它是这样构成的,由标记while开始,后跟标记"("、布尔表达式、")"和嵌入的语句。
当非结束符有多于一个的扩展时,列出来时每个扩展独占一行,比如:
statement-list:
statement
statement-list statement
解释以下上面的语句,定义了一个语言列表statement-listm,它可能由一个语句statement组成,也可能由一个语句列表statement-list和一个语句statement组成。
若有在下方的下表opt则标明是个可选符号,下面两个表达式一样,都是定义了一个块:
block: block
{statement-listopt} {}
{statement-list}
可选项通常出现在单独的一行,但有多个可选项时,那么就用"one of"列于在单一行上的扩展列表之前,下面这个表示实数类型后缀:
reak-type=stffix:onf of
F f D d M m
三.词法分析
刚才说到句法有一句是这么说的:C#程序中的每个源文件都必须符合这个词法文法的输入产生式,这是因为输入产生式定义了C#源文件的词法结构

5个基本元素组成了C#源文件的词法结构:行结束符、空白、注释、标记和预处理指令。这5个基本元素中只有标记在C#程序的句法中至关重要。对C#源文件的词法处理就是将文件缩减成标记序列,该序列就成为句法分析的输入,行结束符、空白和注释可用于分隔标记,预处理指令可导致跳过源文件中的某些节,初次之外词法元素对C#程序的句法结构没有任何影响,接下来我们就挨个说说这五个元素。
1.行结束符:将C#源文件分成多行

某些源代码编辑工具添加了文件尾记号,以使源文件可以被当做合适的结束行序列来查看,为了保持与这些工具的兼容性,可以在C#程序的每个源文件应用以下转换:

2.空白:使用Unicode类Z被定义作为人任何字符(包括空白字符),以及水平制表符、垂直制表符和换页符:

3.注释:C#支持两种形式的注释:单行注释和带分隔符注释。
单行注释以字符"//"开始,并延续到该源文件行的末尾;带分割注释以字符"/*"开始,以"*/"字符结束。(源代码就不截图了)
4.标记:标识符、关键字、文字、运算符和标点。空白和注释不是标记,但它们能充当标记的分隔符。

看着书连着好几页都是定义这些标记的概念,自己琢磨到恶心,没有完全明白,就先不在这里写了,如果有人需要,联系我我把文本板的书给你发过去....突然感觉工程的伟大
5.预处理指令:提供了有条件地忽略源代码某些部分、报告错误和警告条件,以及描绘源代码的不同区域的能力;在C#没有单独的预处理步骤,预处理指令是作为词法分析阶段的一部分来处理。(然后就是巴拉巴拉的各个指令的代码...行路难)