平常我们在浏览器中输入一个网址,随即看到一个页面,这个过程是怎样实现的呢?下面用一幅图来说明:
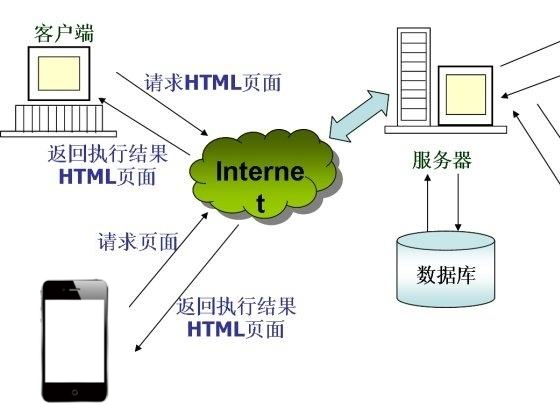
整个流程如下:
1、域名解析
浏览器会解析域名对应的IP地址
PS:DNS服务器的知识
2、建立TCP连接
拿到域名对应的IP地址之后,浏览器会向服务器的WEB程序发起TCP的连接请求。这个连接请求到达服务器端后,进入到网卡,然后是进入到内核的TCP/IP协议栈,最终到达WEB程序,最终建立了TCP/IP的连接。
PS:在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。
3、建立TCP连接后发起http请求
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令。请求是浏览器以格式化文本的形式发送给服务器的,发送请求的文本叫做请求报文,如果说HTTP是因特网的信使,那么HTTP报文就是它用来搬东西的包裹了,所有的HTTP报文都可以分为两类:请求报文和响应报文。请求报文会向Web服务器请求一个动作。响应报文会将请求的结果返回给客户端。
HTTP报文的流动方向:一次HTTP请求,HTTP报文会从“客户端”流到“代理”再流到“服务器”,在服务器工作完成之后,报文又会从“服务器”流到“代理”再流到“客户端”。
4、服务器响应http请求,浏览器得到html代码
服务器会客户机回送应答, HTTP/1.1 200 OK ,应答的第一部分是协议的版本号和应答状态码。服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。 发送结束后,关闭TCP连接。
5、浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
6、浏览器对页面进行渲染呈现给用户
浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。